Target website: https://www.mn52.com/
The code of this article has been uploaded to git and Baidu. The link is shared at the end of the article
Website overview

Target, grab all the pictures using the graph framework and save them locally.
1. Create a sketch project
scrapy startproject images
2. Create a spider
cd images
scrapy genspider mn52 www.mn52.com
After creation, the structure directory is as follows
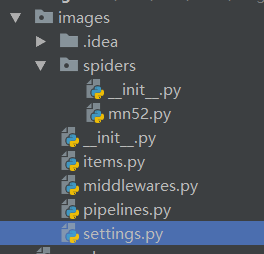
3. Define item definition crawl field
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ImagesItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() image_url = scrapy.Field() field_name = scrapy.Field() detail_name = scrapy.Field()
There are three fields defined here, namely, picture address, picture category name and picture detailed category name
4. Write spider
# -*- coding: utf-8 -*- import scrapy import requests from lxml import etree from images.items import ImagesItem class Mn52Spider(scrapy.Spider): name = 'mn52' # allowed_domains = ['www.mn52.com'] # start_urls = ['http://www.mn52.com/'] def start_requests(self): response = requests.get('https://www.mn52.com/') result = etree.HTML(response.text) li_lists = result.xpath('//*[@id="bs-example-navbar-collapse-2"]/div/ul/li') for li in li_lists: url = li.xpath('./a/@href')[0] field_name = li.xpath('./a/text()')[0] print('https://www.mn52.com' + url,field_name) yield scrapy.Request('https://www.mn52.com' + url,meta={'field_name':field_name},callback=self.parse) def parse(self, response): field_name = response.meta['field_name'] div_lists = response.xpath('/html/body/section/div/div[1]/div[2]/div') for div_list in div_lists: detail_urls = div_list.xpath('./div/a/@href').extract_first() detail_name = div_list.xpath('./div/a/@title').extract_first() yield scrapy.Request(url='https:' + detail_urls,callback=self.get_image,meta={'detail_name':detail_name,'field_name':field_name}) url_lists = response.xpath('/html/body/section/div/div[3]/div/div/nav/ul/li') for url_list in url_lists: next_url = url_list.xpath('./a/@href').extract_first() if next_url: yield scrapy.Request(url='https:' + next_url,callback=self.parse,meta=response.meta) def get_image(self,response): field_name = response.meta['field_name'] image_urls = response.xpath('//*[@id="originalpic"]/img/@src').extract() for image_url in image_urls: item = ImagesItem() item['image_url'] = 'https:' + image_url item['field_name'] = field_name item['detail_name'] = response.meta['detail_name'] # print(item['image_url'],item['field_name'],item['detail_name']) yield item
Logic idea: Rewrite start_requests in the spider to obtain the starting route. Here, the starting route is set as the address of the first level classification of pictures, such as sexy beauty, pure beauty, cute pictures, etc. use the requests library to request mn52.com to analyze and obtain. Then the url and the first level classification name are passed to parse. In parse, the second level classification address and the second level classification name of the acquired image are parsed, and whether the next page information is included is determined. Here, the principle of automatic de duplication is used in the framework of the scratch, so no more de duplication logic is needed. The acquired data is passed to get image, the image route is parsed in get image, assigned to the item field and then yield item
5. Downloading pictures of pipelines
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import scrapy import os # Import scrapy Special pipeline file for image processing of pipeline file in frame from scrapy.pipelines.images import ImagesPipeline # Import picture path name from images.settings import IMAGES_STORE as images_store class Image_down(ImagesPipeline): def get_media_requests(self, item, info): yield scrapy.Request(url=item['image_url']) def item_completed(self, results, item, info): print(results) image_url = item['image_url'] image_name = image_url.split('/')[-1] old_name_list = [x['path'] for t, x in results if t] # Storage path of real original pictures old_name = images_store + old_name_list[0] image_path = images_store + item['field_name'] + '/' + item['detail_name'] + '/' # Determine whether the directory where the pictures are stored exists if not os.path.exists(image_path): # Create the corresponding table of contents according to the current page number os.makedirs(image_path) # New name new_name = image_path + image_name # rename os.rename(old_name, new_name) return item
Analysis: the built-in ImagesPipeline of the summary generates the md5 encrypted image name by itself. Here, the os module is imported to download the image to the customized folder and name. The ImagesPipeline class needs to be inherited.
6. Set the required parameters in settings (part)
#USER_AGENT = 'images (+http://www.yourdomain.com)' USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36' #Specify to output certain log information LOG_LEVEL = 'ERROR' #Store the log information in the specified file, not output at the terminal LOG_FILE = 'log.txt' # Obey robots.txt rules ROBOTSTXT_OBEY = False IMAGES_STORE = './mn52/' ITEM_PIPELINES = { # 'images.pipelines.ImagesPipeline': 300, 'images.pipelines.Image_down': 301, }
Note: the settings mainly define the storage path of the picture, user agent information, and open the download pipeline.
7. Create crawl.py file and run the crawler
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # mn52 Reptile name process.crawl('mn52') process.start()
The cmdline method is not used to run the program here, because the following packaging problems are involved, so the cmdline method cannot be used for packaging.
8. At this point, the crawler has been written. Right click the crawler file to start the crawler, and the picture will be downloaded.
Console output: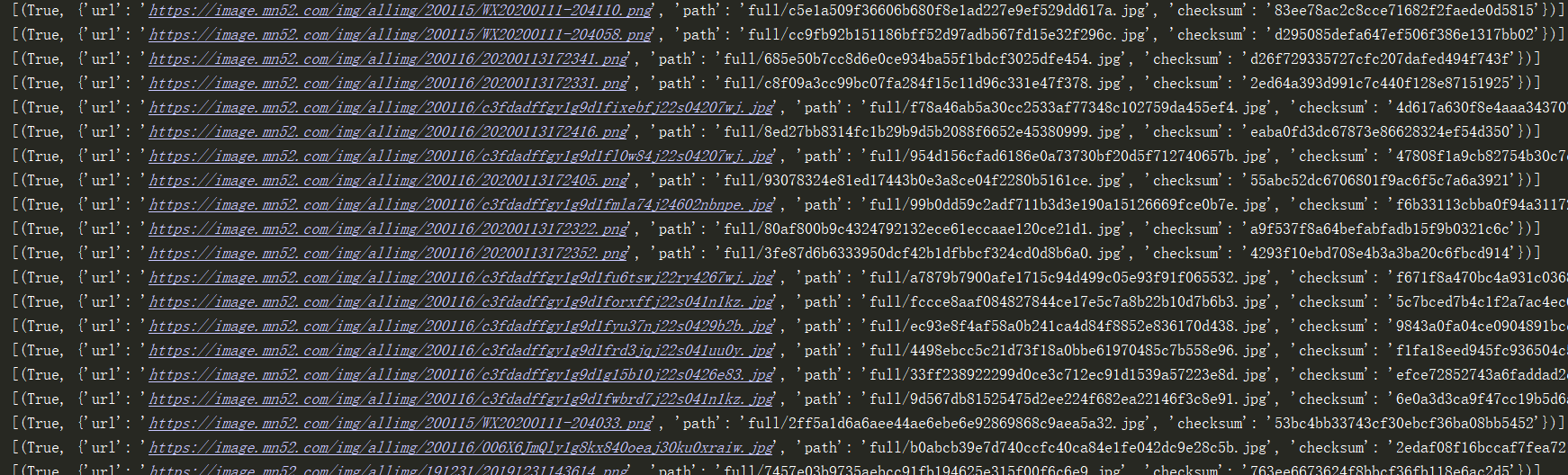
Open folder to view pictures
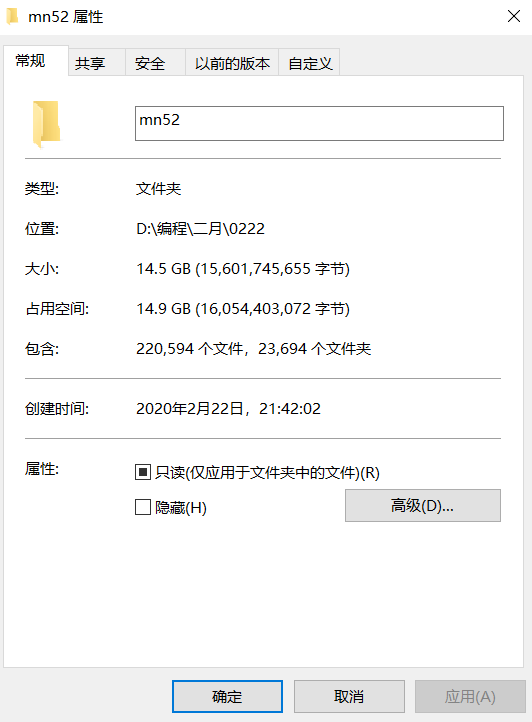
There are about 220000 pictures after downloading
9. Package the crawler.
As a framework crawler, the scratch crawler can also be packaged into an exe file. Isn't it amazing/ A kind of
Packaging steps:
1> In your python installation directory, find the copy of mime.types and VERSION files from scratch to the project directory. The general path is as follows
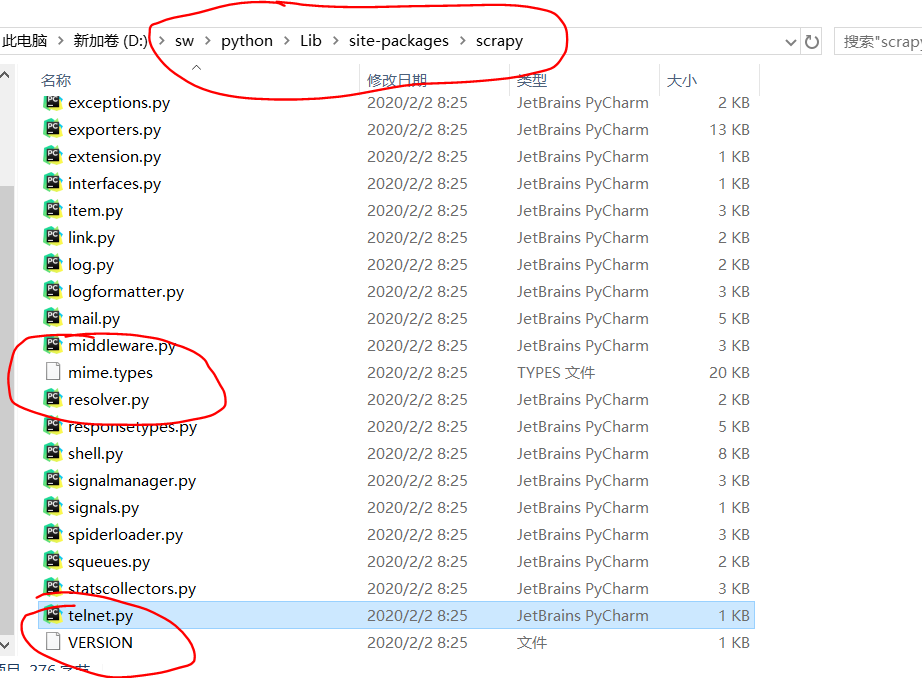
2 > under the project, create the generate ﹣ cfg.py file to generate the summary.cfg
data = ''' [settings] default = images.settings [deploy] # url = http://localhost:6800/ project = images ''' with open('scrapy.cfg', 'w') as f: f.write(data)
After completion, the project structure is as follows
3> The library needed to introduce the project in the crawle.py file
import scrapy.spiderloader import scrapy.statscollectors import scrapy.logformatter import scrapy.dupefilters import scrapy.squeues import scrapy.extensions.spiderstate import scrapy.extensions.corestats import scrapy.extensions.telnet import scrapy.extensions.logstats import scrapy.extensions.memusage import scrapy.extensions.memdebug import scrapy.extensions.feedexport import scrapy.extensions.closespider import scrapy.extensions.debug import scrapy.extensions.httpcache import scrapy.extensions.statsmailer import scrapy.extensions.throttle import scrapy.core.scheduler import scrapy.core.engine import scrapy.core.scraper import scrapy.core.spidermw import scrapy.core.downloader import scrapy.downloadermiddlewares.stats import scrapy.downloadermiddlewares.httpcache import scrapy.downloadermiddlewares.cookies import scrapy.downloadermiddlewares.useragent import scrapy.downloadermiddlewares.httpproxy import scrapy.downloadermiddlewares.ajaxcrawl import scrapy.downloadermiddlewares.chunked import scrapy.downloadermiddlewares.decompression import scrapy.downloadermiddlewares.defaultheaders import scrapy.downloadermiddlewares.downloadtimeout import scrapy.downloadermiddlewares.httpauth import scrapy.downloadermiddlewares.httpcompression import scrapy.downloadermiddlewares.redirect import scrapy.downloadermiddlewares.retry import scrapy.downloadermiddlewares.robotstxt import os import scrapy.spidermiddlewares.depth import scrapy.spidermiddlewares.httperror import scrapy.spidermiddlewares.offsite import scrapy.spidermiddlewares.referer import scrapy.spidermiddlewares.urllength from scrapy.pipelines.images import ImagesPipeline import scrapy.pipelines from images.settings import IMAGES_STORE as images_store import scrapy.core.downloader.handlers.http import scrapy.core.downloader.contextfactory import requests from lxml import etree from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # mn52 Reptile name process.crawl('mn52') process.start()
10. Use the pyinstaller third-party packaging library to package
Use pip if not installed
pip install pyinstaller
Using the pack and go command under a project
pyinstaller -F --add-data=mime.types;scrapy --add-data=VERSION;scrapy --add-data=images/*py;images --add-data=images/spiders/*.py;images/spiders --runtime-hook=generate_cfg.py crawl.py
Four -- add data commands and one -- runtime hook command are used
The first -- add data is used for mime.types file, which is added and placed in the scratch folder in the temporary folder,
The second is used to add the VERSION file, which is the same as mime.types
The third code is used to add a story - all py files in the images folder, * represents wildcards
The fourth code to add the scratch -- all py files in mn52 folder
--Runtime hook is used to add running hooks, that is, the generate ﹣ cfg.py file here
After the command is executed, an executable file is generated in the dist folder. Double click the executable file to generate the summary CFG deployment file and mn52 picture folder in the same path. There is no problem in the operation

Code address git: https://github.com/terroristhouse/crawler
exe executable address (no python environment required):
Link: https://pan.baidu.com/s/19tkedy9ehmsfpudojrzw
Extraction code: 8ell
python Tutorial Series:
Link: https://pan.baidu.com/s/10eUCb1tD9GPuua5h_ERjHA
Extraction code: h0td