Using Python requests library to crawl educational administration system
When I was a sophomore, I felt that the school's educational administration system was particularly backward. It was very troublesome to use the functions of score query and schedule check. At that time, the official account of the school was especially unstable, so there was a self - made idea. The content of this blog is a summary of my own experience in the process of exploration. If there are any mistakes, please correct them.
To achieve crawling educational content, one of the problems must be solved is how to log in. Our school educational administration system must be accessed through off campus vpn, so we need to solve the problem of twice login.
E-rui authorized access system login
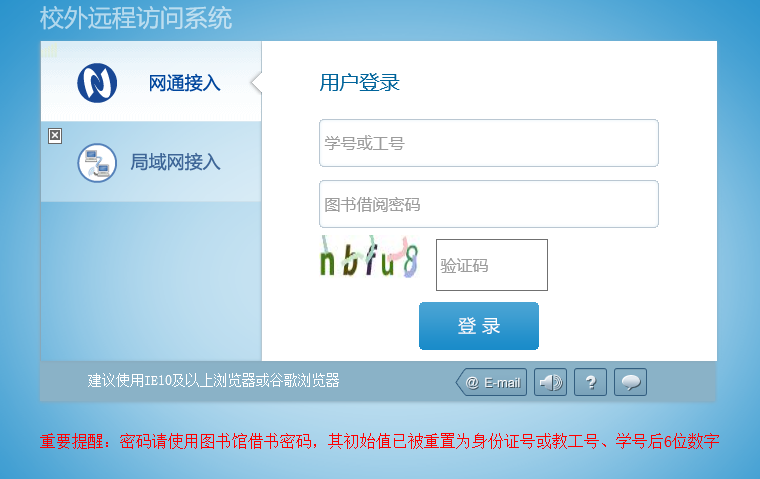
Our school uses the e-rui authorized access system. At the beginning, the login does not require a verification code. Later, the school resets all accounts and adds a verification code, which has become the most headache.
Verification Code
The solution is to first find the url of the verification code, first request the verification code, and then save the cookie when the verification code is requested. After entering the verification code, carry the request header, the request body and the cookie returned when the verification code is requested to log in again to complete the login. However, we can also use the session in requests.
First, check the request information about the verification code through the F12 developer tool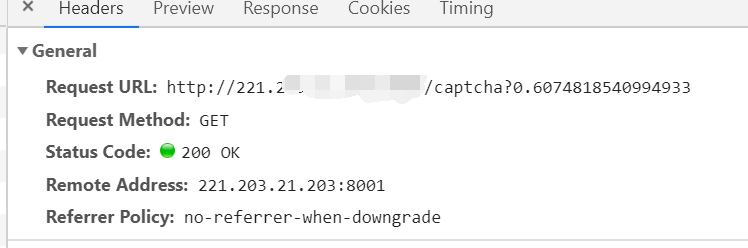
We can see the url of the verification code request, and then we try to request
import requests from PIL import Image session = requests.session() imgurl = 'http://221.203.21.203:8001/captcha' img = session.get(imgurl) #Use PIL library to read verification code and display with open('captcha.png', 'wb') as f: f.write(img.content) img = Image.open("captcha.png") img.show()
After running, the verification code is displayed successfully, and you can log in next step
Sign in
Check the url and data of login submission through F12 developer tool.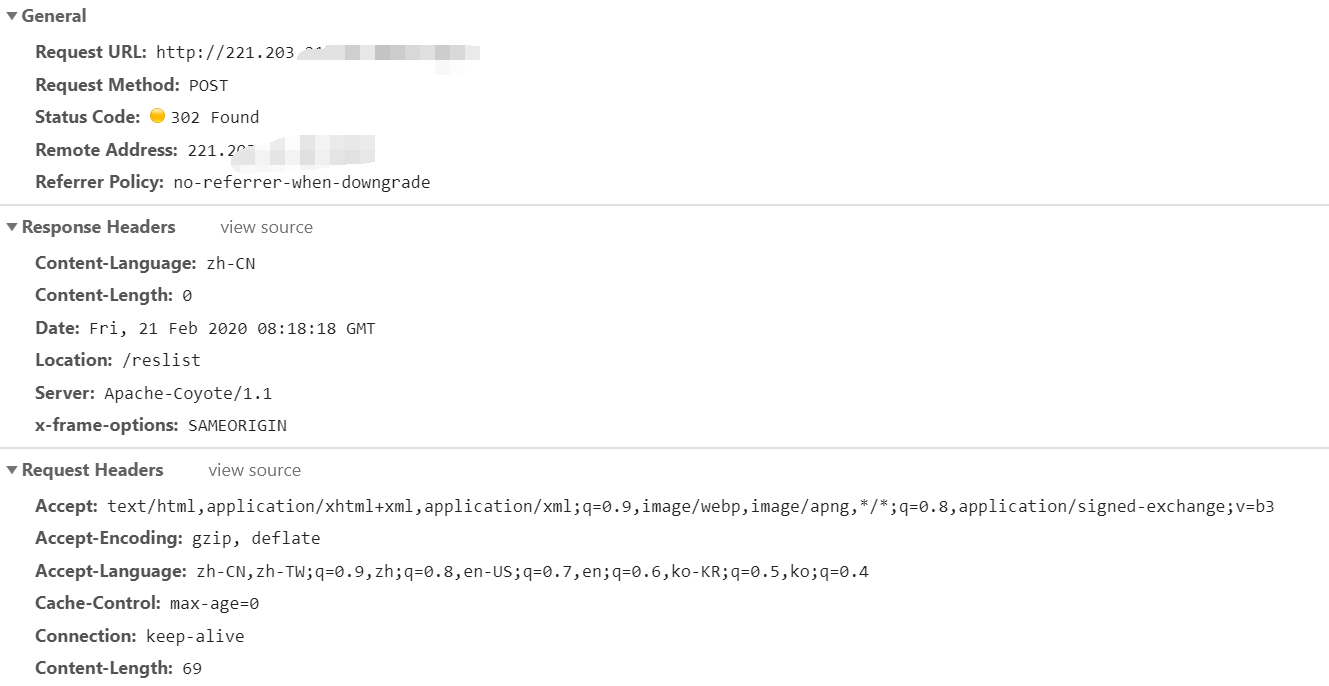
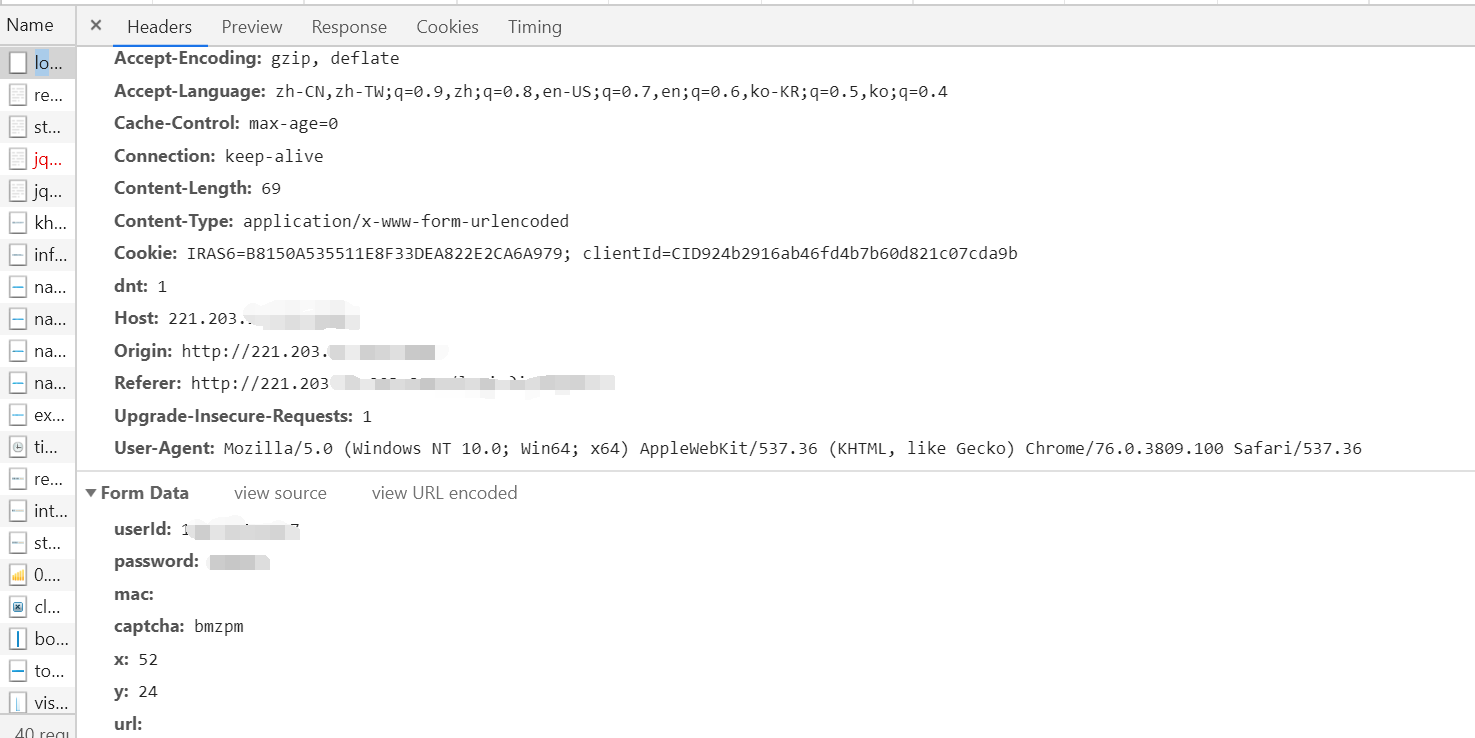
Here we can see the information of the corresponding header response body of the login request header request body, and analyze that the request url in the figure above is the address of our data to be submitted, as well as the data to be submitted, formdata.
Let's solve this part of the code first
header = { 'Content-Type': 'application/x-www-form-urlencoded', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)' } captcha = input('Verification Code:') #Get input from keyboard paylosd = { 'userId':xxxxxxxx, #Student ID 'password':xxxxxxx, #Password 'captcha':xxxxx, #Verification code entered 'x':52, 'y':25 } url = 'http://xxx.xxx.xxx.xxx' session.post(url,headers = header,data = payload) res = session.get('http://xxx.xxx.xxx.xxx:8080/reslist')#Only after login can the jump succeed print(res.text)#Output the source code of the web page to see if the login is successful
Request a url that can jump successfully after login, and output the source code to verify whether the login is successful.
Combine the above two pieces of code and run them
urp integrated educational administration system login
With the experience just now, it will be much easier next. The solution is basically the same. First, request the verification code, input the verification code, construct the request header and request body, and then post to the corresponding url to complete the login. The corresponding request first-class information can be analyzed by the developer tool in the browser, which will not be repeated.
The reference code is as follows
import requests from PIL import Image try: session = requests.session() url = 'http://xxx.xxx.xxx.xxx/captcha' img = session.get(url) cookies = requests.utils.dict_from_cookiejar(session.cookies) #Take out the cookie in the session # Use PIL library to read verification code and display with open('captcha.png', 'wb') as f: f.write(img.content) img = Image.open("captcha.png") img.show() img.close() captcha = input('Verification Code:') header = { 'Content-Type': 'application/x-www-form-urlencoded', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)' } payload = { 'userId': 'xxxxxxx', 'password': 'xxxxxxx', 'captcha': captcha, 'x': 52, 'y': 25 } url = 'http://xxx.xxx.xxx.xxx/login' session.post(url, headers=header, data=payload) imgurl = 'http://xxx.xxx.xxx.xxx/validateCodeAction.do' img = session.get(imgurl,cookies=cookies) # Use PIL library to read verification code and display with open('captcha.jpg', 'wb') as f: f.write(img.content) img = Image.open("captcha.jpg") img.show() header = { 'Connection': 'keep-alive', 'Origin': 'http://xxx.xxx.xxx.xxx', 'Content-Type': 'application/x-www-form-urlencoded', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', 'Referer': 'http://xxx.xxx.xxx.xxx/' } yzm = input('Verification Code:') # Get input from keyboard url = 'http://xxx.xxx.xxx.xxx/loginAction.do' payload = { 'zjh': "xxxxxxxx", # Student ID 'mm': "xxxxxxx", # Password 'v_yzm': yzm # Verification Code } # Sign in res = session.post(url, headers=header, data=payload,cookies=cookies) print(res.text) session.get('http://xxx.xxx.xxx.xxx/logout') # Internet access logout except Exception as e: print(e) session.get('http://xxx.xxx.xxx.xxx/logout') # Internet access logout
When I used session to log in, I found that the educational administration system could not log in. At first, I thought it was a problem of request header, but I tried several times later and still couldn't log in. Later, I found a problem when I used requests + cookies to log in. When I accessed the login request verification code on the Internet, the cookie was the IRAS6 field, When the Internet access is successfully logged in, it becomes two fields: IRAS6 and clientId. When I log in to the educational administration system with IRAS6 as the cookie, I can log in successfully. When I log in with IRAS6 and clientId as the cookie, I fail. This is different from what I saw in the process of bag grabbing, which is what I don't understand.
In addition, due to the limitation of our school's Internet access system, each account can be logged in at most twice without logging out. So I added a logout request and made exception handling to ensure that the account will not be restricted when I make multiple requests.
epilogue
Of course, the above code is just the first demo. Later, I adjusted this code and built a crawler server with Django framework to serve the applet. After that, I will continue to update some of my experiences and problems in using Django as the server.
If you have any questions or want to communicate, you can join my qq group 892367693 to learn and improve together.
If there are mistakes in this article, you are welcome to criticize and correct!

