Blog Outline:
1) grep command
2) cut command
3) sort command
4) uniq commands
5) tee command
6) diff command
7) paste command
8) tr command
Note: Neither of the following tools will modify the source file, only output the results!
1) grep command
grep is a powerful text search tool that uses regular expressions to search for text and print matching lines.
Common options:
-i: ignore case; -v: reverse search; -w: Find exactly; -o: Only matching keywords will be output; -c: count the number of matches; -n: Display line number; -r: traverse the directory one by one to find it; -A: Show the matching rows and how many rows follow; -B: Display matching rows and how many preceding rows; -C: Show how many lines before and after the matching row; -l: List only matching file names; -L: List mismatched file names; -e: use regular matching; -E: Use extended regular matching; ^key: lines starting with key; Key$: line ending with key; ^$: Match empty lines; --color=auto: color the part of the keyword found;
2) cut command
cut is a column intercept tool used to intercept columns.
Common options:
-b: Show only the contents of the specified direct range in the row; -c: divide and intercept characters; -d: Specify the delimiter for the field, and the default delimiter is "TAB"; -f: Specify the area to be intercepted, used with-d;
Give an example:
# cut -d: -f1 1.txt #Intercept column 1, separated by a':'colon # cut -d: -f1,6,7 1.txt #Separate by a colon and intercept columns 1, 6, and 7 # cut -c4 1.txt #Intercepts the fourth character of each line in the file # cut -c4-10 1.txt #Intercept 4-10 characters per line in a file # cut -c4- 1.txt #Intercept all subsequent characters from the fourth character
3) sort command
sort is mainly used for sorting. It takes each line of a file as a unit, compares them by ASCII code values from the first character to the back, and outputs them in ascending order from the left.
Common options:
-u: Remove duplicate rows (whether continuous or not); -r: descending, ascending by default; -o: output the sorted result to a file, similar to the one based on the redirection symbol'>'; -n: sorted by number, by default by character; -t: delimiter; -k: Specify the number that represents the column; -b: Ignore leading spaces; -R: Random sorting with different results per run;
Give an example:
# sort -n -t: -k3 123.txt #Colon-separated third column of files sorted numerically (ascending) # sort -nr -t: -k3 123.txt #Same as above, sorted in descending order # sort -n 123.txt #Numerically sort the first character in the file # sort -n 123.txt -o 123.sh #Save sorted output to 123.sh
4) uniq commands
The uniq command is used to report or ignore duplicate lines in a file and is generally used in conjunction with the sort command.
Common options:
-i: ignore case; -c: counting the number of repetitions; -d: Show only duplicate rows;
5) tee command
The tee command redirects data to a file. On the other hand, you can provide a copy of the redirected data as stdin for subsequent commands.Simply put, redirect the data to a given file and screen.
Common options:
-a: use append mode when redirecting to files; -i: Ignore the interrupt signal.
6) diff command
diff is mainly used to compare the differences of files line by line!
Note: diff describes two files differently by telling us how to change the first file to match the second one!
Common options:
-b: Do not check the spaces; -B: Do not check blank lines; -i: do not check case; -w: Ignore all spaces; --normal: normal format display (default); -c: Context format display; -u: merge format display;
Give an example:
# cat file1 aaaa 111 hello world 222 333 bbb ]# cat file2 aaa hello 111 222 bbb 333 world
1) Normal display
diff Purpose: file1 How to change ability and file2 matching # diff file1 file2 1c1,2 #The first line of the first file needs to be changed to match lines 1 through 2 of the second file < aaaa #The less-than sign'<'denotes the contents of the left file (file1) --- #Separator > aaa #The greater than sign'>'denotes the contents of the right file (file2) > hello 3d3 #The third line of the first file must be deleted to match the third line of the second file < hello world 5d4 #The fifth line of the first file must be deleted to match the fourth line of the second file < 333 6a6,7 #Line 6 of the first file must be added to match lines 6 to 7 of the second file > 333 #What needs to be added is 333 and world in the second file > world
2) Context format display
# diff -c file1 file2 *** file1 2020-02-18 13:46:35.873209160 +0800 --- file2 2020-02-18 13:46:54.009174296 +0800 *************** #Separator *** 1,6 **** #file1 files start with *** and 1,6 lines 1 to 6 ! aaaa #!Indicates that the line needs to be modified to match the second file 111 - hello world #-Indicates that the line needs to be deleted to match the second file 222 - 333 #-Indicates that the line needs to be deleted to match the second file bbb --- 1,7 ---- #file2 files begin with -, 1,7 lines 1 to 7 ! aaa #Indicates that the first file needs to be modified to match the second file ! hello #Indicates that the first file needs to be modified to match the second file 111 222 bbb + 333 #Indicates that the first file needs to be added to match the second file + world #Indicates that the first file needs to be added to match the second file
3) Merge format display
# diff -u file1 file2 --- file1 2020-02-18 13:46:35.873209160 +0800 +++ file2 2020-02-18 13:46:54.009174296 +0800 @@ -1,6 +1,7 @@ #Here are the changes for file1, the same as file2 -aaaa #-for decrease, +for increase +aaa +hello 111 -hello world 222 -333 bbb +333 +world
4) Compare different directories
# mkdir dir{1,2}
# touch dir1/file{1..5}
# touch dir2/file{1..3}
# touch dir2/test{1,2}
# echo 1111 > dir1/file1
# diff dir1 dir2
#Compares the contents of the same file by default
diff dir1/file1 dir2/file1
1d0
< 1111
Exists only in dir1: file4
Exists only in dir1: file5
Exists only in dir2: test1
Exists only in dir2: test2
[root@localhost tmp]# diff -q dir1 dir2
#If you only need to compare the differences between the files in the two directories, you don't need to compare the contents of the files further, you need to add the -q option
Files dir1/file1 and dir2/file1 are different
Exists only in dir1: file4
Exists only in dir1: file5
Exists only in dir2: test1
Exists only in dir2: test25) Tips
Sometimes we need to use one file as the standard to modify other files and modify a lot of things. We can do this by patching.
#Modify the contents of file file1 to match those of file2 in the following way # diff file1 file2 > file.patch #Find out the differences between the files and enter them into a file (normal display, context, combined reflective hi are all possible) # patch file1 file.patch patching file file1 #Patch different contents to file # diff file1 file2 #No result returned means the two files are identical
7) paste command
Pase is mainly used to merge file lines.
Common options:
-d: Custom interval character, tab by default; -s: Serial processing, non-parallel;
Give an example:
# cat file1
file1
8888
# cat file2
file2
9999
1111
# paste file1 file2 #Split by default with tab key
file1 file2
8888 9999
1111
# paste -d: file1 file2 #Use: as a separator
file1:file2
8888:9999
:1111
# paste -s file1 file2 #Serial processing of file1 and file2
file1 8888 #The first line is the contents of file1
file2 9999 1111 #The second line is the contents of file28) tr command
tr is used for character conversion, replacement and deletion, mainly for deleting control characters in files or for character conversion!
Common options:
-d: delete all characters belonging to the first character set; -s: Repeat successive characters in a single character;
Common Regular Expressions
Figure: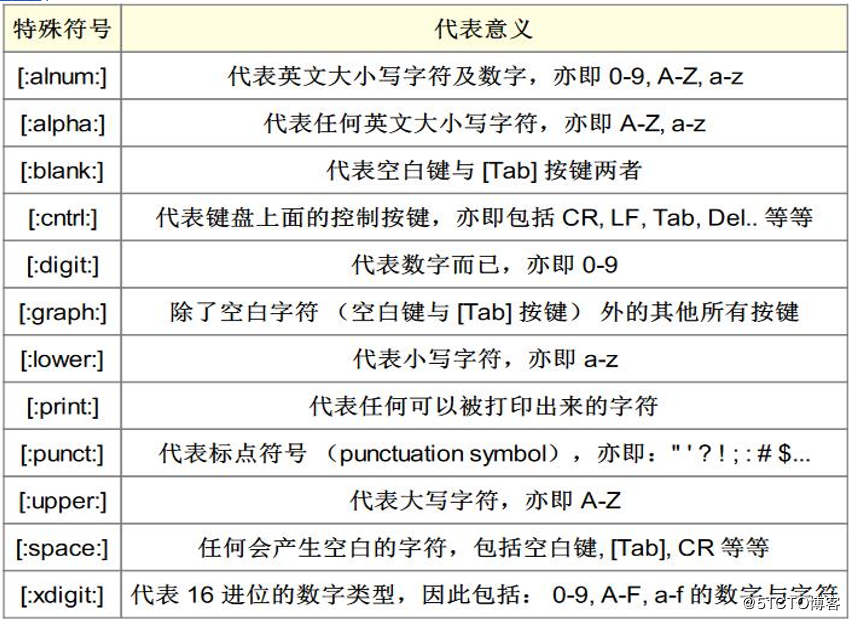
Give an example:
# tr -d '[:/]' < 123.txt #Delete: and/or from file # cat 123.txt | tr -d '[:/]' #Ditto # tr '[0-9]' '@' < 123.txt #Replace the number in the file with the @ symbol # tr '[a-z]' '[A-Z]' < 123.txt #Replace lowercase characters with uppercase characters in a file # tr -s '[a-z]' < 123.txt #Matches lowercase letters in a file and compresses them repeatedly into one # tr -s '[a-z0-9]' < 123.txt #Matches lowercase letters and numbers in a file and compresses consecutive repeated lowercase letters or numbers into one # tr -d '[:digit:]' < 123.txt # tr -d '[0-9]' < 123.txt #Remove numbers from files # tr -d '[:blank:]' < 123.txt # tr -d '[ ]' < 123.txt #Remove (horizontal) white space characters from all files # tr -d '[:space: ]' < 123.txt #Remove all (horizontal or vertical) white space characters from the file