Task 04: machine translation and related technologies; attention mechanism and Seq2seq model; Transformer
1. Machine translation and related technologies
- Machine translation and datasets
Machine translation (MT): automatic translation of a text from one language to another. Solving this problem with neural network is usually called neural machine translation (NMT). Main features: output is a sequence of words rather than a single word. The length of the output sequence may be different from the length of the source sequence.
Steps:
1. Read data
2. Data preprocessing
3. Word segmentation: turn string into a list of words
4. Build a dictionary: change the list of words into the list of word IDS
5.Encoder-Decoder: 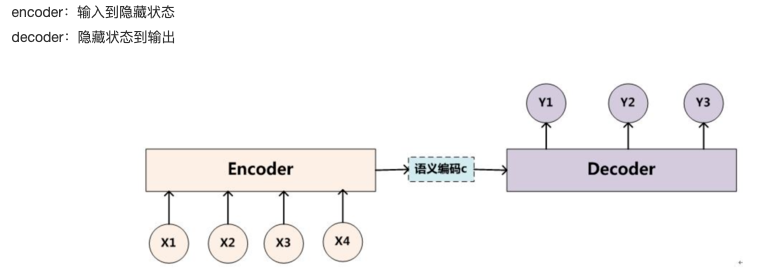
Code implementation:
num_examples = 50000 source, target = [], [] for i, line in enumerate(text.split('\n')): if i > num_examples: break parts = line.split('\t') if len(parts) >= 2: source.append(parts[0].split(' ')) target.append(parts[1].split(' ')) source[0:3], target[0:3] tokens = [token for line in tokens for token in line] return d2l.data.base.Vocab(tokens, min_freq=3, use_special_tokens=True) src_vocab = build_vocab(source) len(src_vocab) def pad(line, max_len, padding_token): if len(line) > max_len: return line[:max_len] return line + [padding_token] * (max_len - len(line)) pad(src_vocab[source[0]], 10, src_vocab.pad) def build_array(lines, vocab, max_len, is_source): lines = [vocab[line] for line in lines] if not is_source: lines = [[vocab.bos] + line + [vocab.eos] for line in lines] array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines]) valid_len = (array != vocab.pad).sum(1) #First dimension return array, valid_len class EncoderDecoder(nn.Module): def __init__(self, encoder, decoder, **kwargs): super(EncoderDecoder, self).__init__(**kwargs) self.encoder = encoder self.decoder = decoder def forward(self, enc_X, dec_X, *args): enc_outputs = self.encoder(enc_X, *args) dec_state = self.decoder.init_state(enc_outputs, *args) return self.decoder(dec_X, dec_state)
2. Attention mechanism and Seq2seq model
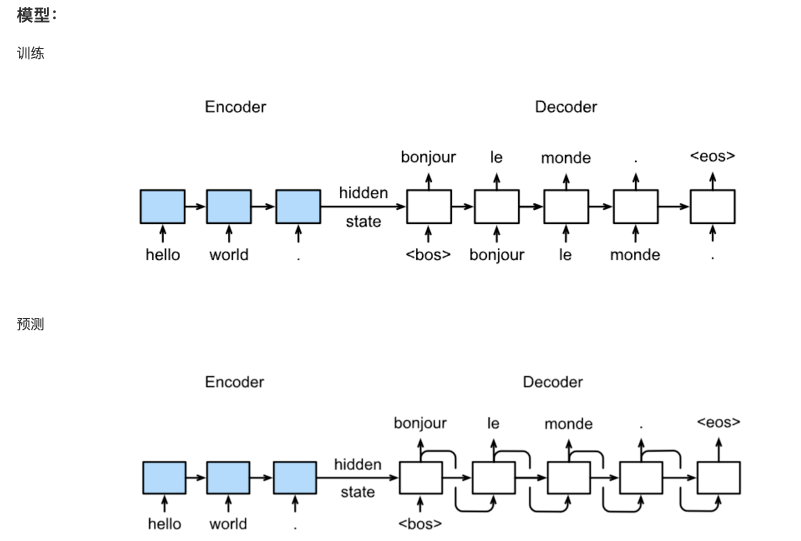
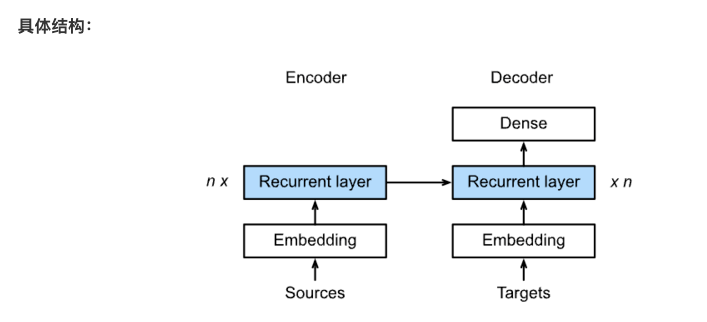
Here, the output of Encoder becomes the input of Decoder
class Seq2SeqEncoder(d2l.Encoder): def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs): super(Seq2SeqEncoder, self).__init__(**kwargs) self.num_hiddens=num_hiddens self.num_layers=num_layers self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout) def begin_state(self, batch_size, device): return [torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device), torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)] def forward(self, X, *args): X = self.embedding(X) # X shape: (batch_size, seq_len, embed_size) X = X.transpose(0, 1) # RNN needs first axes to be time # state = self.begin_state(X.shape[1], device=X.device) out, state = self.rnn(X) # The shape of out is (seq_len, batch_size, num_hiddens). # state contains the hidden state and the memory cell # of the last time step, the shape is (num_layers, batch_size, num_hiddens) return out, state class Seq2SeqDecoder(d2l.Decoder): def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs): super(Seq2SeqDecoder, self).__init__(**kwargs) self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout) self.dense = nn.Linear(num_hiddens,vocab_size) def init_state(self, enc_outputs, *args): return enc_outputs[1] def forward(self, X, state): X = self.embedding(X).transpose(0, 1) out, state = self.rnn(X, state) # Make the batch to be the first dimension to simplify loss computation. out = self.dense(out).transpose(0, 1) return out, state def SequenceMask(X, X_len,value=0): maxlen = X.size(1) mask = torch.arange(maxlen)[None, :].to(X_len.device) < X_len[:, None] X[~mask]=value return X class MaskedSoftmaxCELoss(nn.CrossEntropyLoss): # pred shape: (batch_size, seq_len, vocab_size) # label shape: (batch_size, seq_len) # valid_length shape: (batch_size, ) def forward(self, pred, label, valid_length): # the sample weights shape should be (batch_size, seq_len) weights = torch.ones_like(label) weights = SequenceMask(weights, valid_length).float() self.reduction='none' output=super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label) return (output*weights).mean(dim=1) def train_ch7(model, data_iter, lr, num_epochs, device): # Saved in d2l model.to(device) optimizer = optim.Adam(model.parameters(), lr=lr) loss = MaskedSoftmaxCELoss() tic = time.time() for epoch in range(1, num_epochs+1): l_sum, num_tokens_sum = 0.0, 0.0 for batch in data_iter: optimizer.zero_grad() X, X_vlen, Y, Y_vlen = [x.to(device) for x in batch] Y_input, Y_label, Y_vlen = Y[:,:-1], Y[:,1:], Y_vlen-1 Y_hat, _ = model(X, Y_input, X_vlen, Y_vlen) l = loss(Y_hat, Y_label, Y_vlen).sum() l.backward() with torch.no_grad(): d2l.grad_clipping_nn(model, 5, device) num_tokens = Y_vlen.sum().item() optimizer.step() l_sum += l.sum().item() num_tokens_sum += num_tokens if epoch % 50 == 0: print("epoch {0:4d},loss {1:.3f}, time {2:.1f} sec".format( epoch, (l_sum/num_tokens_sum), time.time()-tic)) tic = time.time()
Here is a brief introduction to BeamSearch:
In fact, we don't need to search all the data sets when searching for the most probable words, but only to see which ones are more likely to be searched by us. So in the search process, we only need to pick out the most probable words in the search route, and then we get the pruning effect to speed up the search efficiency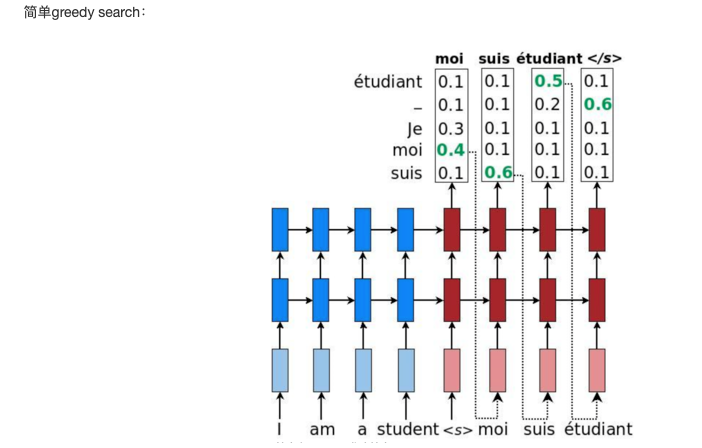
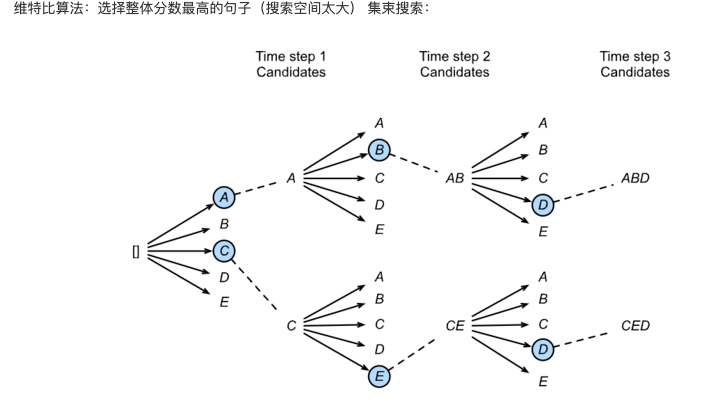
In this figure, we choose 2 as the number of clusters, AC as the first probability, AB and CE as the second probability, ABD and CED as the third probability, and so on, to get the final sequence.
Attention mechanism
In the "encoder decoder (seq2seq)" section, the decoder relies on the same context vector to obtain the input sequence information in each time step. When the encoder is a cyclic neural network, the background variable is used to detect the hidden state of its final time step. The source sequence input information is encoded in a cyclic unit state and then passed to the decoder to generate the target sequence. However, there are some problems with this structure, especially the problem of long-range gradient disappearing in RNN mechanism. For long sentences, it is very difficult for us to hope to save all the effective information by transforming the input sequence into a fixed length vector. Therefore, with the increase of the length of the required translation sentence, the effect of this structure will decline significantly.
At the same time, the decoded target words may only be related to part of the original input words, not all the input words. For example, when "Hello world" is translated into "Bonjour Le Monte," hello "is mapped to" Bonjour "and" world "to" Monte ". In the seq2seq model, the decoder can only implicitly select the corresponding information from the final state of the encoder. However, attention mechanism can explicitly model the selection process.
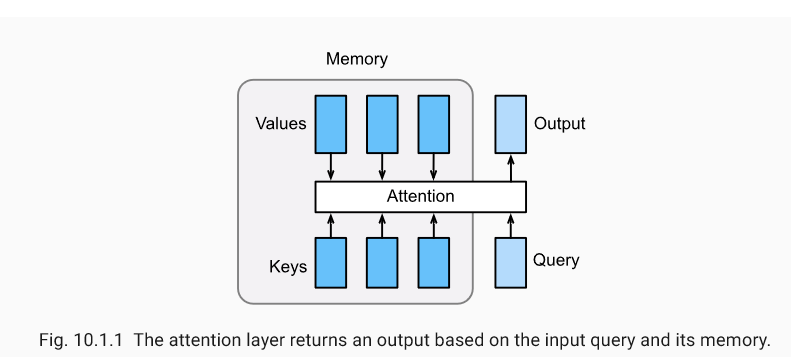

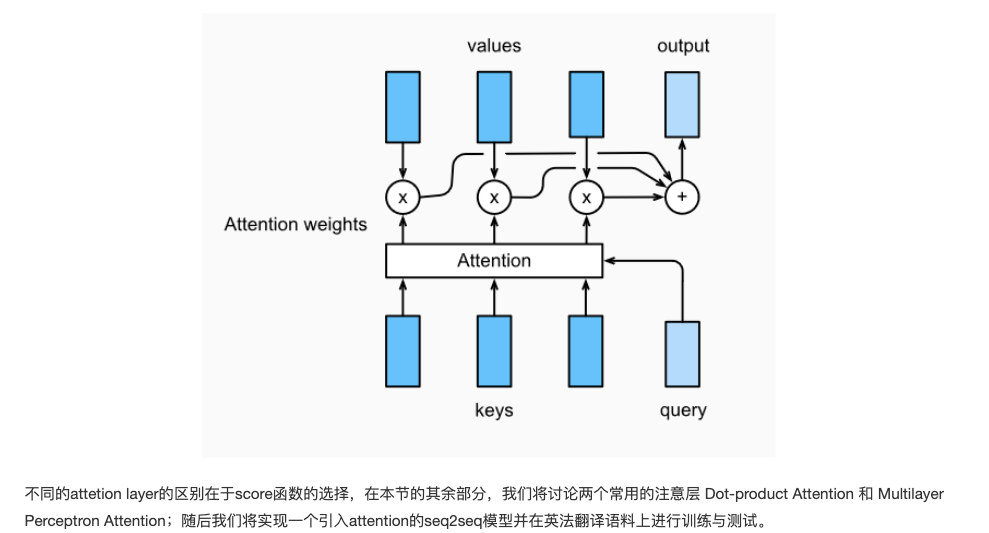

- Before that, let's talk about Softmax shielding
def SequenceMask(X, X_len,value=-1e6): maxlen = X.size(1) #print(X.size(),torch.arange((maxlen),dtype=torch.float)[None, :],'\n',X_len[:, None] ) mask = torch.arange((maxlen),dtype=torch.float)[None, :] >= X_len[:, None] #print(mask) X[mask]=value return X def masked_softmax(X, valid_length): # X: 3-D tensor, valid_length: 1-D or 2-D tensor softmax = nn.Softmax(dim=-1) if valid_length is None: return softmax(X) else: shape = X.shape if valid_length.dim() == 1: try: valid_length = torch.FloatTensor(valid_length.numpy().repeat(shape[1], axis=0))#[2,2,3,3] except: valid_length = torch.FloatTensor(valid_length.cpu().numpy().repeat(shape[1], axis=0))#[2,2,3,3] else: valid_length = valid_length.reshape((-1,)) # fill masked elements with a large negative, whose exp is 0 X = SequenceMask(X.reshape((-1, shape[-1])), valid_length) return softmax(X).reshape(shape)
- Two attention mechanisms
Dot product attention

class DotProductAttention(nn.Module): def __init__(self, dropout, **kwargs): super(DotProductAttention, self).__init__(**kwargs) self.dropout = nn.Dropout(dropout) # query: (batch_size, #queries, d) # key: (batch_size, #kv_pairs, d) # value: (batch_size, #kv_pairs, dim_v) # valid_length: either (batch_size, ) or (batch_size, xx) def forward(self, query, key, value, valid_length=None): d = query.shape[-1] # set transpose_b=True to swap the last two dimensions of key scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d) attention_weights = self.dropout(masked_softmax(scores, valid_length)) print("attention_weight\n",attention_weights) return torch.bmm(attention_weights, value) atten = DotProductAttention(dropout=0) keys = torch.ones((2,10,2),dtype=torch.float) values = torch.arange((40), dtype=torch.float).view(1,10,4).repeat(2,1,1) atten(torch.ones((2,1,2),dtype=torch.float), keys, values, torch.FloatTensor([2, 6])) attention_weight tensor([[[0.5000, 0.5000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]], [[0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.0000, 0.0000, 0.0000, 0.0000]]])
- Attention of multi-layer perceptron

class MLPAttention(nn.Module): def __init__(self, units,ipt_dim,dropout, **kwargs): super(MLPAttention, self).__init__(**kwargs) # Use flatten=True to keep query's and key's 3-D shapes. self.W_k = nn.Linear(ipt_dim, units, bias=False) self.W_q = nn.Linear(ipt_dim, units, bias=False) self.v = nn.Linear(units, 1, bias=False) self.dropout = nn.Dropout(dropout) def forward(self, query, key, value, valid_length): query, key = self.W_k(query), self.W_q(key) #print("size",query.size(),key.size()) # expand query to (batch_size, #querys, 1, units), and key to # (batch_size, 1, #kv_pairs, units). Then plus them with broadcast. features = query.unsqueeze(2) + key.unsqueeze(1) #print("features:",features.size()) #--------------On scores = self.v(features).squeeze(-1) attention_weights = self.dropout(masked_softmax(scores, valid_length)) return torch.bmm(attention_weights, value) atten = MLPAttention(ipt_dim=2,units = 8, dropout=0) atten(torch.ones((2,1,2), dtype = torch.float), keys, values, torch.FloatTensor([2, 6]))
- Seq2seq model with attention mechanism
In this section, the attention mechanism is added to the sequence to sequence model to explicitly aggregate states using weights. The following figure shows the model structure of encoding and decoding, when the time step is t. At the moment, the attention layer holds all the information that encoding sees - the output of each step of encoding. In the coding stage, the hidden state of the decoder's time is treated as query, and the hidden states of each time step of the encoder are used as key and value for attention aggregation. The output of the attention model is treated as context vector, which is spliced with the decoder's input Dt and sent to the decoder: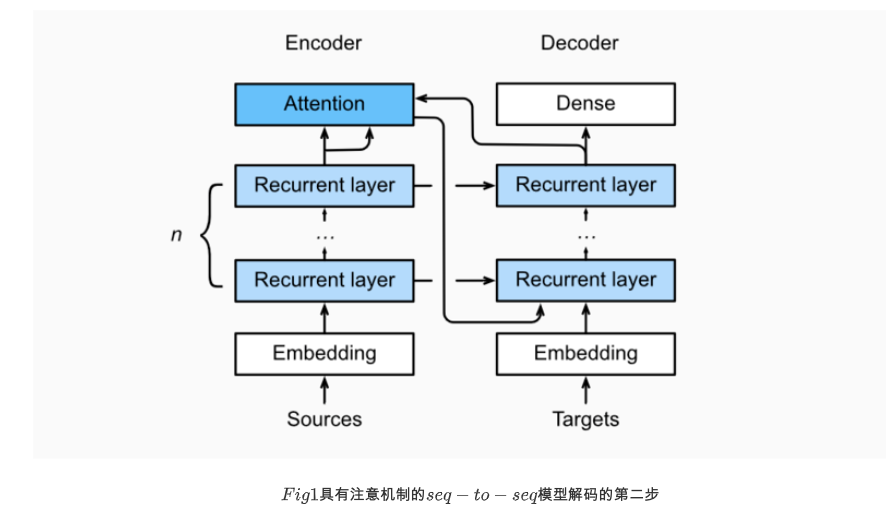
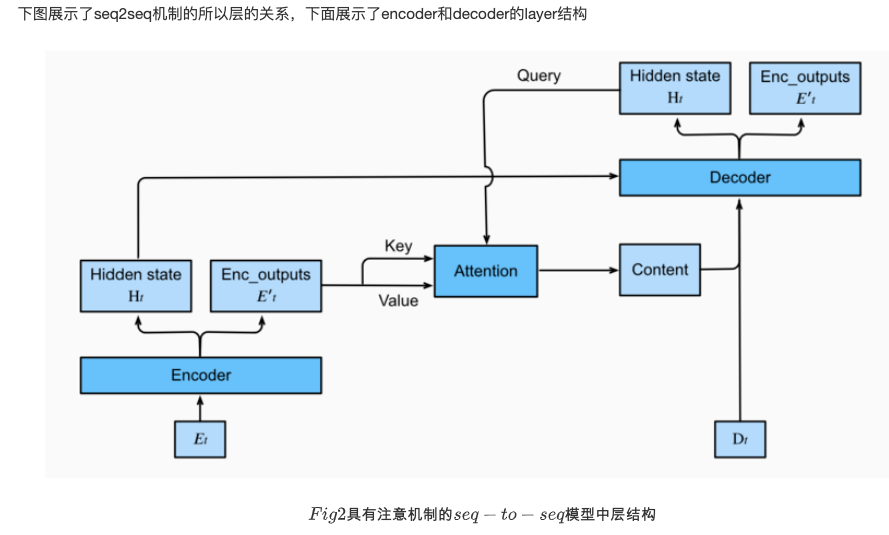
- Decoder
Since the encoder of seq2seq with attention mechanism is the same as Seq2SeqEncoder in the previous chapter, we only focus on the decoder here. We added an MLP attention layer (MLPAttention), which has the same hidden size as the LSTM layer in the decoder. Then we initialize the decoder state by passing three parameters from the encoder:
- the encoder outputs of all timesteps: each state of the encoder output is used in the memory part of the attachment layer, with the same key and values
- the hidden state of the encoder's final timestep: the hidden state of the last time step of the encoder, which is used to initialize the decoder's hidden state
- the encoder valid length: the effective length of the encoder, by which the layer will not consider the padding in the encoder output
At each time step of decoding, we use the output of the last RNN layer of the decoder as the query of the attention layer. Then, the output of the attention model is connected with the input embedding vector and input to the RNN layer. Although the hidden state of RNN layer also contains the historical information from decoder, the output of attention model explicitly selects the encoder output within enc_valid_len, so that the attention mechanism will exclude other irrelevant information as much as possible.
class Seq2SeqAttentionDecoder(d2l.Decoder): def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs): super(Seq2SeqAttentionDecoder, self).__init__(**kwargs) self.attention_cell = MLPAttention(num_hiddens,num_hiddens, dropout) self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = nn.LSTM(embed_size+ num_hiddens,num_hiddens, num_layers, dropout=dropout) self.dense = nn.Linear(num_hiddens,vocab_size) def init_state(self, enc_outputs, enc_valid_len, *args): outputs, hidden_state = enc_outputs # print("first:",outputs.size(),hidden_state[0].size(),hidden_state[1].size()) # Transpose outputs to (batch_size, seq_len, hidden_size) return (outputs.permute(1,0,-1), hidden_state, enc_valid_len) #outputs.swapaxes(0, 1) def forward(self, X, state): enc_outputs, hidden_state, enc_valid_len = state #("X.size",X.size()) X = self.embedding(X).transpose(0,1) # print("Xembeding.size2",X.size()) outputs = [] for l, x in enumerate(X): # print(f"\n{l}-th token") # print("x.first.size()",x.size()) # query shape: (batch_size, 1, hidden_size) # select hidden state of the last rnn layer as query query = hidden_state[0][-1].unsqueeze(1) # np.expand_dims(hidden_state[0][-1], axis=1) # context has same shape as query # print("query enc_outputs, enc_outputs:\n",query.size(), enc_outputs.size(), enc_outputs.size()) context = self.attention_cell(query, enc_outputs, enc_outputs, enc_valid_len) # Concatenate on the feature dimension # print("context.size:",context.size()) x = torch.cat((context, x.unsqueeze(1)), dim=-1) # Reshape x to (1, batch_size, embed_size+hidden_size) # print("rnn",x.size(), len(hidden_state)) out, hidden_state = self.rnn(x.transpose(0,1), hidden_state) outputs.append(out) outputs = self.dense(torch.cat(outputs, dim=0)) return outputs.transpose(0, 1), [enc_outputs, hidden_state, enc_valid_len] encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2) # encoder.initialize() decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2) X = torch.zeros((4, 7),dtype=torch.long) print("batch size=4\nseq_length=7\nhidden dim=16\nnum_layers=2\n") print('encoder output size:', encoder(X)[0].size()) print('encoder hidden size:', encoder(X)[1][0].size()) print('encoder memory size:', encoder(X)[1][1].size()) state = decoder.init_state(encoder(X), None) out, state = decoder(X, state) out.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
3.Transformer
In the previous chapters, we have introduced the main neural network architecture, such as convolutional neural network (CNNs) and cyclic neural network (RNNs). Let's review:
- CNN is easy to parallelize, but it is not suitable to capture the dependency in variable length sequences.
- RNNs is suitable for capturing the dependence of long-distance variable length sequences, but it is difficult to realize parallel processing sequences.
In order to integrate the advantages of CNN and RNN, [Vaswani et al., 2017] innovatively designed Transformer model using attention mechanism. This model uses the attention mechanism to realize the parallel capture of sequence dependency, and simultaneously processes the tokens of each position of the sequence. The above advantages make the Transformer model have excellent performance and greatly reduce the training time.
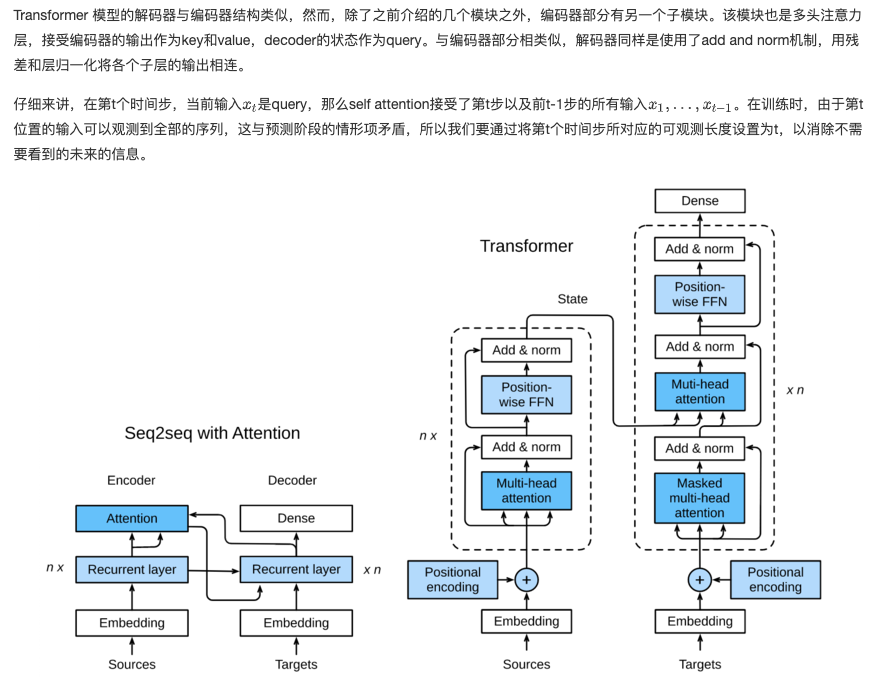
Figure 10.3.1 shows the architecture of transformer model, which is similar to seq2seq model in section 9.7. Transformer is also based on encoder decoder architecture, with the following three main differences:
1.Transformer blocks: replace the cyclic network of seq2seq model with Transformer Blocks. The module includes a multi head attention layer and two position wise feed forward networks (FFN). For the decoder, another multi attention layer is used to accept the hidden state of the encoder.
2.Add and norm: the output of multi attention layer and feedforward network is sent to two "add and norm" layers for processing, which include residual structure and layer normalization.
3.Position encoding: since the self attention layer does not distinguish the order of elements, a position encoding layer is used to add position information to sequence elements.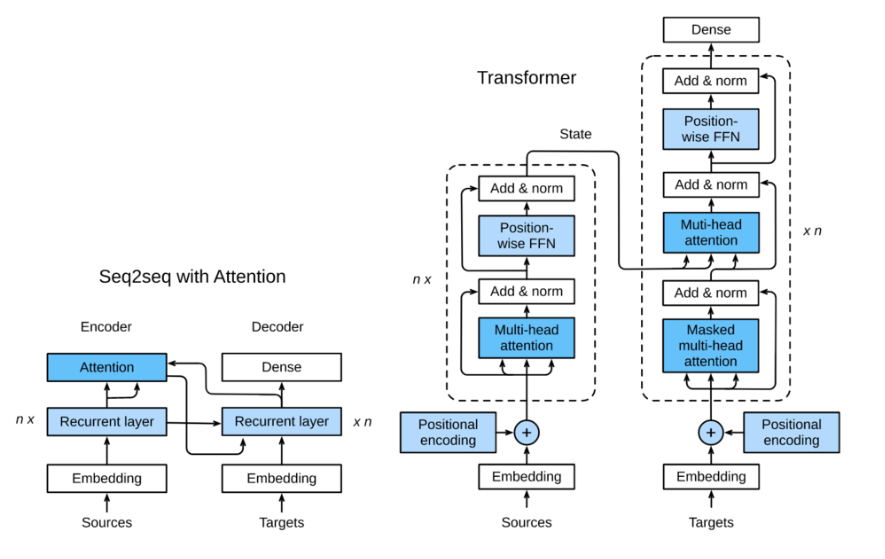
- Multiple attention level
Before we discuss the multi attention layer, let's quickly understand the following structure of self attention. Self attention model is a normal attention model. The key, value and query corresponding to each element of the sequence are completely consistent. As shown in figure 10.3.2, self attention outputs a characterization sequence with the same length as the input. Compared with the cyclic neural network, the calculation of self attention output for each element is parallel, so we can effectively implement this module.
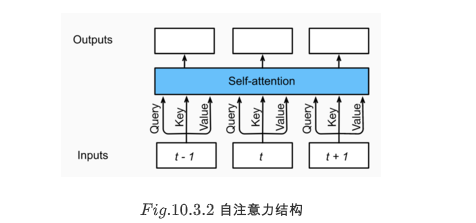
The multi attention layer consists of H parallel self attention layers, each of which is called a head. For each header, before attention calculation, we will map query, key and value with three current layers, and the output of these h attention headers will be spliced and input into the last linear layer for integration.

class MultiHeadAttention(nn.Module): def __init__(self, input_size, hidden_size, num_heads, dropout, **kwargs): super(MultiHeadAttention, self).__init__(**kwargs) self.num_heads = num_heads self.attention = DotProductAttention(dropout) self.W_q = nn.Linear(input_size, hidden_size, bias=False) self.W_k = nn.Linear(input_size, hidden_size, bias=False) self.W_v = nn.Linear(input_size, hidden_size, bias=False) self.W_o = nn.Linear(hidden_size, hidden_size, bias=False) def forward(self, query, key, value, valid_length): # query, key, and value shape: (batch_size, seq_len, dim), # where seq_len is the length of input sequence # valid_length shape is either (batch_size, ) # or (batch_size, seq_len). # Project and transpose query, key, and value from # (batch_size, seq_len, hidden_size * num_heads) to # (batch_size * num_heads, seq_len, hidden_size). query = transpose_qkv(self.W_q(query), self.num_heads) key = transpose_qkv(self.W_k(key), self.num_heads) value = transpose_qkv(self.W_v(value), self.num_heads) if valid_length is not None: # Copy valid_length by num_heads times device = valid_length.device valid_length = valid_length.cpu().numpy() if valid_length.is_cuda else valid_length.numpy() if valid_length.ndim == 1: valid_length = torch.FloatTensor(np.tile(valid_length, self.num_heads)) else: valid_length = torch.FloatTensor(np.tile(valid_length, (self.num_heads,1))) valid_length = valid_length.to(device) output = self.attention(query, key, value, valid_length) output_concat = transpose_output(output, self.num_heads) return self.W_o(output_concat) def transpose_qkv(X, num_heads): # Original X shape: (batch_size, seq_len, hidden_size * num_heads), # -1 means inferring its value, after first reshape, X shape: # (batch_size, seq_len, num_heads, hidden_size) X = X.view(X.shape[0], X.shape[1], num_heads, -1) # After transpose, X shape: (batch_size, num_heads, seq_len, hidden_size) X = X.transpose(2, 1).contiguous() # Merge the first two dimensions. Use reverse=True to infer shape from # right to left. # output shape: (batch_size * num_heads, seq_len, hidden_size) output = X.view(-1, X.shape[2], X.shape[3]) return output # Saved in the d2l package for later use def transpose_output(X, num_heads): # A reversed version of transpose_qkv X = X.view(-1, num_heads, X.shape[1], X.shape[2]) X = X.transpose(2, 1).contiguous() return X.view(X.shape[0], X.shape[1], -1) cell = MultiHeadAttention(5, 9, 3, 0.5) X = torch.ones((2, 4, 5)) valid_length = torch.FloatTensor([2, 3]) cell(X, X, X, valid_length).shape
- Position based feedforward network
Another very important part of the Transformer module is the position based feedforward network (FFN), which accepts a three-dimensional tensor with the shape of (batch size, SEQ length, feature size). Position wise FFN consists of two fully connected layers, which act on the last dimension. Because the state of each position of the sequence is updated separately, we call it position wise, which is equivalent to a convolution of 1x1.
class PositionWiseFFN(nn.Module): def __init__(self, input_size, ffn_hidden_size, hidden_size_out, **kwargs): super(PositionWiseFFN, self).__init__(**kwargs) self.ffn_1 = nn.Linear(input_size, ffn_hidden_size) self.ffn_2 = nn.Linear(ffn_hidden_size, hidden_size_out) def forward(self, X): return self.ffn_2(F.relu(self.ffn_1(X)))
Similar to the multi attention layer, the FFN layer only changes the size of the last dimension; in addition, for two identical inputs, the output of the FFN layer will be equal.
- Add and Norm
In addition to the above two modules, Transformer also has an important additive normalization layer, which can smoothly integrate the input and the output of other layers, so we add a Layer Norm layer with residual connection behind each multi attention layer and FFN layer. Here, Layer Norm is very similar to Batch Norm in section 7.5. The only difference is that Batch Norm calculates the mean and variance of batch size, while Layer Norm calculates the last dimension. Layer normalization can prevent the numerical changes in the layer from being too large, which is helpful to speed up the training speed and improve the generalization performance.
layernorm = nn.LayerNorm(normalized_shape=2, elementwise_affine=True) batchnorm = nn.BatchNorm1d(num_features=2, affine=True) X = torch.FloatTensor([[1,2], [3,4]]) print('layer norm:', layernorm(X)) print('batch norm:', batchnorm(X)) class AddNorm(nn.Module): def __init__(self, hidden_size, dropout, **kwargs): super(AddNorm, self).__init__(**kwargs) self.dropout = nn.Dropout(dropout) self.norm = nn.LayerNorm(hidden_size) def forward(self, X, Y): return self.norm(self.dropout(Y) + X) add_norm = AddNorm(4, 0.5) add_norm(torch.ones((2,3,4)), torch.ones((2,3,4))).shape
- Position encoding
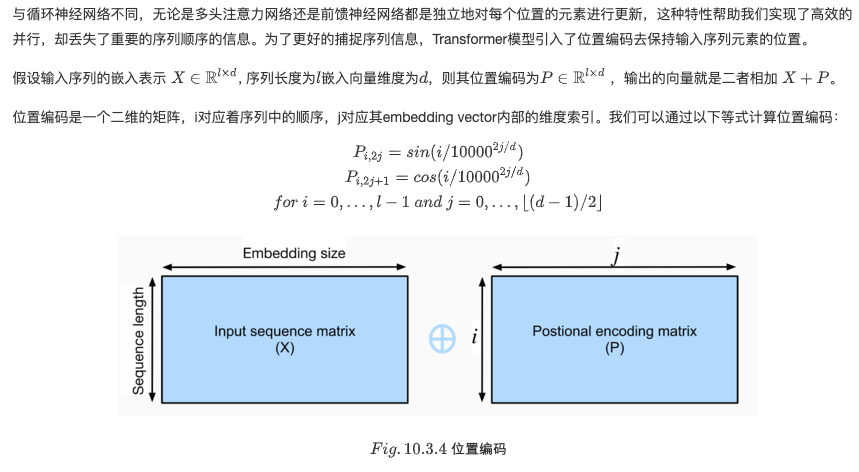
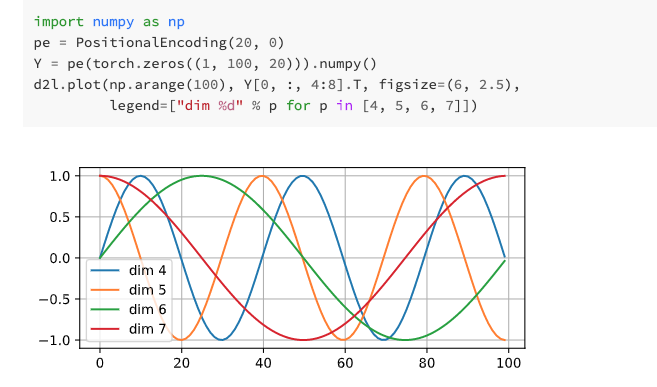
class PositionalEncoding(nn.Module): def __init__(self, embedding_size, dropout, max_len=1000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(dropout) self.P = np.zeros((1, max_len, embedding_size)) X = np.arange(0, max_len).reshape(-1, 1) / np.power( 10000, np.arange(0, embedding_size, 2)/embedding_size) self.P[:, :, 0::2] = np.sin(X) self.P[:, :, 1::2] = np.cos(X) self.P = torch.FloatTensor(self.P) def forward(self, X): if X.is_cuda and not self.P.is_cuda: self.P = self.P.cuda() X = X + self.P[:, :X.shape[1], :] return self.dropout(X)
This makes the phases of information in different sequences different, for example:
- Encoder
We have all the modules that make up Transformer, now we can start to build it! The encoder consists of a multi attention layer, a position wise FFN, and two Add and Norm layers. For the attention model and FFN model, our output dimension is consistent with the embedding dimension, which is also caused by the inherent characteristics of residual connection, because we want to add and normalize the output of the previous layer and the original input.
class EncoderBlock(nn.Module): def __init__(self, embedding_size, ffn_hidden_size, num_heads, dropout, **kwargs): super(EncoderBlock, self).__init__(**kwargs) self.attention = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout) self.addnorm_1 = AddNorm(embedding_size, dropout) self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size) self.addnorm_2 = AddNorm(embedding_size, dropout) def forward(self, X, valid_length): Y = self.addnorm_1(X, self.attention(X, X, X, valid_length)) return self.addnorm_2(Y, self.ffn(Y)) X = torch.ones((2, 100, 24)) encoder_blk = EncoderBlock(24, 48, 8, 0.5) encoder_blk(X, valid_length).shape
Realize the whole Transformer encoder model. The whole encoder is made up of n just defined encoder blocks. Because of the residual connection, the dimension of the intermediate state is always the same as the dimension d of the embedded vector. At the same time, notice that we multiply the embedded vector by d^(1/2) to prevent its value from being too small.
class TransformerEncoder(d2l.Encoder): def __init__(self, vocab_size, embedding_size, ffn_hidden_size, num_heads, num_layers, dropout, **kwargs): super(TransformerEncoder, self).__init__(**kwargs) self.embedding_size = embedding_size self.embed = nn.Embedding(vocab_size, embedding_size) self.pos_encoding = PositionalEncoding(embedding_size, dropout) self.blks = nn.ModuleList() for i in range(num_layers): self.blks.append( EncoderBlock(embedding_size, ffn_hidden_size, num_heads, dropout)) def forward(self, X, valid_length, *args): X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size)) for blk in self.blks: X = blk(X, valid_length) return X encoder = TransformerEncoder(200, 24, 48, 8, 2, 0.5) encoder(torch.ones((2, 100)).long(), valid_length).shape
Decoder
def __init__(self, embedding_size, ffn_hidden_size, num_heads,dropout,i,**kwargs): super(DecoderBlock, self).__init__(**kwargs) self.i = i self.attention_1 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout) self.addnorm_1 = AddNorm(embedding_size, dropout) self.attention_2 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout) self.addnorm_2 = AddNorm(embedding_size, dropout) self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size) self.addnorm_3 = AddNorm(embedding_size, dropout) def forward(self, X, state): enc_outputs, enc_valid_length = state[0], state[1] # state[2][self.i] stores all the previous t-1 query state of layer-i # len(state[2]) = num_layers # If training: # state[2] is useless. # If predicting: # In the t-th timestep: # state[2][self.i].shape = (batch_size, t-1, hidden_size) # Demo: # love dogs ! [EOS] # | | | | # Transformer # Decoder # | | | | # I love dogs ! if state[2][self.i] is None: key_values = X else: # shape of key_values = (batch_size, t, hidden_size) key_values = torch.cat((state[2][self.i], X), dim=1) state[2][self.i] = key_values if self.training: batch_size, seq_len, _ = X.shape # Shape: (batch_size, seq_len), the values in the j-th column are j+1 valid_length = torch.FloatTensor(np.tile(np.arange(1, seq_len+1), (batch_size, 1))) valid_length = valid_length.to(X.device) else: valid_length = None X2 = self.attention_1(X, key_values, key_values, valid_length) Y = self.addnorm_1(X, X2) Y2 = self.attention_2(Y, enc_outputs, enc_outputs, enc_valid_length) Z = self.addnorm_2(Y, Y2) return self.addnorm_3(Z, self.ffn(Z)), state class TransformerDecoder(d2l.Decoder): def __init__(self, vocab_size, embedding_size, ffn_hidden_size, num_heads, num_layers, dropout, **kwargs): super(TransformerDecoder, self).__init__(**kwargs) self.embedding_size = embedding_size self.num_layers = num_layers self.embed = nn.Embedding(vocab_size, embedding_size) self.pos_encoding = PositionalEncoding(embedding_size, dropout) self.blks = nn.ModuleList() for i in range(num_layers): self.blks.append( DecoderBlock(embedding_size, ffn_hidden_size, num_heads, dropout, i)) self.dense = nn.Linear(embedding_size, vocab_size) def init_state(self, enc_outputs, enc_valid_length, *args): return [enc_outputs, enc_valid_length, [None]*self.num_layers] def forward(self, X, state): X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size)) for blk in self.blks: X, state = blk(X, state) return self.dense(X), state
reference material:
https://www.kesci.com/org/boyuai/project/5e43f70f5f2816002ceb6357
https://www.kesci.com/org/boyuai/project/5e43cb9a5f2816002ceadf6d
https://www.kesci.com/org/boyuai/project/5e43cba95f2816002ceadfab

