Article directory
I don't know if other people will do this. Anyway, as an Acmer who has been in the pit for more than one year, sometimes I want to know how many problems I have written. Of course, I can go to OJ for one problem, but it's not a programmer. How can I do such mechanical work by myself. Although there is an open-source project now, which can be counted in the major OJS, I still want to implement it myself. I just learned Python crawler recently, and I can finish my previous flag. The main OJS, such as codeforces, HDU, POJ and Logu, will be crawled, and the AC quantity will be counted. Finally, QT will be used to realize the interface. If you don't say much, go straight to the point and start with codeforces.
1, Demand analysis
- First we should find the url of the submission interface.
- Analyze the request mode.
- Analyze the source code of web page through browser's checking tool.
- Get what we need and save it to a text or database.
- After analyzing the current interface, turn the page, and then repeat the above steps.
2, Specific implementation
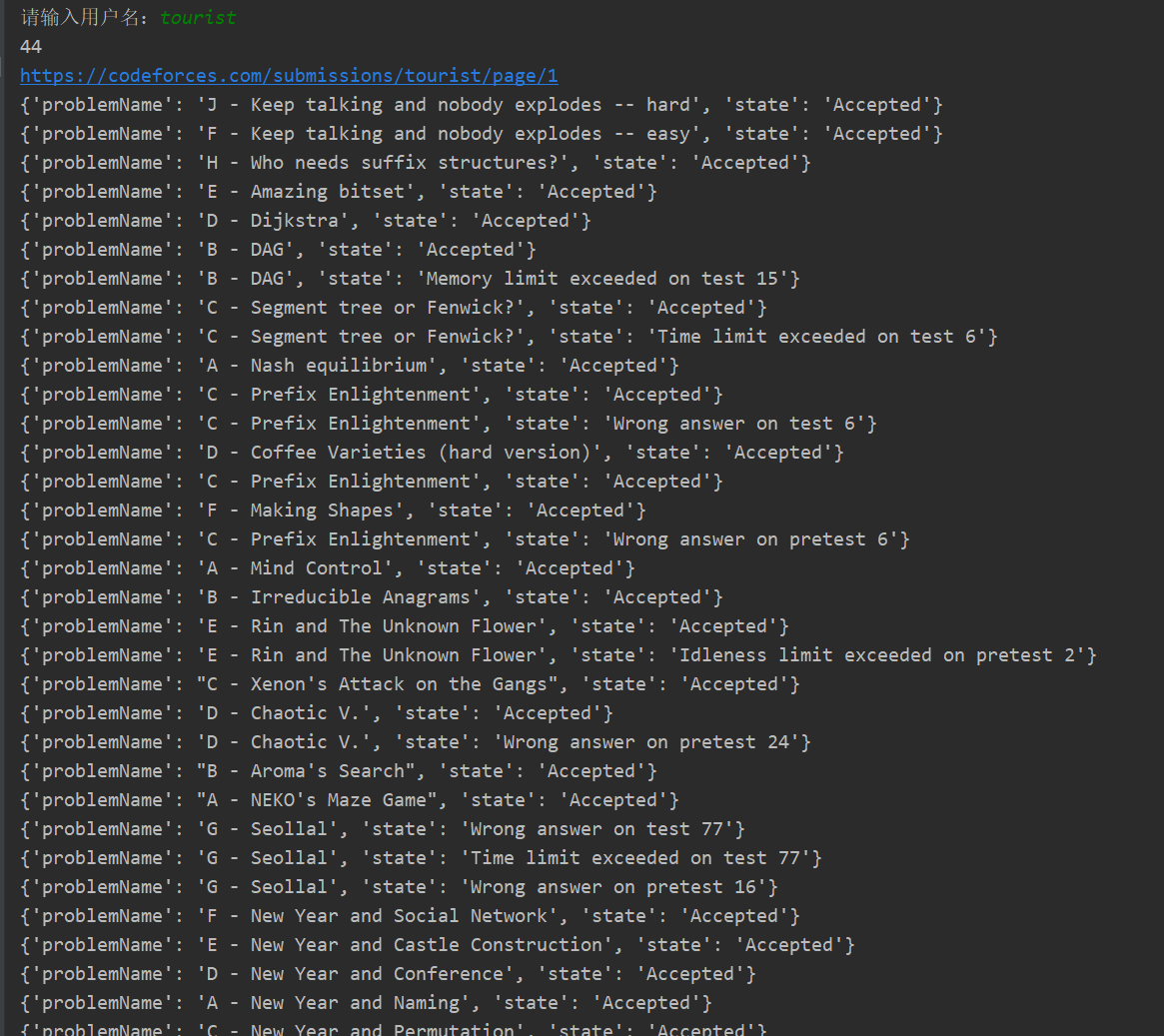
Take the submission information interface of the tourist boss as an example.
- Analyze url links
When you first enter the submit interface, the url is like this

Then we turn the page. You can find the rule of the url of each page submission interface, as follows, and finally the current page number. It's the way synchronous requests are used. Since it's a synchronous request, it's very easy to do. Get the html text directly, and then parse it.
https://codeforces.com/submissions/username/page/2

- Send request
To send a request through the requests library, you can choose not to set headers, because codeforces is not anti crawler.
import requests url = 'https://codeforces.com/submissions/tourist/page/1' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36' } response = requests.get(url=url, headers=headers)
- Analyze the web page and then analyze it
Using the chrome browser, right-click on the commit record and select check. Other browsers are similar.
After observation, it can be found that the submission record information is placed in a table, and each submission record is placed in a tr tag. Then we need to extract these tr tags first, and then analyze them according to the information we want (title, submission status, etc.).

After checking, we can confirm that the data submission ID attribute is unique to the tr tag. Then we can locate the tr tag through this attribute. Use pyquery for parsing (similar to JQuery syntax, supporting css selector).
from pyquery import PyQuery as pq doc=pq(response.text) items = doc.find('[data-submission-id]').items() #It is convenient to generate an iterator from the found elements.
After extracting each tr tag, we start to work on each td tag in it. I extracted the title name and submission status. The other way is the same.

Now parse each td separately. So you can use * *. Status small > A to locate the a tag. Then extract its text content, that is, title. However, if it is from the whole web page, you can choose to locate it through the specific tag of data problemid. Use: nth child (6) * * to get the content of the submission status. Package the acquired content into a dictionary. (of course, other forms are also available, and it depends on whether you want to save it to the database or text.)
items = doc.find('[data-submission-id]').items() for item in items: it = solve_tr(item) problemName = tr.find('.status-small>a').text() state = tr.find(':nth-child(6)').text() it = {'problemName': problemName, 'state': state}
problemName=tr.find('[data-problemid]>a').text()
- Get page number
So far, we can parse the submitted content of a page, but if we implement the page turning function. To realize the function of page turning is very simple, just replace the last number of the url.
https://codeforces.com/submissions/username/page/2 https://codeforces.com/submissions/username/page/3
The point is that we should turn the page a few times. There are two solutions to the page flipping problem. One is a dead cycle, which goes on all the time and stops when an exception occurs. But this is not feasible in codeforces, because if the page number is exceeded, the last page will be displayed by default. So we can only count the number of pages honestly.
The page number label is in an unordered table. The content of the penultimate li label is the total page number, so we just need to get the content.
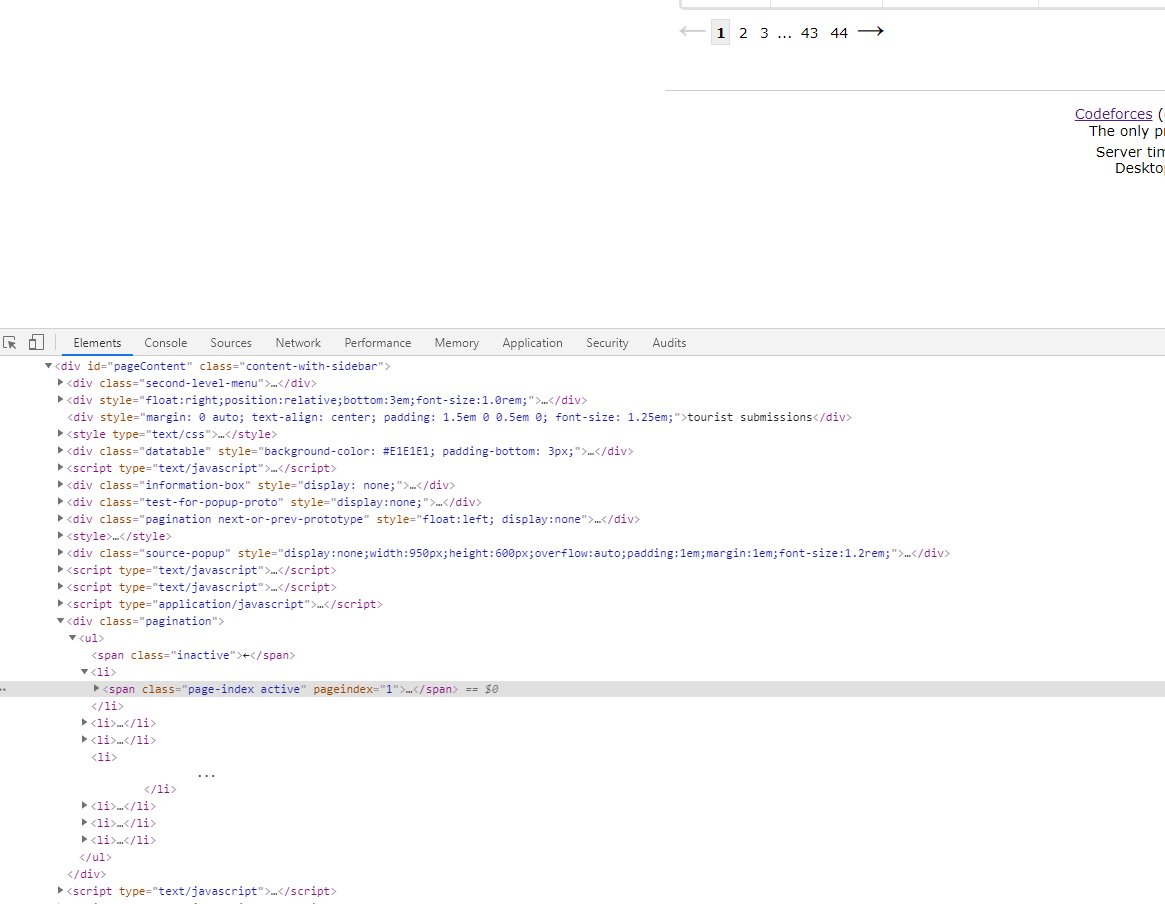
Obtained through the nth child selector.
def get_pages_num(doc): """ //Get the number of pages to crawl :param doc: pyquery Returned parser :return: int,Number of pages """ try: length = doc.find('#pageContent>.pagination>ul>*').length last_li = doc.find('#pageContent>.pagination>ul>li:nth-child(' + str(length-1) + ')') print('length', length) print(last_li.text()) # for item in items: # print(item) return max(1, int(last_li.text())) except Exception : return None
Now the requirement of crawling codeforces is basically completed. Sort out the above code and finish it.
3, Full code
It's a great pleasure to have a code that can run directly, so I posted the complete code
from pyquery import PyQuery as pq import requests import time def solve_tr(tr): """ //Analyze what we need :param tr: tr element :return: dict """ problemName = tr.find('.status-small>a').text() state = tr.find(':nth-child(6)').text() it = {'problemName': problemName, 'state': state} return it def get_pages_num(doc): """ //Get the number of pages to crawl :param doc: pyquery Returned parser :return: int,Number of pages """ try: length = doc.find('#pageContent>.pagination>ul>*').length last_li = doc.find('#pageContent>.pagination>ul>li:nth-child(' + str(length-1) + ')') print('length', length) print(last_li.text()) # for item in items: # print(item) return max(1, int(last_li.text())) except Exception : return None def crawl_one_page(doc): """ //Crawling through each page :param doc: pyquery Returned parser """ items = doc.find('[data-submission-id]').items() for item in items: it = solve_tr(item) with open('data.txt', 'a+', encoding='utf-8') as f: f.write(str(it) + '\n') print(it) def get_username(): """ //Get user name :return: """ username = input('Please enter the user name:') return username def main(): base = 'https://codeforces.com/submissions/' username = get_username() url = base+username+'/page/1' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36' } response = requests.get(url=url, headers=headers) doc = pq(response.text) # The comment section is the test code # crawl_one_page(doc) # with open('index.html', 'w', encoding='utf-8') as f: # f.write(doc.text()) num = get_pages_num(doc) if num is not None: for i in range(1, num + 1): url = base+username+'/page/'+str(i) print(url) response = requests.get(url=url) doc = pq(response.text) crawl_one_page(doc) time.sleep(2) else: print('username is no exist or you are no submission') if __name__ == '__main__': main()
The operation effect is as follows