1. Foundation construction
The implementation logic in sync.WaitGroup is quite simple. After reading the previous sync.Mutex and synx.RWMutex, it should be very simple to read them. The only difference is the state1 in sync.WaitGroup
1.1 waiting mechanism
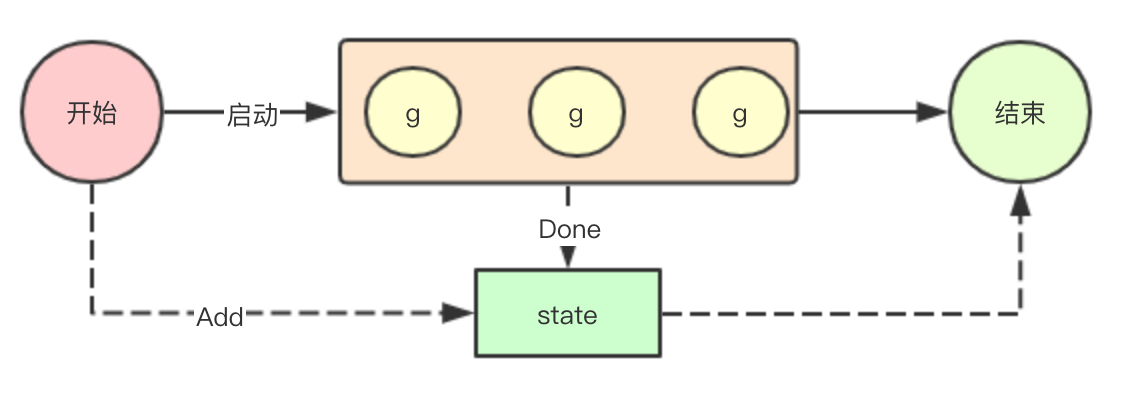 sync.WaitGroup is mainly used to wait for a group of goroutines to exit. In essence, it is a counter. We can specify the number of goroutines we need to wait for to exit by adding, and then decrease by Done. If it is 0, we can exit
sync.WaitGroup is mainly used to wait for a group of goroutines to exit. In essence, it is a counter. We can specify the number of goroutines we need to wait for to exit by adding, and then decrease by Done. If it is 0, we can exit
1.2 memory alignment
 Memory alignment is a big topic. The core mechanism of memory alignment is that the compiler performs the complement according to the size of the internal elements of the structure, combining the platform and the rules of the compiler itself. It is useful in sync.WaitGroup, and it is the most important one among all the core features of WaitGroup
Memory alignment is a big topic. The core mechanism of memory alignment is that the compiler performs the complement according to the size of the internal elements of the structure, combining the platform and the rules of the compiler itself. It is useful in sync.WaitGroup, and it is the most important one among all the core features of WaitGroup
In WaitGroup, there is only state 1 [3] uint32. By type, we can calculate that uint32 is 4 bytes, and the total length of the array of length 3 is 12. In fact, the previous place is [12]byte. Switching uint32 is a switch in go language to ensure that the underlying compiler is aligned with 4 word sections
1.38 byte
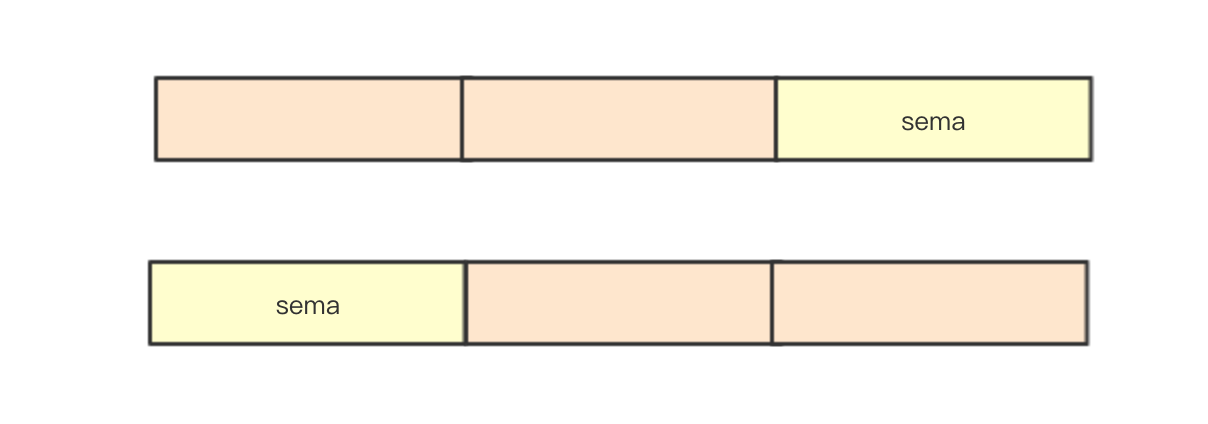 8 bytes are two 4 bytes, that is, the length of two uint32, which is actually the length of a uint64. In sync.WaitGroup, count the number of waits by using uint64
8 bytes are two 4 bytes, that is, the length of two uint32, which is actually the length of a uint64. In sync.WaitGroup, count the number of waits by using uint64
Here is a relatively hack question. I have read many articles, but I have not found the answer that can fully convince me. The next is my own conjecture
1.4 8 byte guesswork
First of all, go language needs to be compatible with 32-bit and 64 bit platforms, but the uint operation of 64 bytes on 32-bit platforms may not be atomic. For example, when reading the length of a word, the data of another word may have changed (in 32-bit operating systems, the word length is 4, while the uint64 length is 8). So when actually counting, sync.WaitGroup also uses 4 Bytes
 There is a cache line in the cpu, which is usually 8 bytes long. In intel's cpu, the operation for a cache line is atomic. If there are only 8 bytes, the above situation is likely to occur, that is, two cache lines are broken, which may cause problems in both atomic operation and performance
There is a cache line in the cpu, which is usually 8 bytes long. In intel's cpu, the operation for a cache line is atomic. If there are only 8 bytes, the above situation is likely to occur, that is, two cache lines are broken, which may cause problems in both atomic operation and performance
1.5 test 8-byte pointer
Here I simply construct an 8-byte length pointer to demonstrate. By reading the address of the pointer and offset pointer of the underlying array (the second element of state1 array is index=1), we can verify the conjecture that after memory allocation and alignment by the compiler, if the address of the pointer of the current element cannot be divided by 8, the address of the address + 4 can be divided by 8 (here It's more that I can see the real thing in the compiler layer, but I'm not interested in the compiler itself, so I just need a proof to verify the results.)
import ( "unsafe" ) type a struct { b byte } type w struct { state1 [3]uint32 } func main() { b := a{} println(unsafe.Sizeof(b), uintptr(unsafe.Pointer(&b)), uintptr(unsafe.Pointer(&b))%8 == 0) wg := w{} println(unsafe.Sizeof(wg), uintptr(unsafe.Pointer(&wg.state1)), uintptr(unsafe.Pointer(&wg.state1))%8 == 0) println(unsafe.Sizeof(wg), uintptr(unsafe.Pointer(&wg.state1[1])), uintptr(unsafe.Pointer(&wg.state1[1]))%8 == 0) }
Output result
1 824633919343 false 12 824633919356 false 12 824633919360 true
1.6 segment count
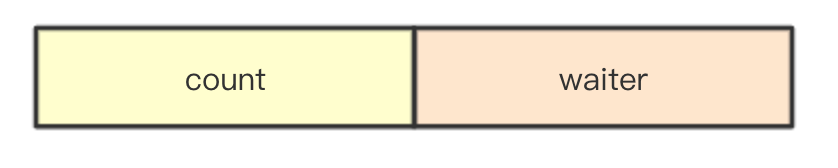 In sync.WaitGroup, the 8-byte uint64 mentioned above is also a segmented count, that is, the number of dones that need to Wait for the high-level record, while the low-level record is currently waiting for the end of the Wait count
In sync.WaitGroup, the 8-byte uint64 mentioned above is also a segmented count, that is, the number of dones that need to Wait for the high-level record, while the low-level record is currently waiting for the end of the Wait count
2. Quick reading of source code
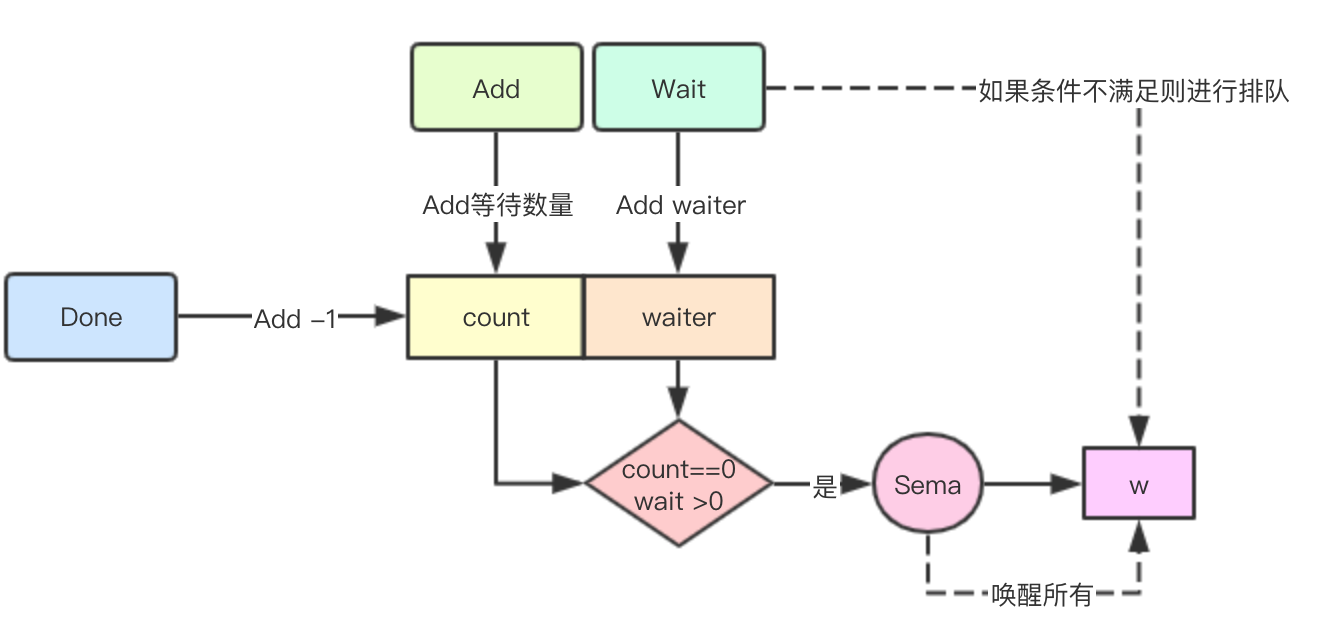 1. The core principle is to count by the previously mentioned 64 bit uint64, using the number of Done required by high-level record and the number of wait recorded by low-level record. 2. If the current count > 0, the goroutine of wait will be queued. 3. After the task is completed, the goroutine will perform the Done operation, until the count==0, then it will wake up all goroutines sleeping because of the wait operation
1. The core principle is to count by the previously mentioned 64 bit uint64, using the number of Done required by high-level record and the number of wait recorded by low-level record. 2. If the current count > 0, the goroutine of wait will be queued. 3. After the task is completed, the goroutine will perform the Done operation, until the count==0, then it will wake up all goroutines sleeping because of the wait operation
2.1 count and semaphore
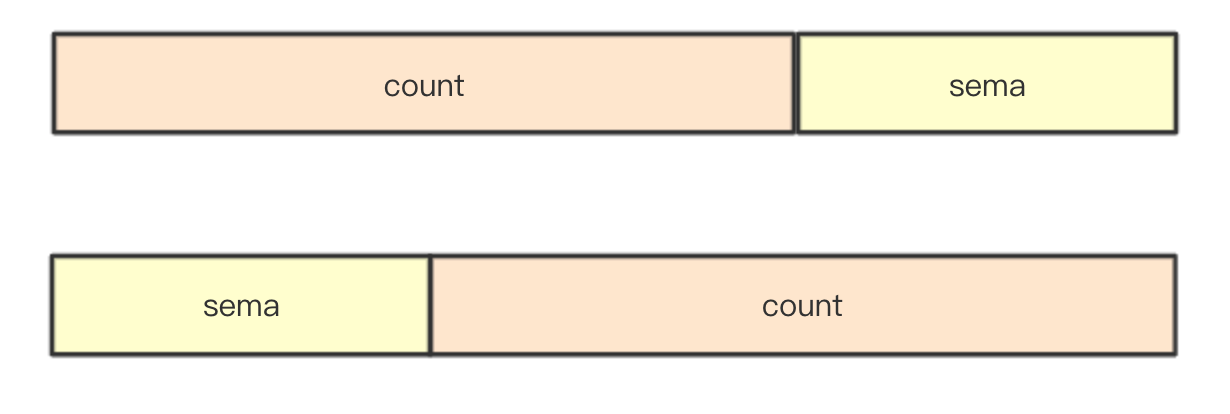 As mentioned in the basic part, for 12 byte [3]uint32, it will be calculated according to the address of the current pointer to determine which segment is used for counting and waiting as semaphore. As mentioned above in the detailed description, it is only based on the adopted segment, and then the corresponding segment will be converted into a pointer of * uint64 and a pointer of uint32
As mentioned in the basic part, for 12 byte [3]uint32, it will be calculated according to the address of the current pointer to determine which segment is used for counting and waiting as semaphore. As mentioned above in the detailed description, it is only based on the adopted segment, and then the corresponding segment will be converted into a pointer of * uint64 and a pointer of uint32
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) { if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 { return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2] } else { return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0] } }
2.2 add wait count
func (wg *WaitGroup) Add(delta int) { // Get current count statep, semap := wg.state() if race.Enabled { _ = *statep // trigger nil deref early if delta < 0 { // Synchronize decrements with Wait. race.ReleaseMerge(unsafe.Pointer(wg)) } race.Disable() defer race.Enable() } // counter count with high 32 bits state := atomic.AddUint64(statep, uint64(delta)<<32) v := int32(state >> 32) // Get the current number of done to wait for w := uint32(state) // Get the low 32 bit wait count if race.Enabled && delta > 0 && v == int32(delta) { // The first increment must be synchronized with Wait. // Need to model this as a read, because there can be // several concurrent wg.counter transitions from 0. race.Read(unsafe.Pointer(semap)) } if v < 0 { panic("sync: negative WaitGroup counter") } if w != 0 && delta > 0 && v == int32(delta) { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // If the current V > 0, it means that you need to continue the unfinished goroutine for Done operation // If w ==0, no goroutine is wait ing for the end // The above two situations can be returned directly if v > 0 || w == 0 { return } // When waiters > 0 and the current v==0, if the state changes before and after checking, then // If it is proved that someone has modified it, it will be deleted // If you go to this place, it is proved that after the previous operation, the current v==0,w!=0, it is proved that the previous round of Done has been completed. Now you need to wake up all the goroutine s in wait // At this time, if the current * statep value is found to have changed again, it is proved that someone has added it // That's WaitGroup abuse here if *statep != state { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // Set the current state to 0, and you can reuse it next time *statep = 0 for ; w != 0; w-- { // Release all queued waiter s runtime_Semrelease(semap, false) } }
2.2 Done completes a wait event
func (wg *WaitGroup) Done() { // Subtract one - 1 wg.Add(-1) }
2.3 wait for all operations to complete
func (wg *WaitGroup) Wait() { statep, semap := wg.state() if race.Enabled { _ = *statep // trigger nil deref early race.Disable() } for { // Get state state := atomic.LoadUint64(statep) v := int32(state >> 32) // Get high 32-bit count w := uint32(state) // Get the current number of waiting if v == 0 { // If the current v ==0, return directly, indicating that there is no need to wait at present // Counter is 0, no need to wait. if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(wg)) } return } // Carry out low water meter count statistics if atomic.CompareAndSwapUint64(statep, state, state+1) { if race.Enabled && w == 0 { // Wait must be synchronized with the first Add. // Need to model this is as a write to race with the read in Add. // As a consequence, can do the write only for the first waiter, // otherwise concurrent Waits will race with each other. race.Write(unsafe.Pointer(semap)) } // If it succeeds, it will sleep in queue and wait for wakeup runtime_Semacquire(semap) // If the state is found to be not 0 after wake-up, it is proved that WaitGroup is reused during wake-up, then panic if *statep != 0 { panic("sync: WaitGroup is reused before previous Wait has returned") } if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(wg)) } return } } }
Reference articles
About the size of cpu cache line Atomic operation
Pay attention to the bulletin number to read more source code analysis articles
More articles www.sreguide.com
This article is published by one article multiple platform ArtiPub Automatic publishing