Last blog shared mapreduce's programming ideas. In this section, the blogger will take his friends to understand the principle of wordcount program and the details of code implementation / operation. Through this section, we can have a general understanding of map reduce program. In fact, map and reduce programs in hadoop are only two of them. The rest components (such as input/output) can also be rewritten. By default, the default component is used.
1. Implementation of wordcount statistical program:
WordcountMapper (map task business implementation)
package com.empire.hadoop.mr.wcdemo; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN: By default, it is the starting offset of a line of text read by the mr frame, Long, * But in hadoop, it has its own more compact serialization interface, so instead of using Long directly, it uses LongWritable * VALUEIN:By default, it is the content of a line of Text read by mr frame, String, as above, with Text * KEYOUT: It is the key in the output data after the user-defined logic processing is completed. Here is the word, String, the same as above, and Text * VALUEOUT: It is the value in the output data after the user-defined logic processing is completed. Here is the number of words, Integer, ditto, and IntWritable * * @author */ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * map The business logic of the phase is written in the custom map() method. maptask will call our custom map() method once for each row of input data */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Convert the text content passed to us by maptask to String first String line = value.toString(); //Cut the line into words according to the space String[] words = line.split(" "); //Output word as < word, 1 > for (String word : words) { //Use the word as the key and the number of times 1 as the value for subsequent data distribution. You can distribute according to the word so that the same word can get the same reduce task context.write(new Text(word), new IntWritable(1)); } } }
WordcountReducer (implementation of reduce business code)
package com.empire.hadoop.mr.wcdemo; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * KEYIN, VALUEIN The keyout and valueout types corresponding to the mapper output correspond to keyout and valueout * Is the output data type of the custom reduce logic processing result KEYOUT is the word VLAUEOUT is the total number of times * * @author */ public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * <angelababy,1><angelababy,1><angelababy,1><angelababy,1><angelababy,1> * <hello,1><hello,1><hello,1><hello,1><hello,1><hello,1> * <banana,1><banana,1><banana,1><banana,1><banana,1><banana,1> * Enter the key, which is a group of keys with the same word kv pair */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; /* * Iterator<IntWritable> iterator = values.iterator(); * while(iterator.hasNext()){ count += iterator.next().get(); } */ for (IntWritable value : values) { count += value.get(); } context.write(key, new IntWritable(count)); } }
WordcountDriver (the program that submits yarn)
package com.empire.hadoop.mr.wcdemo; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * The client of a yarn cluster needs to encapsulate the relevant running parameters of our mr program, specify the jar package and submit it to yarn * * @author */ public class WordcountDriver { public static void main(String[] args) throws Exception { if (args == null || args.length == 0) { args = new String[2]; args[0] = "hdfs://master:9000/wordcount/input/wordcount.txt"; args[1] = "hdfs://master:9000/wordcount/output8"; } Configuration conf = new Configuration(); //The settings are useless?????? // conf.set("HADOOP_USER_NAME", "hadoop"); // conf.set("dfs.permissions.enabled", "false"); /* * conf.set("mapreduce.framework.name", "yarn"); * conf.set("yarn.resoucemanager.hostname", "mini1"); */ Job job = Job.getInstance(conf); /* job.setJar("/home/hadoop/wc.jar"); */ //Specify the local path of the jar package of this program job.setJarByClass(WordcountDriver.class); //Specify the mapper/Reducer business class to be used by this business job job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); //Specifies the kv type of mapper output data job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //Specifies the kv type of the final output data job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //Specify the directory of the original input file of the job FileInputFormat.setInputPaths(job, new Path(args[0])); //Specify the directory where the output of the job is located FileOutputFormat.setOutputPath(job, new Path(args[1])); //Submit the relevant parameters configured in the job and the jar package of the java class used in the job to yarn for running /* job.submit(); */ boolean res = job.waitForCompletion(true); //In the linux shell script, if the previous command returns 0, it means success; otherwise, it means failure System.exit(res ? 0 : 1); } }
Run mapreduce
Packaging of jar
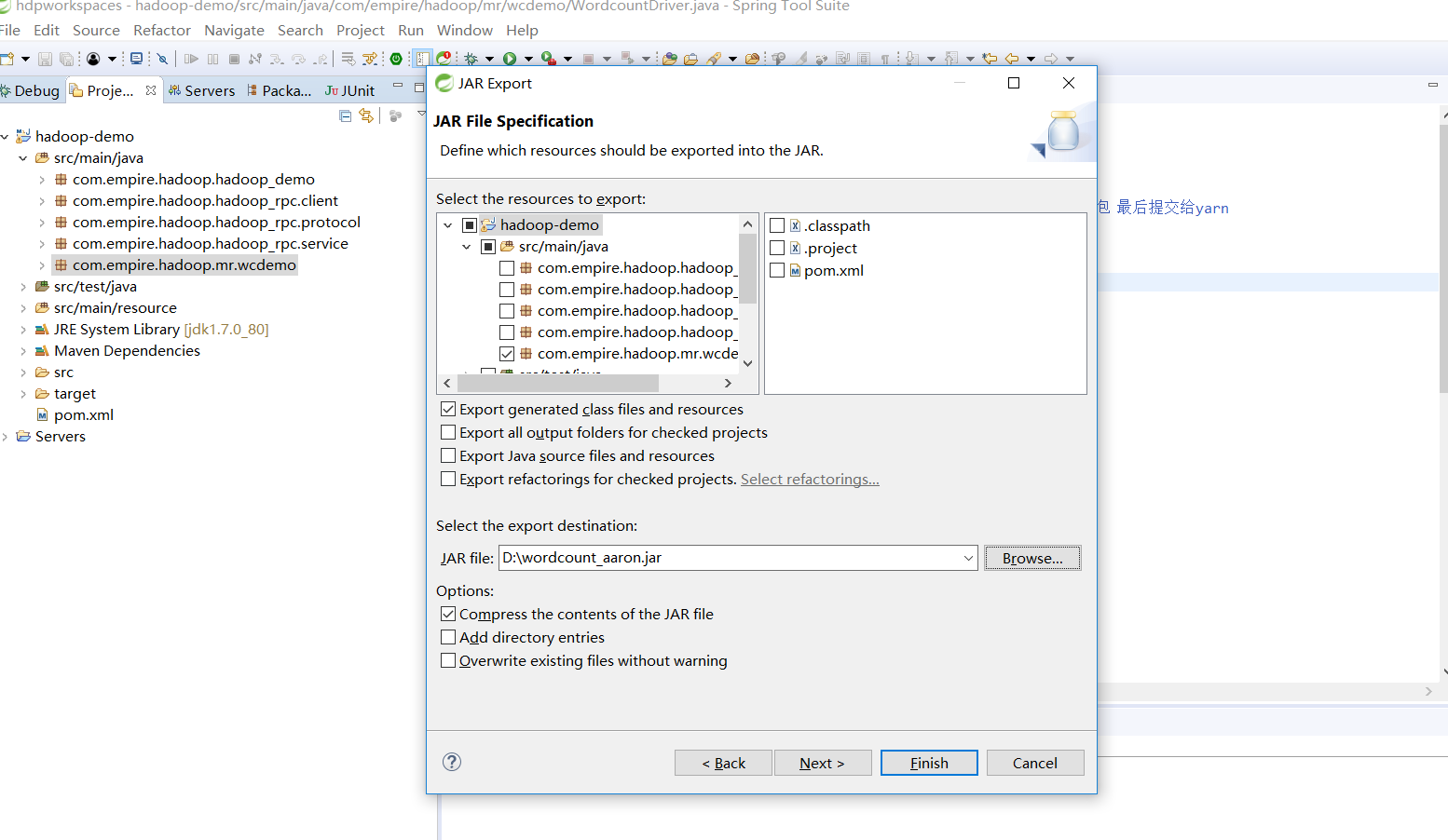
Upload (2) to hadoop cluster and run
#Upload jar Alt+p lcd d:/ put wordcount_aaron.jar #Preparing data files for hadoop processing cd /home/hadoop/apps/hadoop-2.9.1 hadoop fs -mkdir -p /wordcount/input hadoop fs -put LICENSE.txt NOTICE.txt /wordcount/input #Run the wordcount program hadoop jar wordcount_aaron.jar com.empire.hadoop.mr.wcdemo.WordcountDriver /wordcount/input /wordcount/outputs
Operation rendering:
[hadoop@centos-aaron-h1 ~]$ hadoop jar wordcount_aaron.jar com.empire.hadoop.mr.wcdemo.WordcountDriver /wordcount/input /wordcount/output 18/11/19 22:48:54 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032 18/11/19 22:48:55 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 18/11/19 22:48:55 INFO input.FileInputFormat: Total input files to process : 2 18/11/19 22:48:55 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1280) at java.lang.Thread.join(Thread.java:1354) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:980) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:630) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:807) 18/11/19 22:48:55 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1280) at java.lang.Thread.join(Thread.java:1354) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:980) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:630) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:807) 18/11/19 22:48:55 INFO mapreduce.JobSubmitter: number of splits:2 18/11/19 22:48:55 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled 18/11/19 22:48:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1542637441480_0002 18/11/19 22:48:56 INFO impl.YarnClientImpl: Submitted application application_1542637441480_0002 18/11/19 22:48:56 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1542637441480_0002/ 18/11/19 22:48:56 INFO mapreduce.Job: Running job: job_1542637441480_0002 18/11/19 22:49:03 INFO mapreduce.Job: Job job_1542637441480_0002 running in uber mode : false 18/11/19 22:49:03 INFO mapreduce.Job: map 0% reduce 0% 18/11/19 22:49:09 INFO mapreduce.Job: map 100% reduce 0% 18/11/19 22:49:14 INFO mapreduce.Job: map 100% reduce 100% 18/11/19 22:49:15 INFO mapreduce.Job: Job job_1542637441480_0002 completed successfully 18/11/19 22:49:15 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=241219 FILE: Number of bytes written=1074952 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=122364 HDFS: Number of bytes written=35348 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=7588 Total time spent by all reduces in occupied slots (ms)=3742 Total time spent by all map tasks (ms)=7588 Total time spent by all reduce tasks (ms)=3742 Total vcore-milliseconds taken by all map tasks=7588 Total vcore-milliseconds taken by all reduce tasks=3742 Total megabyte-milliseconds taken by all map tasks=7770112 Total megabyte-milliseconds taken by all reduce tasks=3831808 Map-Reduce Framework Map input records=2430 Map output records=19848 Map output bytes=201516 Map output materialized bytes=241225 Input split bytes=239 Combine input records=0 Combine output records=0 Reduce input groups=2794 Reduce shuffle bytes=241225 Reduce input records=19848 Reduce output records=2794 Spilled Records=39696 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=332 CPU time spent (ms)=2830 Physical memory (bytes) snapshot=557314048 Virtual memory (bytes) snapshot=2538102784 Total committed heap usage (bytes)=259411968 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=122125 File Output Format Counters Bytes Written=35348
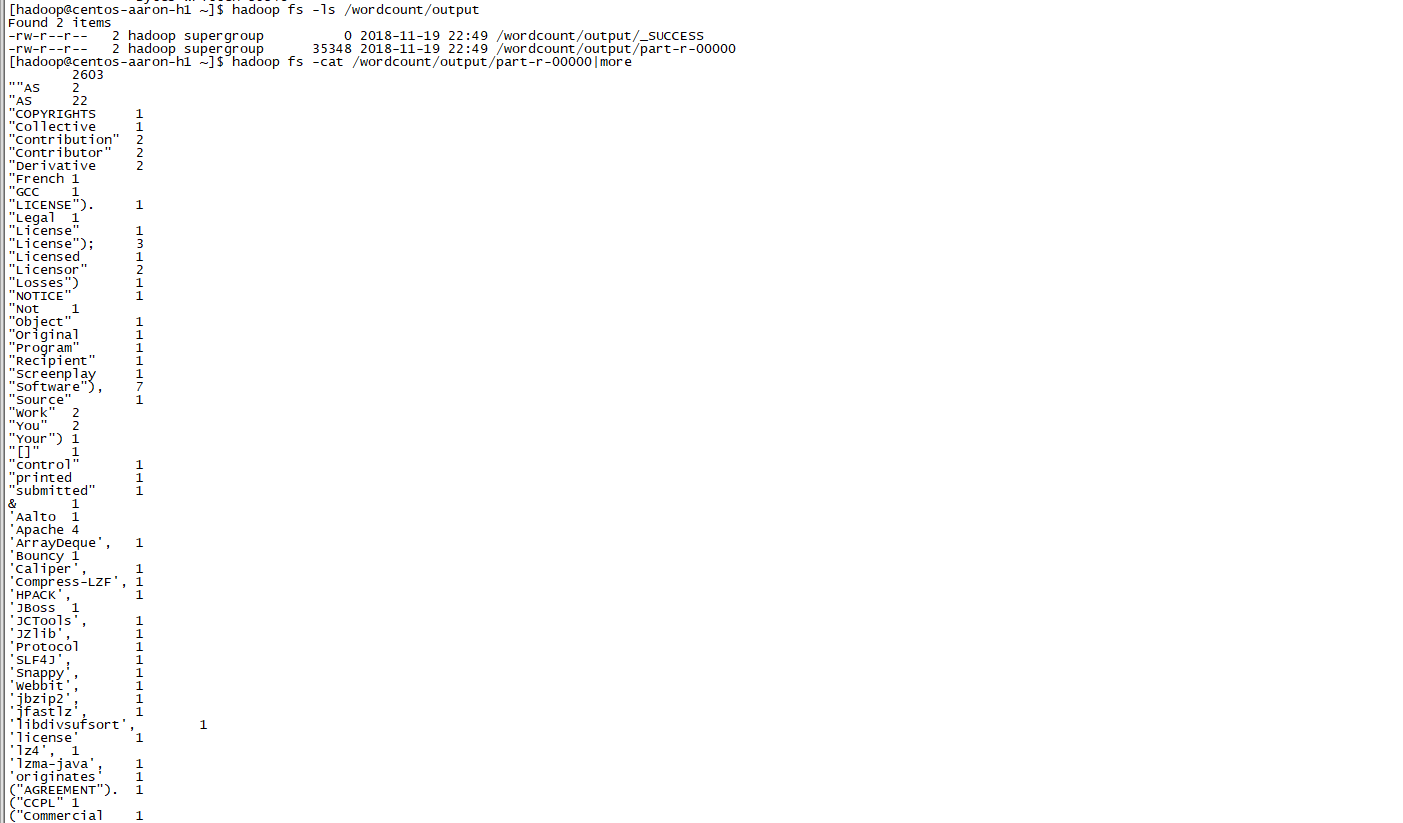
Run results:
#View processing result file hadoop fs -ls /wordcount/output hadoop fs -cat /wordcount/output/part-r-00000|more
Problem solving:
18/11/19 22:48:55 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1280) at java.lang.Thread.join(Thread.java:1354) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:980) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:630) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:807)
The above error occurred because we didn't create the new hdfs directory according to the official document, which is not a big problem; the blogger didn't affect the normal use;
Solution:
#Create directory hdfs dfs -mkdir -p /user/hadoop hdfs dfs -put NOTICE.txt LICENSE.txt /user/hadoop
The last message is all the content of this blog post. If you think the blog post is good, please like it. If you are interested in big data technology of other servers of the blogger or the blogger himself, please pay attention to the blogger's blog, and you are welcome to communicate with the blogger at any time.