This is a sample function that combines the previous studies, including the definition of data, the definition of variables, the forward propagation and back propagation of neural network. However, the loss function and back propagation algorithm will continue to learn further in the later study, which is currently written first.
import tensorflow as tf
#Numpy is a toolkit for scientific computing. Here, the simulation data set is generated through numpy toolkit
from numpy.random import RandomState
#Define the size of the training data set
batch_size = 8
#Defining parameters of neural network
w1 = tf.Variable(tf.random_normal([2,3],stddev = 1,seed = 1))
w2 = tf.Variable(tf.random_normal([3,1],stddev = 1,seed = 1))
#Using None in one dimension of shape makes it easy to use different batch sizes. In training, we need to divide the data into smaller batches
#But when testing, you can use all the data at once. When the data set is small, it is convenient to test, but when the data set is large, a large amount of data will be put into batch, which will lead to memory overflow
x = tf.placeholder(tf.float32,shape=(None,2),name= 'x_input')
y_ = tf.placeholder(tf.float32,shape=(None,1),name= 'y_input')
#Define the process of neural network forward propagation
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#Define loss function and back propagation algorithm
y = tf.sigmoid(y)
cross_entropy = -tf.reduce_mean(
y_ * tf.log(tf.clip_by_value(y,1e-10,1.0))
+(1-y_) * tf.log(tf.clip_by_value(1-y,1e-10,1.0))
)
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#Generating a simulation data set by random number
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size,2)
#Define rules to give labels of samples. All samples with X1 + x2 < 1 are considered as positive samples (such as qualified parts),
#The others are negative samples (such as unqualified parts). What's different from the representation in tensorflow playground is that
#Here we use 0 for negative samples and 1 for positive samples. Most neural networks that solve classification problems use 0 and 1
Y = [[int(x1 + x2 < 1)] for (x1,x2) in X]
#Create a session to run the tensorflow program
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
#initialize variable
sess.run(init_op)
print(sess.run(w1))
print(sess.run(w2))
#Set the number of rounds of training
STEPS = 5000
for i in range(STEPS):
#Each time, select batch ﹐ size samples for training
start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
#Training neural network to update parameters through selected samples
sess.run(train_step,feed_dict={x: X[start:end],y_: Y[start:end]})
if i % 1000 == 0:
#Calculate the cross entropy on all data at regular intervals and output
total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y})
print("After %d train step(s),cross entropy on all data is %g",i,total_cross_entropy)
#Parameters of trained neural network
print(sess.run(w1))
print(sess.run(w2))
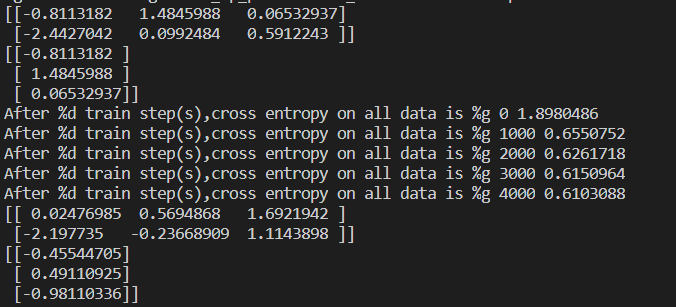
This is the result of the output, the first w1,w2, the reduced cross entropy of continuous learning and the parameters w1,w2 after learning.