I. environment construction
1. Install chrome driver
brew cask install chromedriver
2. Install selenium
pip3 install selenium
3. Install beautiful soup4
pip3 install beautifulsoup4
4. Test with the following code
from selenium import webdriver
driver = webdriver.Chrome() # The chrome browser is called here
driver.get('https://www.baidu.com')
print(driver.title)
driver.quit()5. if you report wrong
raise WebDriverException("Can not connect to the Service %s" % self.path) selenium.common.exceptions.WebDriverException: Message: Can not connect to the Service /usr/local/bin/chromedriverThere are two solutions:
a) make sure your chrome driver is in your environment variable directory
My storage directory: usr/local/bin/chromedriver
Check method: enter which chromedriver in terminal
b) if 127.0.0.1 localhost is missing, Cannot connect to the service... Error will appear
Check mode: ping localhost
host Directory: / private/etc/
Use vim to modify.
6. If the error is reported, the version of chrome does not match
Enter in the browser address barchrome://version/ View chrome version
Go to the official website of chrome driver to view the corresponding version and download the corresponding chrome driver: https://sites.google.com/a/chromium.org/chromedriver/ , download to local, and extract to / usr/local/bin / folder.
2. Obtain search results and related keywords marked in red
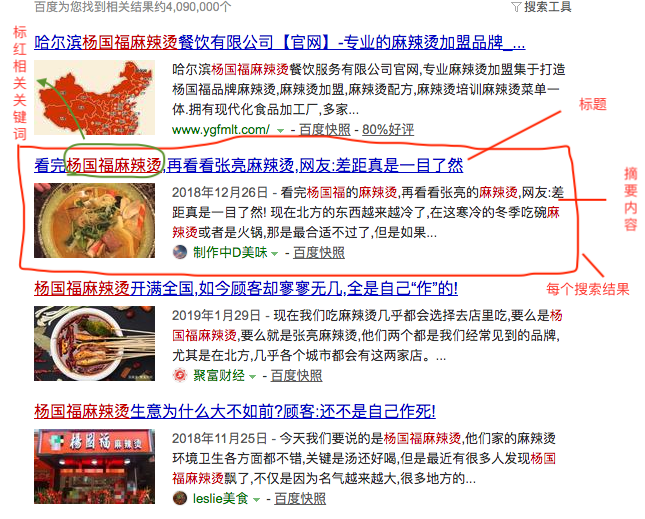
Use the following code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import StaleElementReferenceException
from bs4 import BeautifulSoup
browser_path = "/usr/local/bin/chromedriver"
browser = webdriver.Chrome(browser_path)
browser.get('https://www.baidu.com')
browser_input = browser.find_element_by_id('kw')
browser_input.clear()
query = "Yang Guofu, spicy hot "
browser_input.send_keys(query)
browser_input.send_keys(Keys.RETURN)
ignored_exceptions = (NoSuchElementException, StaleElementReferenceException,)
try:
WebDriverWait(browser, 10, ignored_exceptions=ignored_exceptions) \
.until(EC.title_contains(query))
except:
continue
# Using beautifulsop to parse search results
bsobj = BeautifulSoup(browser.page_source, features="html.parser")
# Get search results queue
search_results = bsobj.find_all('div', {'class': 'result c-container'})
# For each search result
for item in search_results:
# Get all text for the title of each search result
text = search_item.h3.a.get_text(strip=True)
# Get the red key for the title of each search result
keywords = search_item.h3.a.find_all('em')
# Get all text in the summary content of each search result
# text = search_item.div.get_text(strip=True)
# Get the red keywords in the summary content of each search result
# keywords = search_item.div.find_all('em')
print(text)
print(keywords)
browser.close()
Reference website: https://blog.csdn.net/Excaliburrr/article/details/79164163