Alibaba P7 mobile Internet architect advanced video (in daily update) for free, please click: https://space.bilibili.com/474380680
This article will introduce the automatic build system Gradle as follows:
- The relationship between gradle and android gradle plug-in
- Basic use of the Gradle Transform API
I. The relationship between gradle and android gradle plug-ins
1.1 explanation of terms:
1.1.1,Gradle
Gradle is a build tool that uses a Groovy based domain specific language (DSL) to build projects. It's not just for building android projects.
1.1.2,Android Plugin for Gradle
This is a plug-in developed to compile android projects. Here's where to declare the Android Gradle plug-in. (build.gradle)
buildscript { ... dependencies { classpath 'com.android.tools.build:gradle:2.2.0' } }
1.2 gradle and android gradle
1.2.1 source code address of each version of gradle
http://services.gradle.org/distributions/
1.2.2. Address of comparison between gradle plug-in and gradle version on Google official website
https://developer.android.google.cn/studio/releases/gradle-plugin#updating-plugin

1.2.3 differences between gradle version and google gradle plug-in version
The version of gradle is written in gradle wrapper.properties.
distributionUrl=https\://services.gradle.org/distributions/gradle-4.4-all.zip
In build.gradle, we rely on the version of the gradle plug-in.
dependencies { //[this is the android gradle plugin version] classpath 'com.android.tools.build:gradle:3.1.0' // NOTE: Do not place your application dependencies here; they belong // in the individual module build.gradle files }
II. Basic use of the Gradle Transform API
2.1 what is Transform
Official API documentation: http://google.github.io/android-gradle-dsl/javadoc/2.1/com/android/build/api/transform/Transform.html
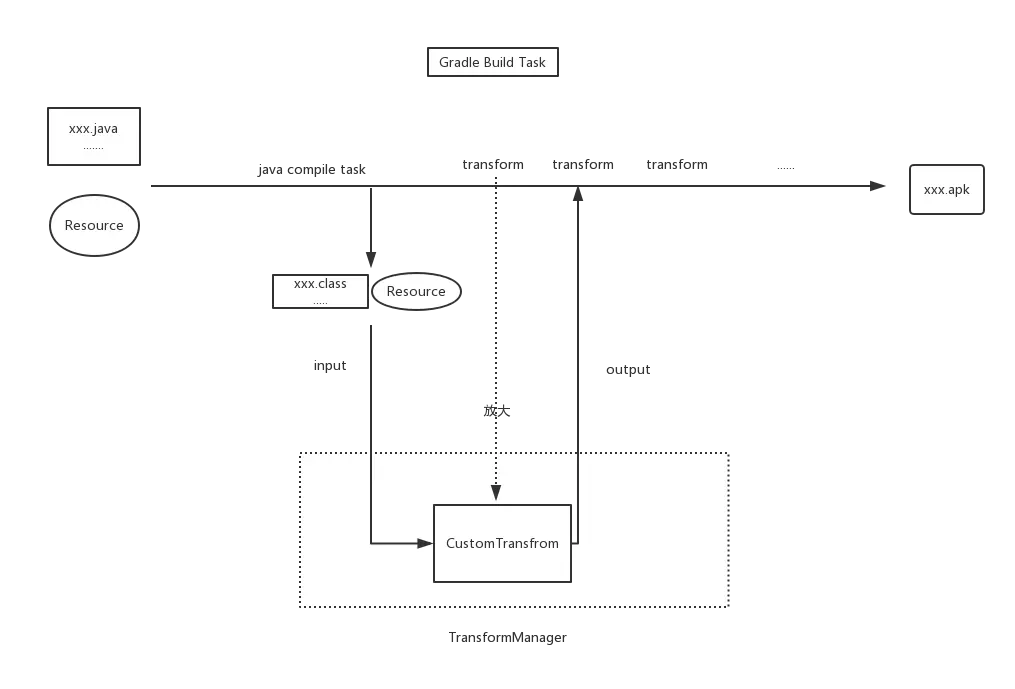
When compiling Android projects, if we want to get the Class files generated during compilation and do some processing before generating Dex, we can receive these inputs (Class files generated during compilation) by writing a Transform, and add some things to the generated inputs.
We can register the Transform we wrote through the Gradle plug-in. After registration, the Transform will be wrapped by Gradle as a Gradle Task, which will run after the java compile Task is executed.
To write the Transform API, we can use it by introducing the following dependency:
compile 'com.android.tools.build:gradle:2.3.3' //Version should be above 2.x
First, take a look at the execution flow chart of Transform
2.2 usage scenarios of transform
Generally, there are two scenarios when we use Transform
- We need to do custom processing for the compiled class file.
- We need to read the class file generated by compilation and do some other things, but we don't need to modify it.
Let's take a look at these transform APIs:
2.3 Transform API learning
To write a custom Transform, we need to inherit Transform, which is an abstract class. Let's take a look at the abstract methods of Transform:
public abstract class Transform { public abstract String getName(); public abstract Set<ContentType> getInputTypes(); public abstract Set<? super Scope> getScopes(); public abstract boolean isIncremental(); // Incremental compilation supported }
getName() is the name of the specified custom Transform.
2.4 type of input
Set < contenttype > getinputtypes() indicates the input type of the Transform process you customized. The input types are as follows:
enum DefaultContentType implements ContentType { /** * The content is compiled Java code. This can be in a Jar file or in a folder. If * in a folder, it is expected to in sub-folders matching package names. */ CLASSES(0x01), /** * The content is standard Java resources. */ RESOURCES(0x02); }
It is divided into class files or java resources. Class files come from jar s or folders. Resources are standard java resources.
2.5 Scope of input file
getScopes() is used to indicate the scope of the input file of the custom Transform, because gradle supports multi engineering compilation. There are the following:
/** * This indicates what the content represents, so that Transforms can apply to only part(s) * of the classes or resources that the build manipulates. */ enum Scope implements ScopeType { /** Only the project content */ PROJECT(0x01), //Only the code of the current project /** Only the project's local dependencies (local jars) */ PROJECT_LOCAL_DEPS(0x02), // Local jar of project /** Only the sub-projects. */ SUB_PROJECTS(0x04), // Only sub works are included /** Only the sub-projects's local dependencies (local jars). */ SUB_PROJECTS_LOCAL_DEPS(0x08), /** Only the external libraries */ EXTERNAL_LIBRARIES(0x10), /** Code that is being tested by the current variant, including dependencies */ TESTED_CODE(0x20), /** Local or remote dependencies that are provided-only */ PROVIDED_ONLY(0x40); }
For the return of getScopes(), in fact, TransformManager has defined some for us, such as:
public static final Set<Scope> SCOPE_FULL_PROJECT = Sets.immutableEnumSet( Scope.PROJECT, Scope.PROJECT_LOCAL_DEPS, Scope.SUB_PROJECTS, Scope.SUB_PROJECTS_LOCAL_DEPS, Scope.EXTERNAL_LIBRARIES);
If a Transform does not want to process any input but only wants to view the content of the input, it only needs to return an empty set in getScopes(), and return the range it wants to receive in getReferencedScopes().
public Set<? super Scope> getReferencedScopes() { return ImmutableSet.of(); }
2.6 transform()
It is the key method of Transform:
public void transform(@NonNull TransformInvocation transformInvocation) {}
It is an empty implementation, and the content of input will be packaged into a TransformInvocation object, because if we want to use input, we need to understand the TransformInvocation parameter in detail.
2.7 TransformInvocation
Let's take a look at the API related to this class:
public interface TransformInvocation { Collection<TransformInput> getInputs(); // Input returned as TransformInput TransformOutputProvider getOutputProvider(); //Transformeoutputprovider can be used to create output content boolean isIncremental(); } public interface TransformInput { Collection<JarInput> getJarInputs(); Collection<DirectoryInput> getDirectoryInputs(); } public interface JarInput extends QualifiedContent { File getFile(); //jar file Set<ContentType> getContentTypes(); // class or resource Set<? super Scope> getScopes(); //Of Scope: } DirectoryInput And JarInput The definitions are basically the same. public interface TransformOutputProvider { //Return the corresponding file (jar / directory) according to name, ContentType and QualifiedContent.Scope File getContentLocation(String name, Set<QualifiedContent.ContentType> types, Set<? super QualifiedContent.Scope> scopes, Format format); }
That is to say, we can get the input through TransformInvocation, and also get the output function. for instance,
public void transform(TransformInvocation invocation) { for (TransformInput input : invocation.getInputs()) { input.getJarInputs().parallelStream().forEach(jarInput -> { File src = jarInput.getFile(); JarFile jarFile = new JarFile(file); Enumeration<JarEntry> entries = jarFile.entries(); while (entries.hasMoreElements()) { JarEntry entry = entries.nextElement(); //Handle } } }
The above code is to get the jar input, and then traverse each jar to do some custom processing.
What do we do if we want to output something by ourselves after the custom processing For example, a class file can be completed through transformeoutputprovider. For example, the following code:
File dest = invocation.getOutputProvider().getContentLocation("susion", TransformManager.CONTENT_CLASS, ImmutableSet.of(QualifiedContent.Scope.PROJECT), Format.DIRECTORY;
This code is to generate a directory (Format.DIRECTORY) under the project (ImmutableSet.of(QualifiedContent.Scope.PROJECT)). The name of the directory is (fusion), and the content is transformanager. Content? Class.
After creating this folder, we can write some contents to it, such as class files.
2.8 register Transform
After we understand the transform api, we can write a custom Transform. But how does the Transform we wrote take effect in the build process? We need to register it
Register it in the custom plug-in and apply it in build.gradle.
//MyCustomPlgin.groovy public class MyCustomPlgin implements Plugin<Project> { @Override public void apply(Project project) { project.getExtensions().findByType(BaseExtension.class) .registerTransform(new MyCustomTransform()); } }
In fact, if you include the transform library you wrote, we can also register directly in build.gradle:
//You can also write groovy code directly in build.gradle. project.extensions.findByType(BaseExtension.class).registerTransform(new MyCustomTransform());
Reference resources: https://www.jianshu.com/p/031b62d02607
https://my.oschina.net/u/592116/blog/1851743
Alibaba P7 mobile Internet architect advanced video (in daily update) for free, please click: https://space.bilibili.com/474380680
Concluding remarks
I hope you can forward and share and pay attention to me after reading this. In the future, you will continue to share advanced knowledge points and analysis of Alibaba P7 Android advanced architecture. Your support is my biggest motivation!!
