introduction
Go builds a simple and high-performance native network model (I/O multiplexing netpoll based on go) based on I/O multiplexing and goroutine, which provides a simple network programming mode such as goroutine per connection. In this mode, developers use the synchronous mode to write asynchronous logic, which greatly reduces the mental burden of developers when writing network applications. With the help of the efficient scheduling of goroutines by the Go runtime scheduler, this native network model can meet most of the application scenarios in terms of applicability and performance.
However, it can achieve such high universality and compatibility in engineering, and finally expose to developers such a simple interface / pattern. The underlying layer must be based on very complex encapsulation, making many choices, and possibly giving up some "extreme" design and concept. In fact, the underlying layer of netpol is based on epoll/kqueue/iocp, which is used for encapsulation. Finally, it exposes the simple development mode of goroutine per connection to users.
In different operating systems, the I/O multiplexing technology used in the bottom layer of Go netpoll is also different. You can understand the implementation of the network I/O mode of Go in different platforms from the source directory structure and corresponding code files of Go. For example, epoll based on Linux system, kqueue based on freeBSD system, and iocp based on Windows system.
This paper will analyze how the bottom layer of I/O multiplexing of Go netpol is realized based on epoll encapsulation based on linux platform, and comprehensively and deeply analyze the design concept and implementation principle of Go netpol from the source level, as well as how Go uses netpol to build its native network model. I will try my best to explain some of the main concepts involved: I/O mode, user / kernel space, epoll, linux source code, goroutine scheduler, etc. if there are students who are not familiar with the relevant concepts, I hope to be familiar with them in advance.
User space and kernel space
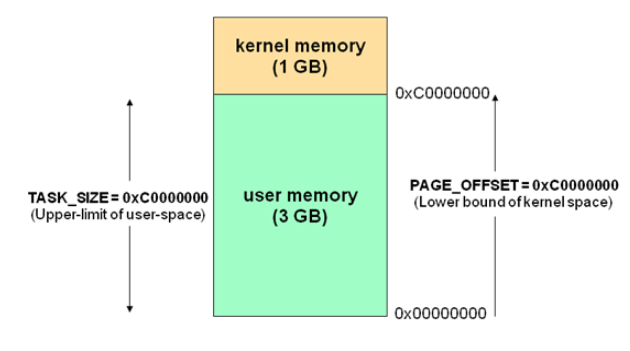
Now operating systems use virtual storage, so for 32-bit operating systems, its addressing space (virtual storage space) is 4G (32 power of 2). The core of the operating system is the kernel, which is independent of ordinary applications. It can access the protected memory space and all the permissions of the underlying hardware devices. In order to ensure that the user process can not directly operate the kernel and ensure the security of the kernel, the worry system divides the virtual space into two parts, one is the kernel space and the other is the user space. For linux operating system, the highest 1G bytes (from virtual address 0xC0000000 to 0xFFFFFF) are used by kernel, which is called kernel space, while the lower 3G bytes (from virtual address 0x00000000 to 0xbfffff) are used by each process, which is called user space.
I/O multiplexing
In the masterpiece UNIX network programming, five I/O models are summarized, including synchronous and asynchronous I/O
- Blocking I / O
- Nonblocking I / O
- I/O multiplexing
- Signal driven I / O
- Asynchronous I / O
I/O on the operating system is the data interaction between user space and kernel space, so I/O operations usually include the following two steps:
- Wait for network data to arrive at network card (read ready) / wait for network card to be writable (write ready) – > read / write to kernel buffer
- Copy data from kernel buffer – > user space (read) / copy data from user space - > kernel buffer (write)
To determine whether an I/O model is synchronous or asynchronous, the second step is to determine whether the current process will be blocked when the data is copied between the user and the kernel space. If so, it is synchronous I/O. otherwise, it is Asynchronous I/O. Based on this principle, there is only one Asynchronous I/O model among the five I/O models: Asynchronous I/O, and the rest are synchronous I/O models.
The five I/O models are compared as follows:

The so-called I/O multiplexing refers to a series of multiplexers such as select/poll/epoll: it supports a single thread to listen to multiple file descriptors (I/O events) at the same time, block and wait, and receive notification when one of the file descriptors is readable and writable In fact, I/O multiplexing does not reuse I/O connections, but reuse threads, so that one thread of control can handle multiple connections (I/O events).
select & poll
#include <sys/select.h> /* According to earlier standards */ #include <sys/time.h> #include <sys/types.h> #include <unistd.h> int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); // Four macros closely combined with select: void FD_CLR(int fd, fd_set *set); int FD_ISSET(int fd, fd_set *set); void FD_SET(int fd, fd_set *set); void FD_ZERO(fd_set *set);
select is an I/O event driven technology used by linux before epoll.
The key to understanding select is to understand fd set. For the convenience of explanation, take the length of fd set as 1 byte, each bit in fd set can correspond to a file descriptor fd, and the maximum of 8 FDS can correspond to the 1 byte fd set. The call process of select is as follows:
- Execute fd_zero (& set), then set is represented by bit as 00000000
- If FD = 5, execute fd_set (FD, & set); then set becomes 00010000 (the 5th position is 1)
- Add fd = 2, fd=1, then set becomes 00010011
- Execute select (6, & set, 0, 0, 0) block wait
- If read events occur on FD = 1 and FD = 2, select returns, and then set becomes 00000011 (Note: fd=5 without event is cleared)
Based on the above call process, we can get the characteristics of select:
- The number of file descriptors that can be monitored depends on the value of sizeof (FD Fu set). Assuming sizeof(fd_set) = 512 on the server, and each bit represents a file descriptor, the maximum supported file descriptor on the server is 512 * 8 = 4096. The sizing of FD set can be referred to Network model of [original] Technology Series (2) Model 2 in can effectively break through the upper limit of file descriptors that can be monitored by select
- When fd is added to the select monitoring set, a data structure, array, is also used to save the fd stored in the select monitoring set. First, after the select returns, array is used as the source data and fd set to judge fd isset. Second, after the selection returns, the previously added fd that has no event will be cleared. Before each start of the selection, we need to retrieve the fd from the array one by one (fd [zero first). While scanning the array, we get the maximum value of fd maxfd, which is used for the first parameter of the selection
- It can be seen that the select model must cycle array before select (add FD, take maxfd), and cycle array after select (FD_ISSET determines whether there is an event)
Therefore, select has the following disadvantages:
- Limit of maximum concurrent number: 32 bits of 32 integers, that is, 32 * 32 = 1024, are used to identify fd. Although it can be modified, there are bottlenecks in points 2 and 3 below
- Every time you call select, you need to copy the fd set from the user state to the kernel state. This overhead is great when there are many FDS
- Serious performance degradation: each kernel needs to scan the entire fd_set linearly, so as the number of monitored descriptors FD increases, its I/O performance will decline linearly
The implementation of poll is very similar to that of select, but the way to describe fd set is different. Poll uses the pollfd structure instead of the fd set structure of select. Poll solves the problem of the maximum number of file descriptors. However, it also needs to copy all fd from user state to kernel state, and it also needs to traverse all fd sets linearly, so it and select are only implementation details There is no essential difference.
epoll
Epoll is a new I/O event driven technology introduced after linux kernel 2.6. The core design of I/O multiplexing is that one thread handles all the waiting messages of the connection and prepares the I/O events. On this point, epoll and select & poll are similar. But the prediction of select & poll is wrong. When hundreds of thousands of concurrent connections exist, there may be only hundreds of active connections per millisecond, and the remaining 100000 connections are inactive in this millisecond. Select & poll is used as follows: returned active connection = = select (all connections to be monitored).
When will select & poll be called? It should be called when you think it is necessary to find the active connection with message arrival. Therefore, select poll is called frequently in high concurrency. In this way, it is necessary for this frequently called method to see whether it is efficient, because its slight efficiency loss will be magnified by the high frequency two words. Does it lose efficiency? Obviously, there are hundreds of thousands of connections to be monitored, and only hundreds of active connections are returned, which is an inefficient performance in itself. After being magnified, it will be found that when processing tens of thousands of concurrent connections, select & poll will not be able to do its best. It's time for epoll to play. Epoll has basically solved the problem of select poll through some new designs and optimizations.
epoll's API is very simple, involving only three system calls:
#include <sys/epoll.h> int epoll_create(int size); // int epoll_create1(int flags); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
Among them, epoll ﹣ create creates an epoll instance and returns epollfd; epoll ﹣ CTL registers the I/O events waiting for file descriptor (such as EPOLLIN, EPOLLOUT, etc.) to the epoll instance; epoll ﹣ wait is the I/O event blocking and listening for all file descriptors on the epoll instance, which receives a block of memory address (events array) in the user space. The kernel will receive a block of memory address (events array) in the user space When the I/O event occurs, copy the file descriptor list to this memory address, and then epoll wait to unblock and return. Finally, the program in user space can read and write the corresponding fd:
#include <unistd.h> ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count);
The working principle of epoll is as follows:

Compared with select poll, epoll distinguishes between high frequency call and low frequency call. For example, epoll UU CTL is called relatively infrequently, while epoll UU wait is called very frequently. Therefore, epoll uses epoll < CTL to insert or delete an fd and realize the data copy from user state to kernel state, which ensures that each fd only needs to be copied once in its life cycle, rather than every time epoll < wait is called Epoll [wait] is designed to call with almost no input parameters. Compared with select & poll, which needs to copy all monitored fd sets from user state to kernel state, the efficiency of epoll is much higher.
In the implementation, epoll uses red black tree to store all monitored FDS, while red black tree itself has stable insertion and deletion performance and time complexity O(logN). All the FDS added through the epoll · CTL function will be placed in a node of the red black tree, so it is useless to add repeatedly. When the fd is added, the key step will be completed: the fd will establish a callback relationship with the corresponding device (network card) driver, that is, the kernel interrupt handler registers a callback function for it. After the corresponding event of the fd is triggered (interrupted) (set up), the kernel will call the callback function, which is called by the kernel It is called: EP ﹣ poll ﹣ callback. This callback function is actually to add fd to rdllist (ready list). Epoll [wait] is actually to check whether there is ready fd in the rdlist bidirectional linked list. When the rdlist is empty (no ready fd), the current process is suspended until the rdlist non empty process is waked up and returned.
Compared with select & poll, which copies all monitored FDS from the user state space to the kernel state space and scans linearly to find out the ready FDS and then returns them to the user state, epoll [wait] directly returns the ready FDS. Therefore, the I/O performance of epoll will not decline linearly with the increase of monitored FDS like select & poll, which is a very efficient I/O task Part drive technology.
Because I/O multiplexing using epoll requires the user process to be responsible for I/O reading and writing. From the perspective of the user process, the reading and writing process is blocked, so select & poll & epoll is essentially a synchronous I/O model, while asynchronous I/O such as Windows IOCP only needs to put the user space memory buffer when calling WSARecv or WSASend method to read and write data Submitted to the kernel, the kernel is responsible for copying data in user space and kernel space, and will notify the user process after completion. The whole process does not need the user process to participate, so it is a real asynchronous I/O.
extend
In addition, I saw some articles saying that the reason why epoll has high performance is that it uses mmap memory mapping of linux to make the kernel and user process share a piece of physical memory, which is used to store the ready fd list and their data buffer, so user process can read / write data directly from the shared memory after the return of epoll_wait, which makes me confused Because first of all, look at the function declaration of epoll'u wait:
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
The second parameter: ready event list, which needs to allocate memory in user space and then pass it to epoll ﹣ wait. If the kernel will use mmap to set shared memory, just pass a pointer in directly. There is no need to allocate memory in user state at all. This is unnecessary. Secondly, it is extremely dangerous for the kernel and the user process to share memory through mmap. The kernel cannot determine when the shared memory will be recycled. In addition, this will give the user process the permission and access to directly operate the kernel data, which is very easy to cause large system vulnerabilities, so it is rarely done. So I wonder if epoll really uses mmap in the linux kernel. I went to see the source code of the latest version of linux kernel (5.3.9):
/* * Implement the event wait interface for the eventpoll file. It is the kernel * part of the user space epoll_wait(2). */ static int do_epoll_wait(int epfd, struct epoll_event __user *events, int maxevents, int timeout) { // ... /* Time to fish for events ... */ error = ep_poll(ep, events, maxevents, timeout); } // If the timeout == 0 is set when the epoll wait parameter is entered, then directly judge whether there is an event of interest to the user through EP events available. If so, process it through EP send events // If timeout > 0 is set, and no event of user's concern occurs at present, it will sleep and be added to the header of EP - > WQ waiting queue; WQ ﹐ flag ﹐ exclusive flag will be set for waiting event descriptor // After the event wakes up, the EP pol will recheck whether there is a concern event. If the corresponding event has been robbed, the EP pol will continue to sleep and wait static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, int maxevents, long timeout) { // ... send_events: /* * Try to transfer events to user space. In case we get 0 events and * there's still timeout left over, we go trying again in search of * more luck. */ // If everything is normal and an event occurs, start to prepare the data copy to give the user space // If a ready event occurs, EP send events is called to copy the ready event to the user state memory, // Then return to the user state. Otherwise, judge whether the timeout occurs. If there is no timeout, continue to wait for the ready event to occur. If there is a timeout, return to the user state. // As can be seen from the implementation of ep_poll function, if any ready event occurs, the ep_send_events function is called for further processing if (!res && eavail && !(res = ep_send_events(ep, events, maxevents)) && !timed_out) goto fetch_events; // ... } // The EP ﹣ send ﹣ events function is used to copy the ready fd list to the user space. It simply encapsulates the ready fd list memory passed in by the user into the // In the ep_send_events_data structure, then ep_scan_ready_list is invoked to write the events in the ready queue to user space memory. // User processes can access this data for processing static int ep_send_events(struct eventpoll *ep, struct epoll_event __user *events, int maxevents) { struct ep_send_events_data esed; esed.maxevents = maxevents; esed.events = events; // Call the EP scan ready list function to check the rdllist ready list in eventpoll, // And register a callback function EP ﹣ send ﹣ events ﹣ proc. If there is ready fd, it calls EP ﹣ send ﹣ events ﹣ proc for processing ep_scan_ready_list(ep, ep_send_events_proc, &esed, 0, false); return esed.res; } // When EP scan ready list is called, a function pointer to the EP send events proc function is passed as the callback function, // Once ready fd is available, the EP send events proc function is called static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head, void *priv) { // ... /* * If the event mask intersect the caller-requested one, * deliver the event to userspace. Again, ep_scan_ready_list() * is holding ep->mtx, so no operations coming from userspace * can change the item. */ revents = ep_item_poll(epi, &pt, 1); // If the events are 0, it means that there are no ready events. Skip. Otherwise, the ready events will be copied to the user state memory if (!revents) continue; // Copy the current ready events and the data passed in by the user process back to the user space through the "put" user, // That is, the memory of the fd list passed in by the user process at the time of calling epoll · wait if (__put_user(revents, &uevent->events) || __put_user(epi->event.data, &uevent->data)) { list_add(&epi->rdllink, head); ep_pm_stay_awake(epi); if (!esed->res) esed->res = -EFAULT; return 0; } // ... }
Starting from do epoll wait, we can see clearly that the final kernel returns the ready fd list and events to user space through the put user function, which is the standard function used by the kernel to copy data to user space. In addition, I did not find mmap system call logic for memory mapping in the source code of linux kernel and epoll related code, so we can basically conclude that epoll does not use mmap for memory sharing of user space and kernel space in linux kernel, so those articles that epoll uses mmap are misunderstandings.
Non-blocking I/O
What is non blocking I/O? As the name implies, all I/O operations are returned immediately without blocking the current user process. I/O multiplexing usually needs to be used with non blocking I/O, otherwise it may cause unexpected problems. For example, in epoll's ET (edge triggered) mode, if non blocking I/O is not used, there is a great probability that event loop threads will be blocked, thus reducing throughput and even leading to bug s.
Under Linux, we can set the o ﹣ Nonblock flag bit through the fcntl system call to set the socket to non blocking. When reading a non blocking socket, the process is as follows:
When the user process issues the read operation, if the data in the kernel is not ready, it does not block the user process, but immediately returns an EAGAIN error. From the perspective of user process, after it initiates a read operation, it does not need to wait, but gets a result immediately. When the user process judges that the result is an error, it knows that the data is not ready, so it can send the read operation again. Once the data in the kernel is ready and the system call of the user process is received again, it immediately copies the data to the user memory and returns.
Therefore, the feature of non blocking I / O is that the user process needs to constantly ask whether the kernel data is OK.
Go netpoll
A typical Go TCP server:
package main import ( "fmt" "net" ) func main() { listen, err := net.Listen("tcp", ":8888") if err != nil { fmt.Println("listen error: ", err) return } for { conn, err := listen.Accept() if err != nil { fmt.Println("accept error: ", err) break } // start a new goroutine to handle the new connection go HandleConn(conn) } } func HandleConn(conn net.Conn) { defer conn.Close() packet := make([]byte, 1024) for { // If there is no readable data, that is to say, the read buffer is empty, it will block _, _ = conn.Read(packet) // Similarly, if not writable, it will block _, _ = conn.Write(packet) } }
The above is a TCP server written based on the Go native network model (based on netpoll), and the mode is goroutine per connection. In this mode, developers use the synchronous mode to write asynchronous logic, and for developers, whether I/O is blocked or not is imperceptible, that is to say, developers do not need to consider goroutines or even lower thread and progress Scheduling and context switching of programs. The bottom level event driven technology of Go netpoll is definitely based on epoll/kqueue/iocp, which is just to transfer these scheduling and context switching work to the runtime Go scheduler, which is responsible for scheduling goroutines, thus greatly reducing the mental burden of programmers!
Go netpoll core
Go netpoll encapsulates epoll/kqueue/iocp in the bottom layer, so as to achieve the effect of asynchronous execution by using synchronous programming mode. In summary, all network operations are implemented with netFD as the center. netFD is bound to the underlying PollDesc structure. When an EAGAIN error is encountered in reading and writing on a netFD, the current goroutine will be stored in the corresponding PollDesc of the netFD. At the same time, gopark will be called to give the current goroutine to park, and the goroutine will not be activated and re run until another reading and writing event occurs on the netFD. Obviously, the way to inform goroutine of the occurrence of read-write events is the epoll/kqueue/iocp and other event driven mechanisms.
Next, we will analyze the latest Go source code (v1.13.4) to understand the whole operation process of netpoll.
Several data structures and methods related to the source code in the above example code:
// TCPListener is a TCP network listener. Clients should typically // use variables of type Listener instead of assuming TCP. type TCPListener struct { fd *netFD lc ListenConfig } // Accept implements the Accept method in the Listener interface; it // waits for the next call and returns a generic Conn. func (l *TCPListener) Accept() (Conn, error) { if !l.ok() { return nil, syscall.EINVAL } c, err := l.accept() if err != nil { return nil, &OpError{Op: "accept", Net: l.fd.net, Source: nil, Addr: l.fd.laddr, Err: err} } return c, nil } func (ln *TCPListener) accept() (*TCPConn, error) { fd, err := ln.fd.accept() if err != nil { return nil, err } tc := newTCPConn(fd) if ln.lc.KeepAlive >= 0 { setKeepAlive(fd, true) ka := ln.lc.KeepAlive if ln.lc.KeepAlive == 0 { ka = defaultTCPKeepAlive } setKeepAlivePeriod(fd, ka) } return tc, nil } // TCPConn is an implementation of the Conn interface for TCP network // connections. type TCPConn struct { conn } // Conn type conn struct { fd *netFD } type conn struct { fd *netFD } func (c *conn) ok() bool { return c != nil && c.fd != nil } // Implementation of the Conn interface. // Read implements the Conn Read method. func (c *conn) Read(b []byte) (int, error) { if !c.ok() { return 0, syscall.EINVAL } n, err := c.fd.Read(b) if err != nil && err != io.EOF { err = &OpError{Op: "read", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err} } return n, err } // Write implements the Conn Write method. func (c *conn) Write(b []byte) (int, error) { if !c.ok() { return 0, syscall.EINVAL } n, err := c.fd.Write(b) if err != nil { err = &OpError{Op: "write", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err} } return n, err }
netFD
The net.Listen("tcp", ":8888") method returns a TCPListener, which is a struct that implements the net.Listener interface, while the new connection TCP conn received through listen.Accept() is a struct that implements the net.Conn interface, which is embedded with net.Conn structure. Reading the above source code carefully, we can see that whether the Listener's Accept or Conn's Read/Write method is based on the operation of a netFD data structure. netFD is a network descriptor, similar to the concept of a Linux file descriptor. netFD contains a poll.FD data structure, while poll.FD contains two important data structures, Sysfd and pollde SC, the former is the real system file descriptor, the latter is the underlying event driven encapsulation, all read-write timeout and other operations are realized by calling the corresponding methods of the latter.
- When netFD of the server listens, it will create an instance of epoll and add the listenerFD to the event queue of epoll
- netFD adds the returned connFD to epoll's event queue when it accept s
- netFD has syscall.EAGAIN error when reading and writing. Use the waitRead method of pollDesc to hold the current goroutine park until it is ready and return it from the waitRead of pollDesc
// Network file descriptor. type netFD struct { pfd poll.FD // immutable until Close family int sotype int isConnected bool // handshake completed or use of association with peer net string laddr Addr raddr Addr } // FD is a file descriptor. The net and os packages use this type as a // field of a larger type representing a network connection or OS file. type FD struct { // Lock sysfd and serialize access to Read and Write methods. fdmu fdMutex // System file descriptor. Immutable until Close. Sysfd int // I/O poller. pd pollDesc // Writev cache. iovecs *[]syscall.Iovec // Semaphore signaled when file is closed. csema uint32 // Non-zero if this file has been set to blocking mode. isBlocking uint32 // Whether this is a streaming descriptor, as opposed to a // packet-based descriptor like a UDP socket. Immutable. IsStream bool // Whether a zero byte read indicates EOF. This is false for a // message based socket connection. ZeroReadIsEOF bool // Whether this is a file rather than a network socket. isFile bool }
pollDesc
As mentioned earlier, pollDesc is an underlying event driven encapsulation. netFD uses it to complete various I/O related operations. Its definition is as follows:
type pollDesc struct { runtimeCtx uintptr }
Here, struct contains only one pointer. Through the init method of pollDesc, we can find that its specific definition is in runtime.pollDesc:
func (pd *pollDesc) init(fd *FD) error { serverInit.Do(runtime_pollServerInit) ctx, errno := runtime_pollOpen(uintptr(fd.Sysfd)) if errno != 0 { if ctx != 0 { runtime_pollUnblock(ctx) runtime_pollClose(ctx) } return syscall.Errno(errno) } pd.runtimeCtx = ctx return nil } // Network poller descriptor. // // No heap pointers. // //go:notinheap type pollDesc struct { link *pollDesc // in pollcache, protected by pollcache.lock // The lock protects pollOpen, pollSetDeadline, pollUnblock and deadlineimpl operations. // This fully covers seq, rt and wt variables. fd is constant throughout the PollDesc lifetime. // pollReset, pollWait, pollWaitCanceled and runtime·netpollready (IO readiness notification) // proceed w/o taking the lock. So closing, everr, rg, rd, wg and wd are manipulated // in a lock-free way by all operations. // NOTE(dvyukov): the following code uses uintptr to store *g (rg/wg), // that will blow up when GC starts moving objects. lock mutex // protects the following fields fd uintptr closing bool everr bool // marks event scanning error happened user uint32 // user settable cookie rseq uintptr // protects from stale read timers rg uintptr // pdReady, pdWait, G waiting for read or nil rt timer // read deadline timer (set if rt.f != nil) rd int64 // read deadline wseq uintptr // protects from stale write timers wg uintptr // pdReady, pdWait, G waiting for write or nil wt timer // write deadline timer wd int64 // write deadline }
runtime.pollDesc contains a pointer of its own type, which is used to save the address of the next runtime.pollDesc, so as to realize the linked list, which can reduce the size of the data structure. All runtime.polldescs are saved in the runtime.pollCache structure, which is defined as follows:
type pollCache struct { lock mutex first *pollDesc // PollDesc objects must be type-stable, // because we can get ready notification from epoll/kqueue // after the descriptor is closed/reused. // Stale notifications are detected using seq variable, // seq is incremented when deadlines are changed or descriptor is reused. }
net.Listen
After calling net.Listen, the underlying system will call socket method to create an fd assigned to the listener, and initialize the netFD of the listener, then call the listenStream method of netFD to complete the bind & listen operation of socket and the initialization of netFD (mainly the initialization of pollDesc in netFD). The relevant source code is as follows:
// Call linux system call socket to create listener fd and set it to block I/O s, err := socketFunc(family, sotype|syscall.SOCK_NONBLOCK|syscall.SOCK_CLOEXEC, proto) // On Linux the SOCK_NONBLOCK and SOCK_CLOEXEC flags were // introduced in 2.6.27 kernel and on FreeBSD both flags were // introduced in 10 kernel. If we get an EINVAL error on Linux // or EPROTONOSUPPORT error on FreeBSD, fall back to using // socket without them. socketFunc func(int, int, int) (int, error) = syscall.Socket // Initialize the listener netFD with the listener fd created above if fd, err = newFD(s, family, sotype, net); err != nil { poll.CloseFunc(s) return nil, err } // Bind and listen the listener fd, and call init method to complete initialization func (fd *netFD) listenStream(laddr sockaddr, backlog int, ctrlFn func(string, string, syscall.RawConn) error) error { // ... // Complete binding operation if err = syscall.Bind(fd.pfd.Sysfd, lsa); err != nil { return os.NewSyscallError("bind", err) } // Monitor operation completed if err = listenFunc(fd.pfd.Sysfd, backlog); err != nil { return os.NewSyscallError("listen", err) } // Calling init, internally calls poll.FD.Init, and finally calls pollDesc.init. if err = fd.init(); err != nil { return err } lsa, _ = syscall.Getsockname(fd.pfd.Sysfd) fd.setAddr(fd.addrFunc()(lsa), nil) return nil } // Use sync.Once to ensure that a listener holds only one epoll instance var serverInit sync.Once // netFD.init will call poll.FD.Init and finally pollDesc.init, // It creates an epoll instance and adds listener fd to the listening queue func (pd *pollDesc) init(fd *FD) error { // netpollinit is called internally by runtime \ pollserverinit to create epoll instance serverInit.Do(runtime_pollServerInit) // netpollopen is called internally in runtime to register listener fd in the epoll instance, // In addition, it initializes a pollDesc and returns ctx, errno := runtime_pollOpen(uintptr(fd.Sysfd)) if errno != 0 { if ctx != 0 { runtime_pollUnblock(ctx) runtime_pollClose(ctx) } return syscall.Errno(errno) } // Assign the real initialized pollDesc instance to the current pollDesc's own pointer, which will be used directly in subsequent operations pd.runtimeCtx = ctx return nil }
We mentioned three basic calls of epoll. Go implements encapsulation of those three calls in the source code:
#include <sys/epoll.h> int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); // Go encapsulation of the above three calls func netpollinit() func netpollopen(fd uintptr, pd *pollDesc) int32 func netpoll(block bool) gList
netFD uses these three encapsulation to create instance, register fd and wait for event operation for epoll.
Listener.Accept()
Listener.Accept() receives a new connection from the client. Specifically, call netFD.accept to complete this function:
// Accept implements the Accept method in the Listener interface; it // waits for the next call and returns a generic Conn. func (l *TCPListener) Accept() (Conn, error) { if !l.ok() { return nil, syscall.EINVAL } c, err := l.accept() if err != nil { return nil, &OpError{Op: "accept", Net: l.fd.net, Source: nil, Addr: l.fd.laddr, Err: err} } return c, nil } func (ln *TCPListener) accept() (*TCPConn, error) { fd, err := ln.fd.accept() if err != nil { return nil, err } tc := newTCPConn(fd) if ln.lc.KeepAlive >= 0 { setKeepAlive(fd, true) ka := ln.lc.KeepAlive if ln.lc.KeepAlive == 0 { ka = defaultTCPKeepAlive } setKeepAlivePeriod(fd, ka) } return tc, nil }
In the netFD.accept method, call poll.FD.Accept, and finally use the linux system call accept to receive the new connection, and set the socket of accept to the non blocking I/O mode:
// Accept wraps the accept network call. func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) { if err := fd.readLock(); err != nil { return -1, nil, "", err } defer fd.readUnlock() if err := fd.pd.prepareRead(fd.isFile); err != nil { return -1, nil, "", err } for { // Use the linux system call accept to receive the new connection and create the corresponding socket s, rsa, errcall, err := accept(fd.Sysfd) // Because listener fd is set to be non blocking when it is created, // So the accept method will return directly, no matter whether there is a new connection coming or not. If err == nil, it means that a new connection is established normally, and it will return directly if err == nil { return s, rsa, "", err } // If err! = nil, determine err == syscall.EAGAIN, and enter pollDesc.waitRead method if it meets the conditions switch err { case syscall.EAGAIN: if fd.pd.pollable() { // If the expected I/O event does not occur at present, waitRead will make the logical block here through park goroutine if err = fd.pd.waitRead(fd.isFile); err == nil { continue } } case syscall.ECONNABORTED: // This means that a socket on the listen // queue was closed before we Accept()ed it; // it's a silly error, so try again. continue } return -1, nil, errcall, err } } // Use the accept system call of linux to receive the new connection and set the socket fd to non blocking I/O ns, sa, err := Accept4Func(s, syscall.SOCK_NONBLOCK|syscall.SOCK_CLOEXEC) // On Linux the accept4 system call was introduced in 2.6.28 // kernel and on FreeBSD it was introduced in 10 kernel. If we // get an ENOSYS error on both Linux and FreeBSD, or EINVAL // error on Linux, fall back to using accept. // Accept4Func is used to hook the accept4 call. var Accept4Func func(int, int) (int, syscall.Sockaddr, error) = syscall.Accept4
The pollDesc.waitRead method is mainly responsible for detecting whether there is an "expected" I/O event in the fd corresponding to the upper level netFD of the current pollDesc. If there is one, it will return directly. Otherwise, it will park the current goroutine and wait until the corresponding fd has a read / write or other "expected" I/O event, and then it will return to the outer for loop, Let goroutine continue with the logic.
Conn.Read/Conn.Write
First, let's see how the Conn.Read method is implemented. In fact, the principle is the same as that of Listener.Accept. For the specific call chain, first call the netFD.Read of Conn, then call poll.FD.Read internally, and finally use the linux system call read: syscall.Read to complete data reading,
// Implementation of the Conn interface. // Read implements the Conn Read method. func (c *conn) Read(b []byte) (int, error) { if !c.ok() { return 0, syscall.EINVAL } n, err := c.fd.Read(b) if err != nil && err != io.EOF { err = &OpError{Op: "read", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err} } return n, err } func (fd *netFD) Read(p []byte) (n int, err error) { n, err = fd.pfd.Read(p) runtime.KeepAlive(fd) return n, wrapSyscallError("read", err) } // Read implements io.Reader. func (fd *FD) Read(p []byte) (int, error) { if err := fd.readLock(); err != nil { return 0, err } defer fd.readUnlock() if len(p) == 0 { // If the caller wanted a zero byte read, return immediately // without trying (but after acquiring the readLock). // Otherwise syscall.Read returns 0, nil which looks like // io.EOF. // TODO(bradfitz): make it wait for readability? (Issue 15735) return 0, nil } if err := fd.pd.prepareRead(fd.isFile); err != nil { return 0, err } if fd.IsStream && len(p) > maxRW { p = p[:maxRW] } for { // Try to read data from the socket because the socket is set to non blocking I/O when it is accepted by the listener, // So it's also a direct return here, whether there's readable data or not n, err := syscall.Read(fd.Sysfd, p) if err != nil { n = 0 // err == syscall.EAGAIN indicates that there is no expected I/O event, that is, socket is not readable if err == syscall.EAGAIN && fd.pd.pollable() { // If the expected I/O event does not occur at present, waitRead will make the logical block here through park goroutine if err = fd.pd.waitRead(fd.isFile); err == nil { continue } } // On MacOS we can see EINTR here if the user // pressed ^Z. See issue #22838. if runtime.GOOS == "darwin" && err == syscall.EINTR { continue } } err = fd.eofError(n, err) return n, err } }
The principle of conn.Write and conn.Read is the same. It also uses pollDesc.waitWrite similar to pollDesc.waitRead to park goroutine until the expected I/O event occurs. The internal implementation principle of pollDesc.waitWrite is the same as that of pollDesc.waitRead, which is based on runtime﹐ pollwait, so it will not be repeated here.
pollDesc.waitRead
pollDesc.waitRead internally calls runtime "pollwait" to realize the purpose of park staying in goroutine when there is no I/O event,
//go:linkname poll_runtime_pollWait internal/poll.runtime_pollWait func poll_runtime_pollWait(pd *pollDesc, mode int) int { err := netpollcheckerr(pd, int32(mode)) if err != 0 { return err } // As for now only Solaris, illumos, and AIX use level-triggered IO. if GOOS == "solaris" || GOOS == "illumos" || GOOS == "aix" { netpollarm(pd, mode) } // Enter netpollblock and judge whether there are expected I/O events. The for loop here is to wait until io ready for !netpollblock(pd, int32(mode), false) { err = netpollcheckerr(pd, int32(mode)) if err != 0 { return err } // Can happen if timeout has fired and unblocked us, // but before we had a chance to run, timeout has been reset. // Pretend it has not happened and retry. } return 0 } // returns true if IO is ready, or false if timedout or closed // waitio - wait only for completed IO, ignore errors func netpollblock(pd *pollDesc, mode int32, waitio bool) bool { // gpp represents the io ready event, which is assigned to read wait or write wait event according to the value of mode gpp := &pd.rg if mode == 'w' { gpp = &pd.wg } // set the gpp semaphore to WAIT // This for loop is to wait for io ready or io wait for { old := *gpp // gpp == pdReady indicates that the expected I/O event has occurred, // It can directly return to unblock current goroutine and perform I/O operations in response if old == pdReady { *gpp = 0 return true } if old != 0 { throw("runtime: double wait") } // If no expected I/O event occurs, set the gpp value to pdWait and exit the for loop by atomic operation if atomic.Casuintptr(gpp, 0, pdWait) { break } } // need to recheck error states after setting gpp to WAIT // this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl // do the opposite: store to closing/rd/wd, membarrier, load of rg/wg // waitio is false at this time. Is the fd corresponding to pollDesc normal for netpollcheckerr method, //Generally speaking, netpollcheckerr(pd, mode) == 0 is established, so gopark will be executed here to give the current goroutine to park until read / write or other "expected" I/O events occur on the corresponding fd, and then unpark will return if waitio || netpollcheckerr(pd, mode) == 0 { gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5) } // be careful to not lose concurrent READY notification old := atomic.Xchguintptr(gpp, 0) if old > pdWait { throw("runtime: corrupted polldesc") } return old == pdReady }
netpoll
We have analyzed how netpoll blocks Accept/Read/Write through park goroutine from the source point of view. By calling gopark, goroutine will be placed in a waiting queue (such as channel waitq, where G's status is changed from "gurunning" to "gwaiting"), so g must be waked up manually (through goready), otherwise, tasks will be lost, This is usually used for application layer blocking.
So, finally, there is a very important question: when I/O events occur, how does netpoll wake up those goroutines in I/O wait? The answer is that there is a func netpoll(block bool) gList method in the Src / Runtime / netpoll. Go file of go source code through epoll · wait. It will internally call epoll · wait to get the ready fd list, and add goroutine corresponding to each fd to the list to return.
// polls for ready network connections // returns list of goroutines that become runnable func netpoll(block bool) gList { if epfd == -1 { return gList{} } waitms := int32(-1) // Whether to call epoll? Wait in blocking mode if !block { waitms = 0 } var events [128]epollevent retry: // Get ready fd list n := epollwait(epfd, &events[0], int32(len(events)), waitms) if n < 0 { if n != -_EINTR { println("runtime: epollwait on fd", epfd, "failed with", -n) throw("runtime: netpoll failed") } goto retry } var toRun gList for i := int32(0); i < n; i++ { ev := &events[i] if ev.events == 0 { continue } var mode int32 if ev.events&(_EPOLLIN|_EPOLLRDHUP|_EPOLLHUP|_EPOLLERR) != 0 { mode += 'r' } if ev.events&(_EPOLLOUT|_EPOLLHUP|_EPOLLERR) != 0 { mode += 'w' } if mode != 0 { pd := *(**pollDesc)(unsafe.Pointer(&ev.data)) pd.everr = false if ev.events == _EPOLLERR { pd.everr = true } netpollready(&toRun, pd, mode) } } if block && toRun.empty() { goto retry } return toRun }
In many scenarios, Go may call netpoll to check the status of file descriptors. Find the I/O ready socket fd, and find the information attached to the poller corresponding to the socket fd. According to the information, change the goroutine state waiting for the ready socket fd to "Grunnable". After executing netpoll, a ready goroutine list will be found. Next, the ready goroutine will be added to the scheduling queue and wait for the scheduling to run.
First of all, when the Go runtime scheduler normally schedules the goroutine, it is possible to call netpoll to obtain the goroutine corresponding to the ready fd to schedule the execution:
// One round of scheduler: find a runnable goroutine and execute it. // Never returns. func schedule() { // ... if gp == nil { gp, inheritTime = findrunnable() // blocks until work is available } // ... } // Finds a runnable goroutine to execute. // Tries to steal from other P's, get g from global queue, poll network. func findrunnable() (gp *g, inheritTime bool) { // ... // Poll network. // This netpoll is only an optimization before we resort to stealing. // We can safely skip it if there are no waiters or a thread is blocked // in netpoll already. If there is any kind of logical race with that // blocked thread (e.g. it has already returned from netpoll, but does // not set lastpoll yet), this thread will do blocking netpoll below // anyway. if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { if list := netpoll(false); !list.empty() { // non-blocking gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false } } // ... }
In the core method schedule of Go scheduler, a method called findrun() will be called to get the running goroutine for execution. In the findrun() method, netpoll will be called to get the goroutine corresponding to the ready fd.
In addition, the sysmon monitoring thread may also call netpoll:
// Always runs without a P, so write barriers are not allowed. // //go:nowritebarrierrec func sysmon() { // ... now := nanotime() if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now { atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now)) // Call netpoll in a non blocking way to get the ready fd list list := netpoll(false) // non-blocking - returns list of goroutines if !list.empty() { // Need to decrement number of idle locked M's // (pretending that one more is running) before injectglist. // Otherwise it can lead to the following situation: // injectglist grabs all P's but before it starts M's to run the P's, // another M returns from syscall, finishes running its G, // observes that there is no work to do and no other running M's // and reports deadlock. incidlelocked(-1) // Insert it into the scheduler's runnable list (global) and wait for it to be scheduled for execution injectglist(&list) incidlelocked(1) } } // retake P's blocked in syscalls // and preempt long running G's if retake(now) != 0 { idle = 0 } else { idle++ } // check if we need to force a GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 { lock(&forcegc.lock) forcegc.idle = 0 var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now { lasttrace = now schedtrace(debug.scheddetail > 0) } } }
Go runtime will create an independent M as the monitoring thread when the program starts, which is called sysmon. This thread is a system level daemon thread, which can run without P. sysmon runs every 20us~10ms. In sysmon, do the following in polling mode (as shown in the above code):
- Call runtime.netpoll in a non blocking way to find out g that can wake up from network I/O, and call injectglist to insert it into the runnable list (global) of the scheduler. When scheduling is triggered, it is possible to get G from the global runnable list. Then recycle calls startm until all P's are not in the "pig" state.
- Call retake to preempt P that has been in "Psyscall" state for a long time.
To sum up, Go, with the help of epoll/kqueue/iocp and runtime scheduler, designed its own I/O multiplexing netpoll, and successfully made the Listener.Accept/conn.Read/conn.Write and other methods look like synchronization mode from the perspective of developers.
The problem of Go netpoll
The design of Go netpoll is not exquisite, nor is its performance inefficient. It's really cool to write network programs with goroutine: simple and efficient. However, there is no perfect design and architecture. Although goroutine per connection is simple and efficient, it will also expose problems in some extreme scenarios: goroutine is very light, its initial memory value of custom stack is only 2KB, and then it will be expanded on demand; in the business scenario of massive connections, goroutine per connection, at this time, goroutine number The amount and consumed resources will increase in a linear trend. First, it will cause great pressure on the Go runtime scheduler and occupy system resources. Then, the misappropriation of resources will affect the scheduling of the runtime in turn, resulting in a significant decline in performance.
Reactor mode
At present, most of the high-performance network programs built on the Linux platform use the Reactor mode, such as netty, libevent, libev, ACE, POE(Perl), Twisted(Python), etc.
The Reactor mode essentially refers to the mode using I/O multiplexing + non blocking I/O.
Usually, a main thread is set to do event loop and I/O reading and writing. It listens for I/O events through system calls such as select/poll/epoll_wait, and the business logic is submitted to other working threads. The so-called "non blocking I/O" core idea is to avoid blocking on read() or write() or other I/O system calls, so as to maximize the reuse of event loop threads, so that one thread can serve multiple sockets. In Reactor mode, I/O threads can only block on the I/O multiplexing function (select / poll / epoll · wait).
The workflow of Reactor mode is generally as follows:
- After bind & listen, the Server registers the listenfd into epolfd, and finally enters the event loop. Select / poll / epoll [wait] will be called during the loop to wait for blocking. If there is a new connection event on listenfd, it will be unblocked and returned. socket.accept will be called to receive the new connection connfd, and connfd will be added to epollfd's I/O multiplexing (listening) queue.
- When a read / write event occurs on the connfd, the blocking wait of select/poll/epoll_wait will also be released, and then I/O read and write operations will be performed. Here, read and write I/O are non blocking I/O, so that the next cycle of event loop will not be blocked. However, it is easy to split the business logic and not easy to understand and maintain.
- Call read to read the data, decode it and put it into the queue, waiting for the worker thread to process.
- After the worker thread finishes processing the data, it returns to the event loop thread, which is responsible for calling write to write the data back to the client.
If the read and write operations on the accept connection and conn are completed in the main thread, it requires non blocking I/O, because one of the most important principles of the Reactor mode is that the I/O operation cannot block the event loop event loop. In fact, event loop may also be multi-threaded, but there is only one select / poll / epoll [wait] in a thread.
As mentioned above, in some scenarios, Go netpoll may consume system resources too much because of creating too many goroutine s. In real world network business, only a few of the massive connections held by servers are active in a very short time window, while most are idle, just like this (non real data, just for metaphor):

So it's too luxurious to assign a goroutine to each connection, and the Reactor mode, which uses I/O multiplexing and only needs a few threads to manage massive connections, can play an important role in such network business:

In most application scenarios, I recommend that you follow Go's best practices to build your own network applications in this netpoll mode. However, in some business scenarios where performance is extremely pursued, system resources are squeezed, and technology stack must be native Go (regardless of C/C + + writing the middle layer and Go writing the business layer), we can consider building our own Reactor network model.
gnet
gnet It is an event driven high-performance and lightweight network framework, supporting multiple protocols: TCP / UDP / Unix socket. It is used directly epoll and kqueue System call instead of standard Golang network package: net To build a network application, it works like two open-source Network Libraries: netty and libuv.
gnet The highlight is that it is a high-performance, lightweight, non blocking pure Go implementation of the transport layer (TCP / UDP / Unix socket) network framework, which developers can use gnet To implement their own application layer network protocol, so as to build their own application layer network applications: for example, in gnet The implementation of HTTP protocol on can create an HTTP server or Web development framework, and the implementation of Redis protocol can create its own Redis server and so on.
gnet In some extreme network business scenarios, such as massive connection, high-frequency creation and destruction of connection, etc, gnet Far superior to Go native in performance and resource utilization net Package (based on netpoll).
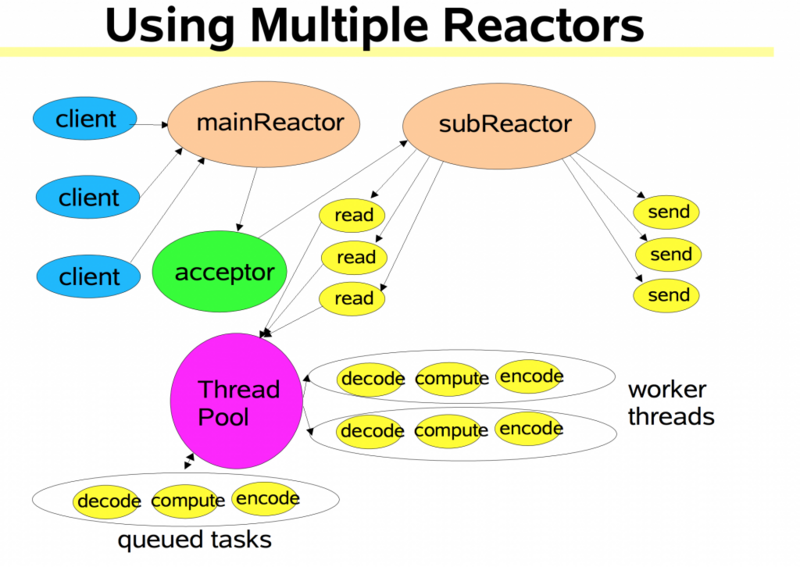
gnet has implemented two kinds of network models: multi reactors and multi reactors + goroutine pool. Thanks to these network models, gnet has become a high-performance and low loss Go network framework

Function
- [x] High performance Event loop event driven based on Multithreading / Go process model
- [x] built in round robin polling load balancing algorithm
- [x] built in goroutine pool, open source library ants Provide support
- [x] built in bytes memory pool, open source library pool Provide support
- [x] concise APIs
- [x] efficient memory utilization based on ring buffer
- [x] supports a variety of network protocols: TCP, UDP, Unix Sockets
- [x] supports two event driven mechanisms: epoll in Linux and kqueue in FreeBSD
- [x] supports asynchronous write operations
- [x] flexible event timer
- [x] so? Reuseport port reuse
- [x] built in a variety of codecs, supporting TCP data stream subcontracting: LineBasedFrameCodec, DelimiterBasedFrameCodec, FixedLengthFrameCodec and LengthFieldBasedFrameCodec, refer to netty codec , and support custom codec
- [] add more load balancing algorithms: random, least connection, consistent hash, etc
- [] supports the IOCP event driven mechanism of Windows platform
- [] TLS support
- [] implementation of gnet client
Reference resources
- Linux I/O mode and details of select, poll and epoll
- IO multiplexing and the realization of Go Network Library
- Talk about Linux IO
- Go scheduling model
- linux user space and kernel space
- Deep analysis of Goroutine concurrent scheduling model
- Go language implementation (2): scheduling%EF%BC%9A%E8%B0%83%E5%BA%A6/)
- On the reset of timeval and FD set in select function