Words written in the front
When it comes to the automatic generation scheme of distributed ID, you are sure to be very familiar with it, and you can immediately tell several schemes that you are good at. Indeed, as an important identification of system data, ID is of great importance, and various schemes have been optimized for many generations. Please allow me to use this perspective to classify the automatic generation schemes of distributed ID:
Realization way
- Completely dependent on data source mode
The generation rule and read control of ID are completely controlled by the data source, such as the self-growing ID and serial number of database, or the sequence number generated by the INCR/INCRBY atomic operation of Redis.
- Semi dependent data source mode
Some of the generation factors of ID need to be controlled by data source (or configuration information), such as snowflake algorithm.
- Independent of data source mode
The generation rules of ID are completely calculated by machine information independently, and do not depend on any configuration information and data records, such as common UUID, GUID, etc.
Practice plan
The practical scheme is applicable to the three implementation methods mentioned above, and can be used as a supplement to the three implementation methods, aiming to improve the system throughput, but the limitations of the original implementation method still exist.
- Real time acquisition scheme
As the name implies, each time you want to get an ID, it is generated in real time. Simple and fast, ID S are continuous, but throughput may not be the highest.
- Pre generation scheme
A batch of ID s generated in advance can be placed in the data pool, which can be generated simply by self growth or by setting the step size and batch generation. These data generated in advance need to be placed in the storage container (JVM memory, Redis, database table). The throughput can be greatly improved, but temporary storage space needs to be opened. After power failure, existing IDs may be lost, and IDs may be interrupted.
Brief introduction of the plan
The following is a brief introduction to the current popular distributed ID scheme
- Database self growth ID
All IDs are stored in the database, which is the most commonly used method to generate IDs. They are widely used in the monomer application period. When establishing data tables, the database's self-contained auto increment is used as the primary key, or the sequence is used to complete some self-growing IDS in other scenarios.
- Advantages: very simple, orderly increase, convenient paging and sorting.
- Disadvantages: after database and table splitting, the self increasing ID of the same data table is easy to be repeated and cannot be used directly (step size can be set, but the limitation is obvious); the performance throughput is low. If a separate database is designed to realize the data uniqueness of distributed applications, even if the pre generation scheme is used, there will be a single point bottle in the high concurrency scenario due to the problem of transaction lock. Neck.
- Applicable scenario: table ID (including master-slave synchronization scenario) of a single database instance, part of the serial number counted by day, etc.; sub database sub table scenario and system wide uniqueness ID scenario are not applicable.
- Redis generation ID
It is also a completely data source dependent mode. Through the INCR/INCRBY auto increment atomic operation command of Redis, it can ensure that the generated ID is definitely unique and orderly, and essentially the implementation mode is consistent with the database.
- Advantage: the overall throughput is higher than the database.
- Disadvantages: it is a little difficult to retrieve the latest ID value after the Redis instance or cluster goes down.
- Applicable scenario: it is more suitable for counting scenarios, such as user visits, order serial number (date + serial number), etc.
- UUID, GUID generation ID
UUID: according to OSF standard calculation, Ethernet card address, nanosecond time, chip ID code and many possible numbers are used. It is a combination of the following parts: current date and time (the first part of UUID is related to time, if you generate a UUID after a few seconds, the first part is different, the rest are the same), clock sequence, globally unique IEEE machine identification number (if there is a network card, it is obtained from the network card, and no network card is obtained in other ways)
GUID: Microsoft's implementation of UUID. There are various other implementations of UUID, not only guids, but also lists them one by one.
These two methods are independent of data sources and truly globally unique ID s.
- Advantages: independent of any data source, self computing, no network ID, super fast, and unique in the world.
- Disadvantages: there is no order, and it is relatively long (128bit). As a database primary key and index, the index efficiency will be reduced and the space will be occupied more.
- Applicable scenario: it can be applied as long as there is no strict requirement for storage space, such as various link tracking, log storage, etc.
4. snowflake algorithm generates ID
It belongs to the semi dependent data source mode. The principle is to use the Long type (64 bits) and fill it according to certain rules: time (MS level) + cluster ID + machine ID + serial number. The number of bits occupied by each part can be allocated according to the actual needs, and the two parts, cluster ID and machine ID, need to rely on external parameter configuration or database records in the actual application scenarios.
- Advantages: high performance, low delay, decentralization, orderly by time
- Disadvantages: the clock of the machine is required to be synchronized (to the second level)
- Applicable scenario: Data primary key of distributed application environment
Does snow ID algorithm sound particularly suitable for distributed architecture scenarios? For now, yes, let's focus on its principles and best practices.
Implementation principle of snowflake algorithm
snowflake algorithm comes from Twitter, which is implemented in scala language, and RPC interface call is implemented by Thrift framework. The original project is the database migration from mysql to Cassandra. Cassandra has no ready-made ID generation mechanism, which has spawned this project. The existing github source code is interesting to see.
The characteristics of snowflake algorithm are orderly, unique, high performance, low latency (each machine generates at least 10k pieces of data per second, and the response time is within 2ms). It should be used in a distributed environment (multi cluster, cross machine room). Therefore, the ID obtained by snowflake algorithm is composed of segments:
- Time difference with specified date (MS level), 41 bits, enough for 69 years
- Cluster ID + machine ID, 10 bits, up to 1024 machines
- Sequence, 12 bits, each machine can generate up to 4096 serial numbers per millisecond
As shown in the figure:

- 1bit: sign bit, fixed to 0, indicating that all ID s are positive integers
- 41bit: millisecond time difference. It can last for 69 years from the specified date. We know that the time stamp represented by Long type starts from 1970-01-01 00:00:00. We can specify the date here, such as 2019-10-23 00:00:00
- 10bit: machine ID, which can be deployed in different places and can be configured in multiple clusters. It is necessary to plan the number of machine rooms, clusters and instance IDS offline.
- 12bit: sequence ID. if the front is the same, it can support up to 4096
The above bit allocation is only officially recommended. We can allocate it according to the actual needs. For example, the maximum number of our application machines is dozens, but the number of concurrent machines is large. We can reduce 10bit to 8bit, and increase the sequence part from 12bit to 14bit, etc.
Of course, the meaning of each part can also be freely replaced, such as the machine ID in the middle part. If it is a cloud computing and containerized deployment environment, you can expand the capacity at any time and reduce the operation of the machine. It is not realistic to configure the instance ID through offline planning, so you can replace it with the instance ID every time you restart. Take the self growing ID as the content of this part, which will be explained below.
There is also a God on github who has made the most basic implementation of snowflake in Java. Here you can directly view the source code: snowflake java source code
/** * twitter Snooflake algorithm based on java * * @author beyond * @date 2016/11/26 */ public class SnowFlake { /** * Start timestamp */ private final static long START_STMP = 1480166465631L; /** * Number of bits occupied by each part */ private final static long SEQUENCE_BIT = 12; //Number of digits occupied by serial number private final static long MACHINE_BIT = 5; //Number of digits occupied by machine identification private final static long DATACENTER_BIT = 5;//Number of bits occupied by data center /** * Maximum value of each part */ private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT); private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT); private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT); /** * Displacement of each part to the left */ private final static long MACHINE_LEFT = SEQUENCE_BIT; private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT; private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT; private long datacenterId; //Data center private long machineId; //Machine identification private long sequence = 0L; //serial number private long lastStmp = -1L;//Last timestamp public SnowFlake(long datacenterId, long machineId) { if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) { throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0"); } if (machineId > MAX_MACHINE_NUM || machineId < 0) { throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0"); } this.datacenterId = datacenterId; this.machineId = machineId; } /** * Generate next ID * * @return */ public synchronized long nextId() { long currStmp = getNewstmp(); if (currStmp < lastStmp) { throw new RuntimeException("Clock moved backwards. Refusing to generate id"); } if (currStmp == lastStmp) { //In the same millisecond, the serial number increases automatically sequence = (sequence + 1) & MAX_SEQUENCE; //The number of sequences in the same millisecond has reached the maximum if (sequence == 0L) { currStmp = getNextMill(); } } else { //Serial number is set to 0 in different milliseconds sequence = 0L; } lastStmp = currStmp; return (currStmp - START_STMP) << TIMESTMP_LEFT //Time stamp section | datacenterId << DATACENTER_LEFT //Data center part | machineId << MACHINE_LEFT //Machine identification part | sequence; //Serial number section } private long getNextMill() { long mill = getNewstmp(); while (mill <= lastStmp) { mill = getNewstmp(); } return mill; } private long getNewstmp() { return System.currentTimeMillis(); } public static void main(String[] args) { SnowFlake snowFlake = new SnowFlake(2, 3); for (int i = 0; i < (1 << 12); i++) { System.out.println(snowFlake.nextId()); } } }
Basically, through displacement operation, move the value of each meaning segment to the corresponding position. For example, the machine ID here consists of data center + machine ID. therefore, the machine ID moves 12 bits to the left, which is its position. The number of data center moves 17 bits to the left, and the value of time stamp moves 22 bits to the left. Each part occupies its own position without interference, thus forming a complete ID value.
This is the most basic implementation principle of snowflake. If you don't remember some basic java knowledge, you should check the data. For example, binary-1 represents 0xFFFF (all of which are 1), < represents left shift operation, - 1 < < 5 equals - 32, xor-1 ^ (- 1 < < 5) is 31, and so on.
Understanding the basic implementation principle of snowflake can be achieved by planning the machine identification in advance. However, in the current distributed production environment, a variety of cloud computing and containerization technologies are used. The number of instances changes at any time, and the problem of server instance clock call back needs to be addressed. It is not feasible to fix the planning ID and then use snowflake through configuration, which is generally self-contained. Start stop, increase or decrease the machine, so we need to make some changes to the snowflake to better apply to the production environment.
Baidu uid generator project
The UidGenerator project is implemented based on the snowflake principle. It only modifies the definition of the machine ID part (the number of instance restarts), and 64 bit allocation supports configuration. The official default allocation method is as follows:

Snowflake algorithm description: the specified machine & the same time & a certain concurrent sequence is unique. Based on this, a unique ID (long) of 64 bits can be generated.
- sign(1bit) fixed 1bit symbol ID, that is, the generated UID is a positive number.
- delta seconds (28 bits) Current time, relative to the incremental value of time base point "2016-05-20", unit: second, can support up to 8.7 years
- worker id (22 bits) machine id, which can support up to 420w machine starts. The built-in implementation is allocated by the database at startup. The default allocation policy is to discard after use, and reuse policy can be provided later.
- sequence (13 bits) is a concurrent sequence per second. 13 bits can support 8192 concurrent sequences per second.
There are two specific implementations, one is to generate ID in real time, the other is to generate ID in advance
- DefaultUidGenerator
- At startup, insert the IP, Port and other information of the current instance into the server node table of the database, and then obtain the self growth ID of the data as the machine ID part. The simple flow chart is as follows:
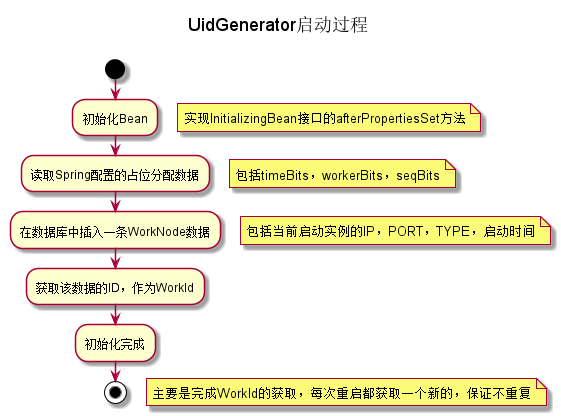
- It provides a method to obtain ID, and detects whether clock calls back sometimes. If there is a call back phenomenon, an exception is thrown directly. Current version does not support clock forward drift operation. The simple flow chart is as follows:
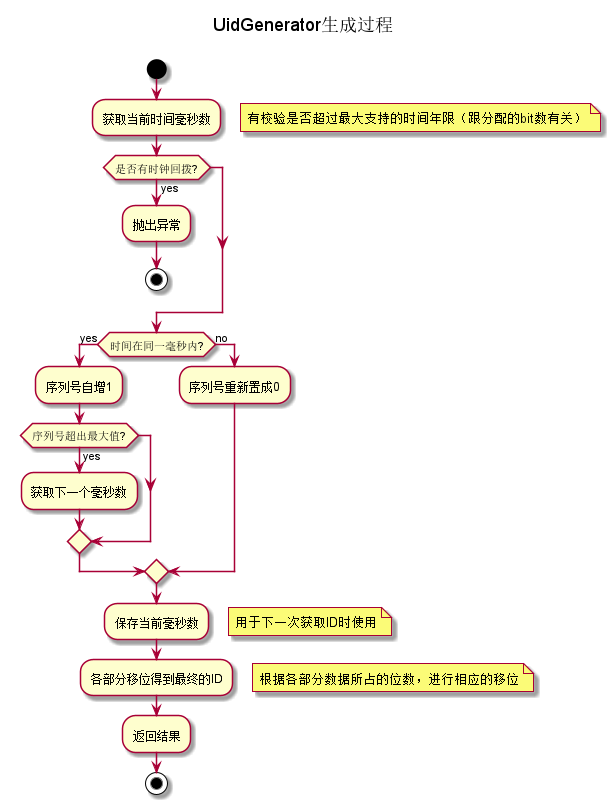
The core code is as follows:
/** * Get UID * * @return UID * @throws UidGenerateException in the case: Clock moved backwards; Exceeds the max timestamp */ protected synchronized long nextId() { long currentSecond = getCurrentSecond(); // Clock moved backwards, refuse to generate uid if (currentSecond < lastSecond) { long refusedSeconds = lastSecond - currentSecond; throw new UidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds); } // At the same second, increase sequence if (currentSecond == lastSecond) { sequence = (sequence + 1) & bitsAllocator.getMaxSequence(); // Exceed the max sequence, we wait the next second to generate uid if (sequence == 0) { currentSecond = getNextSecond(lastSecond); } // At the different second, sequence restart from zero } else { sequence = 0L; } lastSecond = currentSecond; // Allocate bits for UID return bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence); }
- CachedUidGenerator
The machine ID acquisition method is the same as the previous one. This is to generate a batch of IDS in advance and put them in a RingBuffer ring array for the use of the client. When the available data is lower than the threshold value, the batch generation method is called again, which belongs to the method of exchanging space for time, and can improve the throughput of the whole ID.
- Compared with DefaultUidGenerator, there is more logic to fill RingBuffer ring array during initialization. The simple flowchart is as follows:
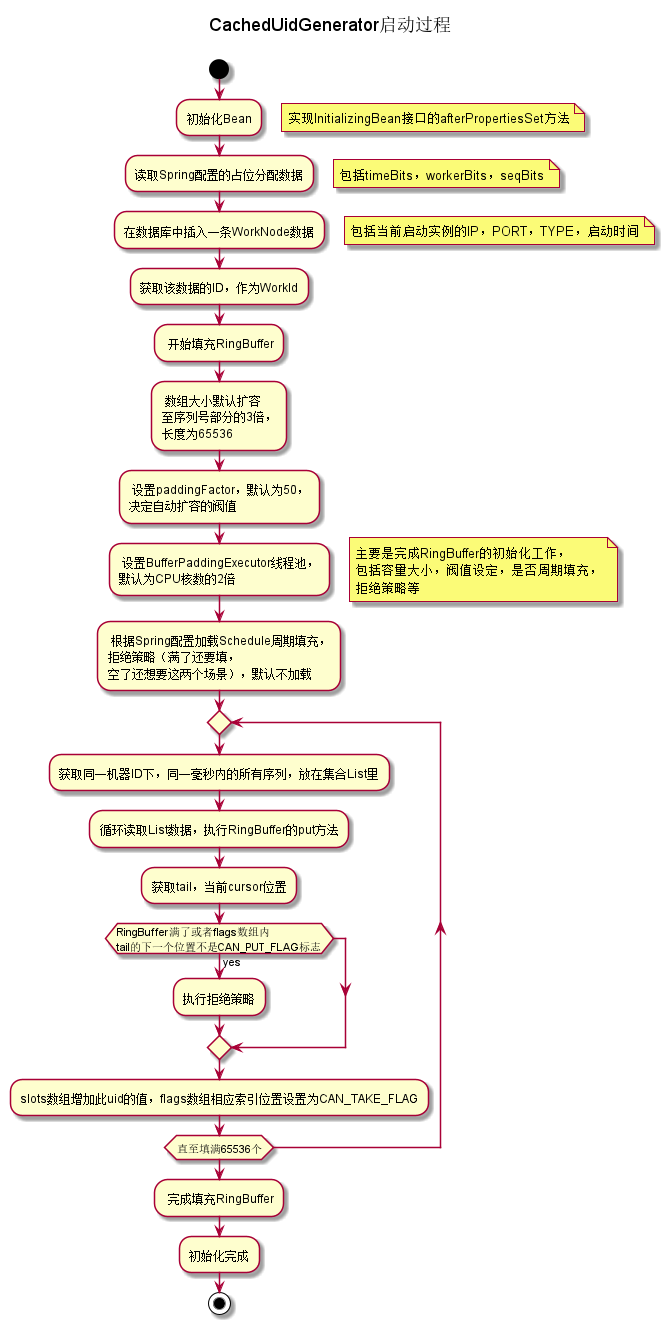
Core code:
/** * Initialize RingBuffer & RingBufferPaddingExecutor */ private void initRingBuffer() { // initialize RingBuffer int bufferSize = ((int) bitsAllocator.getMaxSequence() + 1) << boostPower; this.ringBuffer = new RingBuffer(bufferSize, paddingFactor); LOGGER.info("Initialized ring buffer size:{}, paddingFactor:{}", bufferSize, paddingFactor); // initialize RingBufferPaddingExecutor boolean usingSchedule = (scheduleInterval != null); this.bufferPaddingExecutor = new BufferPaddingExecutor(ringBuffer, this::nextIdsForOneSecond, usingSchedule); if (usingSchedule) { bufferPaddingExecutor.setScheduleInterval(scheduleInterval); } LOGGER.info("Initialized BufferPaddingExecutor. Using schdule:{}, interval:{}", usingSchedule, scheduleInterval); // set rejected put/take handle policy this.ringBuffer.setBufferPaddingExecutor(bufferPaddingExecutor); if (rejectedPutBufferHandler != null) { this.ringBuffer.setRejectedPutHandler(rejectedPutBufferHandler); } if (rejectedTakeBufferHandler != null) { this.ringBuffer.setRejectedTakeHandler(rejectedTakeBufferHandler); } // fill in all slots of the RingBuffer bufferPaddingExecutor.paddingBuffer(); // start buffer padding threads bufferPaddingExecutor.start(); }
public synchronized boolean put(long uid) { long currentTail = tail.get(); long currentCursor = cursor.get(); // tail catches the cursor, means that you can't put any cause of RingBuffer is full long distance = currentTail - (currentCursor == START_POINT ? 0 : currentCursor); if (distance == bufferSize - 1) { rejectedPutHandler.rejectPutBuffer(this, uid); return false; } // 1. pre-check whether the flag is CAN_PUT_FLAG int nextTailIndex = calSlotIndex(currentTail + 1); if (flags[nextTailIndex].get() != CAN_PUT_FLAG) { rejectedPutHandler.rejectPutBuffer(this, uid); return false; } // 2. put UID in the next slot // 3. update next slot' flag to CAN_TAKE_FLAG // 4. publish tail with sequence increase by one slots[nextTailIndex] = uid; flags[nextTailIndex].set(CAN_TAKE_FLAG); tail.incrementAndGet(); // The atomicity of operations above, guarantees by 'synchronized'. In another word, // the take operation can't consume the UID we just put, until the tail is published(tail.incrementAndGet()) return true; }
- The ID acquisition logic. Because there is a buffered array of RingBuffer, the ID can be obtained directly from RingBuffer. At the same time, when RingBuffer self verification triggers to generate again in batches can be obtained. The obvious difference between the ID value obtained here and DefaultUidGenerator is that the ID obtained by DefaultUidGenerator, the timestamp part is the current time, and the cache uidgenerator is the filling part. The time stamp of time is not the time to get the time, but it doesn't matter much. It's not repeated. It's the same. The simple flow chart is as follows:
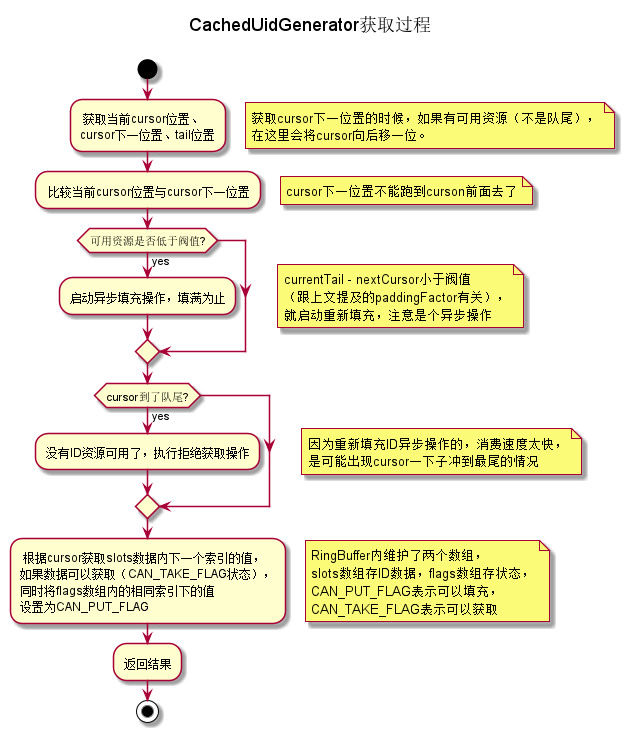
Core code:
public long take() { // spin get next available cursor long currentCursor = cursor.get(); long nextCursor = cursor.updateAndGet(old -> old == tail.get() ? old : old + 1); // check for safety consideration, it never occurs Assert.isTrue(nextCursor >= currentCursor, "Curosr can't move back"); // trigger padding in an async-mode if reach the threshold long currentTail = tail.get(); if (currentTail - nextCursor < paddingThreshold) { LOGGER.info("Reach the padding threshold:{}. tail:{}, cursor:{}, rest:{}", paddingThreshold, currentTail, nextCursor, currentTail - nextCursor); bufferPaddingExecutor.asyncPadding(); } // cursor catch the tail, means that there is no more available UID to take if (nextCursor == currentCursor) { rejectedTakeHandler.rejectTakeBuffer(this); } // 1. check next slot flag is CAN_TAKE_FLAG int nextCursorIndex = calSlotIndex(nextCursor); Assert.isTrue(flags[nextCursorIndex].get() == CAN_TAKE_FLAG, "Curosr not in can take status"); // 2. get UID from next slot // 3. set next slot flag as CAN_PUT_FLAG. long uid = slots[nextCursorIndex]; flags[nextCursorIndex].set(CAN_PUT_FLAG); // Note that: Step 2,3 can not swap. If we set flag before get value of slot, the producer may overwrite the // slot with a new UID, and this may cause the consumer take the UID twice after walk a round the ring return uid; }
In addition, there is a detail to understand that RingBuffer data is stored in arrays. Considering the structure of CPU Cache, if tail and cursor variables are directly of native AtomicLong type, tail and cursor may be cached in the same cacheline. Reading this variable by multiple threads may cause RFO requests of cacheline, but affect performance. To prevent pseudo sharing problems , specially filled in 6 long type member variables, plus value member variables of long type, just occupy a Cache Line (Java object also has 8 byte object header). This is called cacheline completion. You can learn about it if you are interested. The source code is as follows:
public class PaddedAtomicLong extends AtomicLong { private static final long serialVersionUID = -3415778863941386253L; /** Padded 6 long (48 bytes) */ public volatile long p1, p2, p3, p4, p5, p6 = 7L; /** * Constructors from {@link AtomicLong} */ public PaddedAtomicLong() { super(); } public PaddedAtomicLong(long initialValue) { super(initialValue); } /** * To prevent GC optimizations for cleaning unused padded references */ public long sumPaddingToPreventOptimization() { return p1 + p2 + p3 + p4 + p5 + p6; } }
The above is the main description of Baidu uid generator project. We can find that there are some changes in the snowflake algorithm when it lands, mainly reflected in the acquisition of machine ID, especially in the distributed cluster environment. Some technologies such as instance auto scaling and docker containerization make the feasibility of static configuration of project ID and instance ID low, so these are transformed into identification by startup times. .
ECP uid project of meituan
In terms of uidGenerator, meituan's project source code is directly integrated with Baidu's source code, slightly replacing some Lambda expressions with native java syntax, such as:
// initRingBuffer() method of com.myzmds.ecp.core.uid.baidu.impl.CachedUidGenerator class // Baidu source code this.bufferPaddingExecutor = new BufferPaddingExecutor(ringBuffer, this::nextIdsForOneSecond, usingSchedule); // US group source code this.bufferPaddingExecutor = new BufferPaddingExecutor(ringBuffer, new BufferedUidProvider() { @Override public List<Long> provide(long momentInSecond) { return nextIdsForOneSecond(momentInSecond); } }, usingSchedule);
In the aspect of machine ID generation, Zookeeper and Redis are introduced to enrich the generation and acquisition methods of machine ID. the instance number can be stored and used repeatedly, which is no longer the monotonous growth of database.
Concluding remarks
This paper briefly introduces the principle of snowflake algorithm and the transformation in the process of landing. In this paper, we learn the excellent open source code, and select some simple examples. Meituan's ECP uid project not only integrates Baidu's existing uid generator algorithm, the original snowflake algorithm, but also includes the excellent leaf segment algorithm. In view of the lack of detailed description. Please leave a message to point out any inaccuracy or incompleteness in the article. Thank you.
Focus on Java high concurrency, distributed architecture, more technology dry goods sharing and experience, please pay attention to the public number: Java architecture community
