Introducer
I saw the Jekyll Phoenix movie a while ago, and I was very curious about what the audience would say about it after watching the movie. After watching the Douban short review, I thought that python would extract the most words in the short review and make a word cloud to see what the key words left for the audience.
Grab data
at the beginning, we used requests to simulate data grabbing. It was found that users who log in to Douban need to have permission to view after turning the page of short comments to 20 pages. So we plan to use selenium to simulate browser action to automatically crawl down the data in the page, and then store it to a specific txt file. Because we have no intention to do other analysis, we do not plan to store it to a number. According to the library.
About selenium and chrome driver installation
the working principle of selenium, a popular automatic testing framework, and the corresponding version installation of selenium and chrome driver will not be described in detail. Students who are interested can refer to:
https://blog.csdn.net/weixin_43241295/article/details/83784692
Analyze the user login process of Douban login page
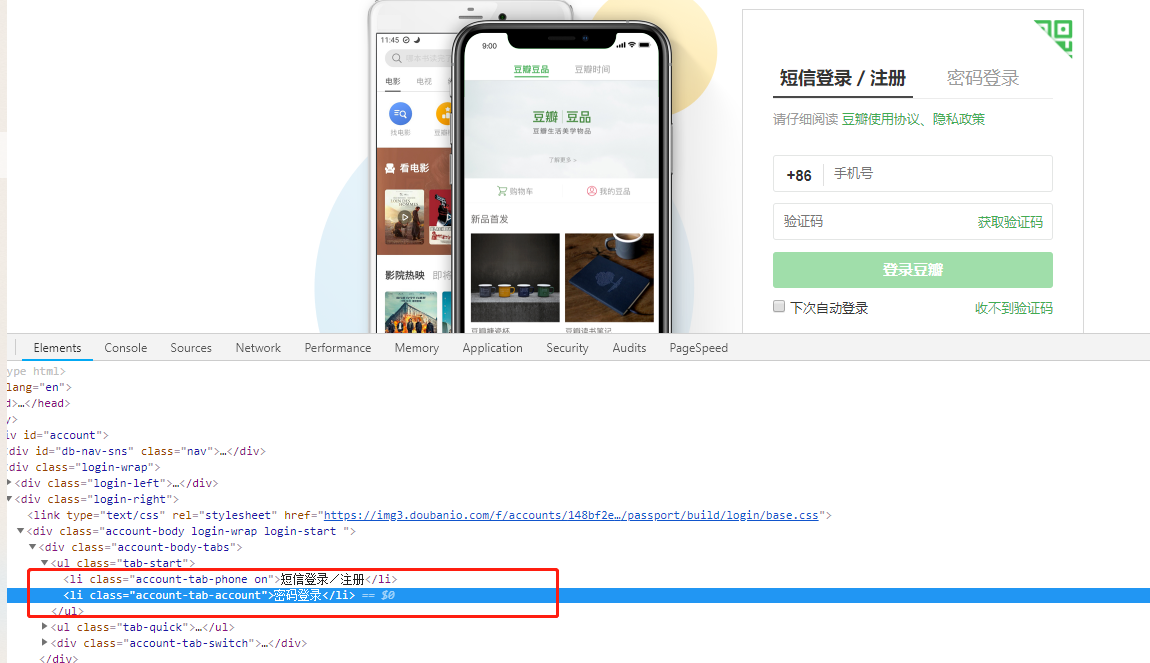
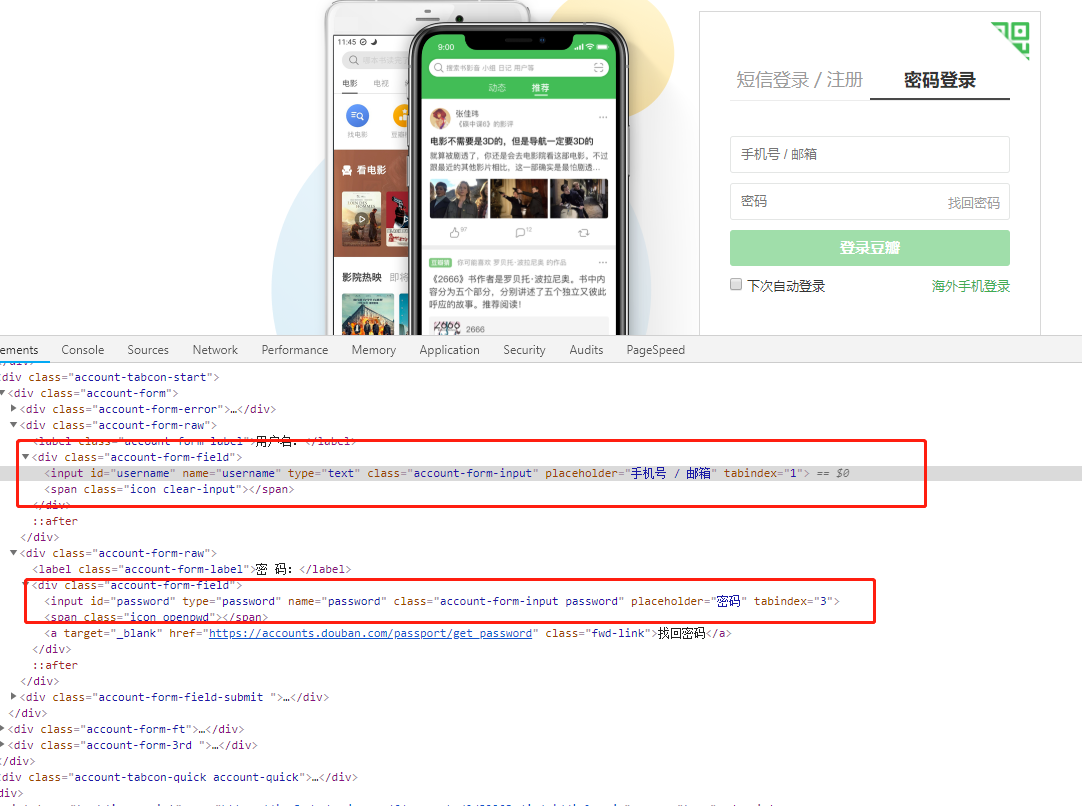
from the page, it seems that the process is to click the password in the navigation bar to log in, then enter the user name and password, and click the login button. As for the verification pictures that will appear when I look at some bean petal reptiles on the Internet, I haven't met them. I just log in directly, so I need to simulate the whole login process through selenium.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def crawldouban():
name = "Your user name"
passw = "Your password"
# Start chrome
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
browser = webdriver.Chrome(executable_path="/usr/bin/chromedriver", options=options)
# Get login address
browser.get("https://accounts.douban.com/passport/login")
time.sleep(3)
# Login automation process
browser.find_element_by_class_name("account-tab-account").click()
form = browser.find_element_by_class_name("account-tabcon-start")
username = form.find_element_by_id("username")
password = form.find_element_by_id("password")
username.send_keys(name)
password.send_keys(passw)
browser.find_element_by_class_name("account-form-field-submit").click()
time.sleep(3)Get user comments
the next step is to get the comments on the page, and then store the comments in the specified text file (I will not simulate the whole process of querying the movie, then jump to the short comment), start directly from the address of the short comment page, click the next page, and then repeatedly extract the comments, and write them.
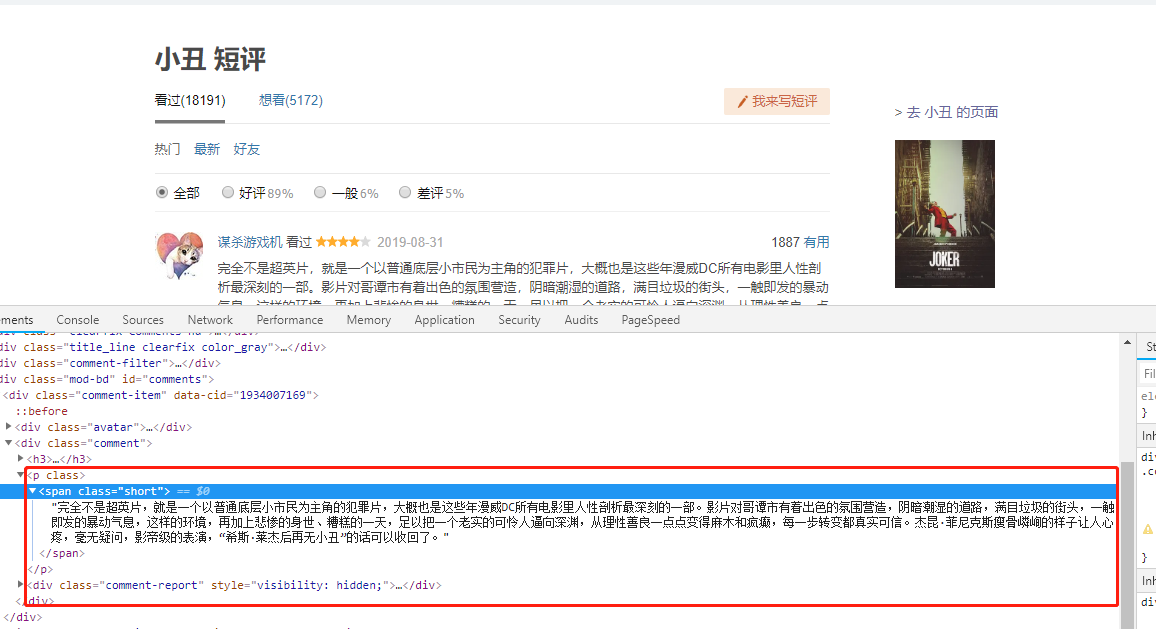
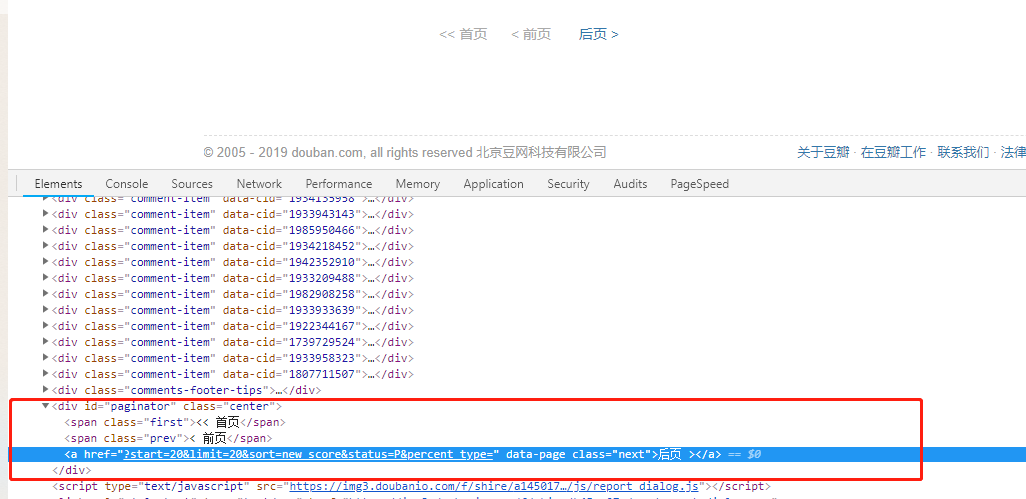
browser.get("https://movie.douban.com/subject/27119724/comments?status=P")
comments = browser.find_elements_by_class_name("short")
WriteComment(comments)
while True:
link = browser.find_element_by_class_name("next")
path = link.get_attribute('href')
if not path:
break
# print(path)
link.click()
time.sleep(3)
comments = browser.find_elements_by_class_name("short")
WriteComment(comments)
browser.quit()
# Write comments to the specified text file
def WriteComment(comments):
with open("comments.txt", "a+") as f:
for comment in comments:
f.write(comment.text+" \n") code parsing: there's nothing to say about the captured code. It's just to find the element whose classname is' short ', and get the text content and write it to the specified text file. There's a loop in it to judge whether there's another page. By getting the hyperlink of the next page, it can be proved that it's on the last page when it can't be obtained.
Data segmentation and word cloud generation
let's talk about the idea. My data processing here is relatively rough. Without the combination of pandas+numpy, I will simply cut the line breaks and form new data. Then I will use the jieba segmentation to segment the new data. Finally, I will read a local pause word file to get a pause word list. Generate word cloud to specify pause word, font file, background color, etc., and then save word cloud image to local.
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
# Process content read from text
def text_read(file_path):
filename = open(file_path, 'r', encoding='utf-8')
texts = filename.read()
texts_split = texts.split("\n")
filename.close()
return texts_split
def data_handle(picture_name):
# Read data crawled from the website
comments = text_read("comments.txt")
comments = "".join(comments)
# Participle, read pause words
lcut = jieba.lcut(comments)
cut_text = "/".join(lcut)
stopwords = text_read("chineseStopWords.txt")
# Generate word cloud
bmask = imread("backgrounds.jpg")
wordcloud = WordCloud(font_path='/usr/share/fonts/chinese/simhei.ttf', mask=bmask, background_color='white', max_font_size=250, width=1300, height=800, stopwords=stopwords)
wordcloud.generate(cut_text)
wordcloud.to_file(picture_name)
if __name__ == "__main__":
data_handle("joker6.jpg")This is a picture I snapped myself as the background:

Final rendering:

summary
it took about two nights to write crawlers to analyze data, to have ideas and to sort out the tools needed. On the whole, there are still some simple and easy to understand things. For large-scale concurrent collection of reptiles and data analysis and other contents, it is still interesting to record their own learning process.