text
Recently, I was doing a requirement development: according to the different requests, nginx will distribute the requests to different back-end services. It is necessary to modify the source code of kubernetes's ingress-nginx-controller. When debugging, there are quite a lot of problems. Let's not talk about the specific scheme, just about nginx configuration.
First, paste the component version: The version of ingress nginx controller is 0.9-beta.18. You can find the open source project source code on github:
nginx map configuration allocates traffic to different back-end services according to different request headers Nginx version: nginx version: nginx/1.13.7
An error is reported in the map configuration:
The file of nginx.conf is as follows:
http { include /etc/nginx/conf.d/server-map.d/*-map.conf; include /etc/nginx/conf.d/*-upstream.conf; include /etc/nginx/conf.d/server-map.d/*-server.conf; .... map_hash_bucket_size 64; .... }
In the directory / etc/nginx/conf.d/server-map.d/flow-ppp-map.conf:
map $http_x_group_env $svc_upstream { default zxl-test-splitflow-old-version; ~*old zxl-test-splitflow-old-version; ~*new zxl-test-splitflow-new-version; }
flow-ppp-server.conf
server { listen 8998; server_name aa.hc.harmonycloud.cn; location /testdemo/test { proxy_pass http://$svc_upstream; } }
ingressgroup-upstream.conf
upstream zxl-test-splitflow-old-version { server 10.168.173.29:8080 max_fails=0 fail_timeout=0; } upstream zxl-test-splitflow-new-version { server 10.168.177.171:8080 max_fails=0 fail_timeout=0; }
When the nginx -tc /etc/nginx/nginx.conf test configuration is correct or not, an error will be reported as follows:
Error: exit status 1 nginx: [emerg] "map_hash_bucket_size" directive is duplicate in /etc/nginx/nginx.conf:60 nginx: configuration file c test failed

Solve:
This is because when the map is called for the first time, it will implicitly set the map ﹣ hash ﹣ bucket ﹣ size. That is to say, writing the map ﹣ hash ﹣ bucket ﹣ size after the map in nginx is equivalent to setting the map ﹣ hash ﹣ bucket ﹣ size twice, for example:
http { ... map $status $_status { default 42; } map_hash_bucket_size 64; ... }
So you can set it before the map, as shown below.
http { map_hash_bucket_size 64; ... map $status $_status { default 42; } ... }
Therefore, the include map configuration should also be placed after the map hash bucket size setting:
http { ... map_hash_bucket_size 64; ... include /etc/nginx/conf.d/server-map.d/*-map.conf; include /etc/nginx/conf.d/*-upstream.conf; include /etc/nginx/conf.d/server-map.d/*-server.conf; }
map configuration description:
Through the above three include configuration files, the configuration that finally takes effect on nginx should be as follows:
http { ... map_hash_bucket_size 64; ... map $http_x_group_env $svc_upstream { default zxl-test-splitflow-old-version; ~*old zxl-test-splitflow-old-version; ~*new zxl-test-splitflow-new-version; } upstream zxl-test-splitflow-old-version { server 10.168.173.29:8080 max_fails=0 fail_timeout=0; } upstream zxl-test-splitflow-new-version { server 10.168.177.171:8080 max_fails=0 fail_timeout=0; } server { listen 8998; server_name aa.hc.harmonycloud.cn; location /testdemo/test { proxy_pass http://$svc_upstream; } } }
After the aa.hc.harmonycloud.cn domain name resolution is configured in the hosts file on the computer, visit When http://aa.hc.harmonycloud.cn:8998/testdemo/test (that is, the configuration of server name, listen and location of the server), nginx will forward the request to http: / / $SVC ﹣ upstream. What exactly is this $SVC ﹣ upstream? It is assigned by map configuration. The map configuration here is as follows:
map $http_x_group_env $svc_upstream { default zxl-test-splitflow-old-version; ~*old zxl-test-splitflow-old-version; ~*new zxl-test-splitflow-new-version; }
Where $http ﹣ x ﹣ group ﹣ env can be a nginx built-in variable, or a user-defined header's key and request parameter name; $SVC ﹣ upstream is the user-defined variable name. The meaning of configuration here is: when the value of x-group-env in the request header is old, $SVC ﹐ upstream is assigned to zxl test splitflow old version; when the value of x-group-env in the request header is new, $SVC ﹐ upstream is assigned to zxl test splitflow new version; the default value is zxl test splitflow old version; (if the regular expression starts with "~", it means that the regular expression is case sensitive. Starting with "~ *" indicates that the regular expression is not case sensitive). Zxl test splitflow new version and zxl test splitflow old version represent two upstream names.
So nginx will forward the request to Http: / / $SVC ﹣ upstream, where $SVC ﹣ upstream will be replaced with the name of the upstream, and finally the back-end service IP and Port in the upstream will be obtained.
Note: if we define the header as X-Real-IP, we need to get the header through the second nginx as follows: $http ﹐ x ﹐ real ﹐ IP; (all are in lowercase, and there are more than one http ﹐ in front and replaced with ﹐ in the middle).
test
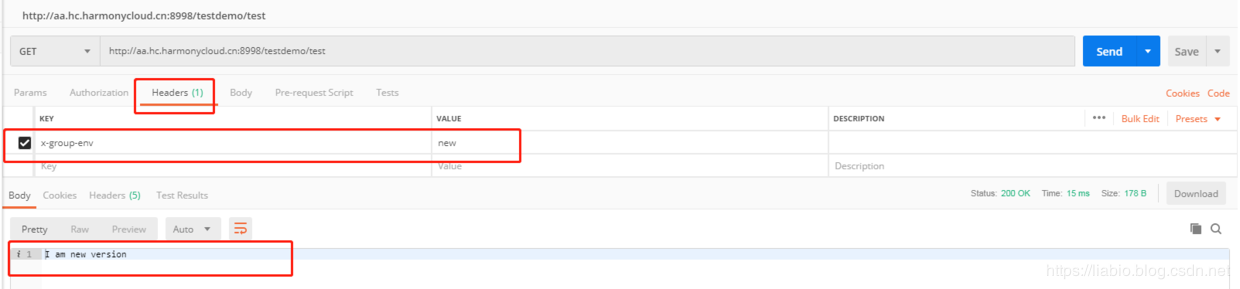
When the x-group-env in the request header is new, I am new version will be printed out when accessing the backend.
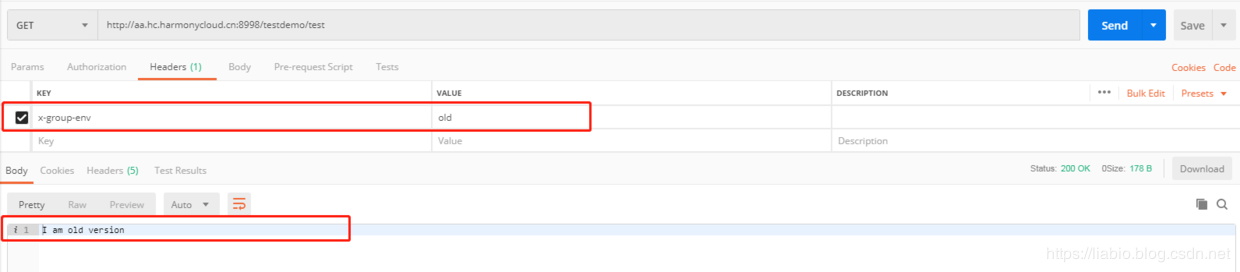
When x-group-env is added in the request header as old, I am old version will be printed out when accessing the backend.
Finally, traffic is allocated to different back-end services through different request headers.
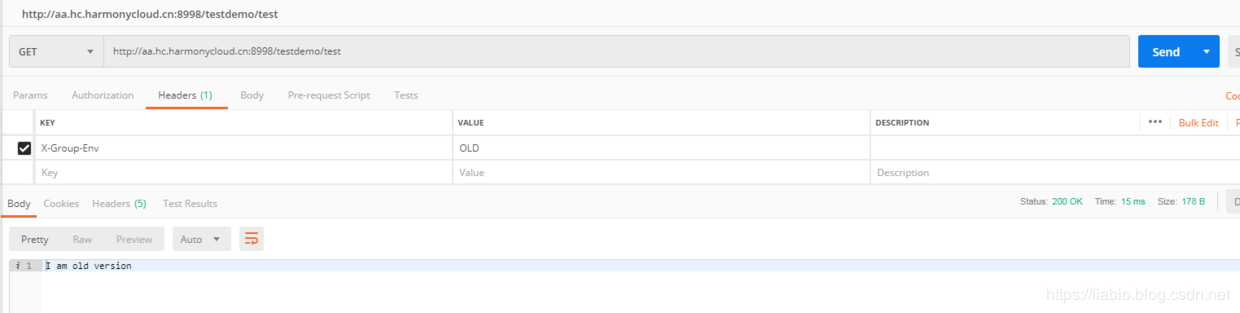
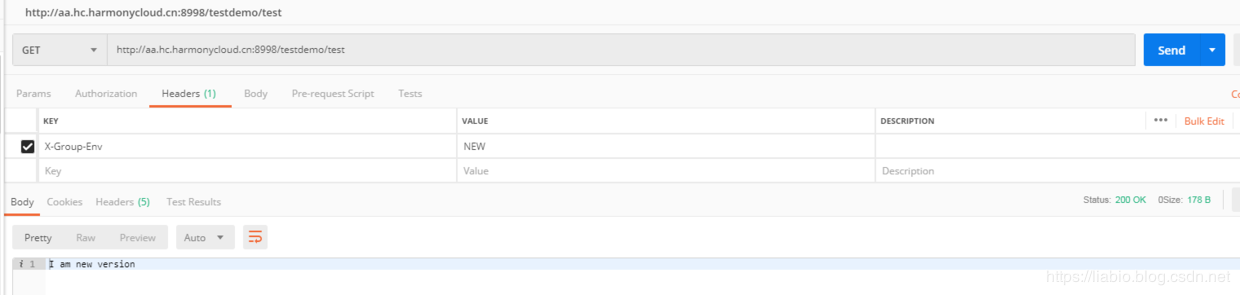
Changing the key of the request header to X-Group-Env and the value to OLD or NEW does not matter either:
This public account is free * * to provide csdn download service and massive it learning resources * * if you are ready to enter the IT pit and aspire to become an excellent program ape, these resources are suitable for you, including but not limited to java, go, python, springcloud, elk, embedded, big data, interview materials, front-end and other resources. At the same time, we have set up a technology exchange group. There are many big guys who will share technology articles from time to time. If you want to learn and improve together, you can reply [2] in the background of the public account. Free invitation plus technology exchange groups will learn from each other and share programming it related resources from time to time.
Scan the code to pay attention to the wonderful content and push it to you at the first time
