This paper will focus on the analysis of Elastic Job's fragmentation mechanism:
Elastic Job fragmentation mechanism:
- When Elastic Job starts, it first starts the listener that needs to be re-fragmented.
See the code: ListenerManager startAllListeners {...; shardingListenerManager. start ();...}. - Before the task is executed, fragmentation information needs to be acquired. If it needs to be re-fragmented, the main server performs the fragmentation algorithm, while the other slave servers wait until the fragmentation is completed.
See: AbstractElastic Job Executor execute {...; jobFacade. getShardingContexts ();...;}
1. Detailed Explanation of Piecewise Management Monitor
ElasticJob's event listener manager implementation class is AbstractListener Manager.
The class diagram is as follows:
-
JobNode Storage jobNode Storage: Job node operation API.
Its core methods are:- public abstract void start(): start the monitor manager, which is implemented by the subclass.
- protected void addDataListener(TreeCacheListener listener): Increase event listeners.
Elastic Job's Selected Listener Manager, Piecewise Listener Manager, and Fault Transfer Listener Manager are all subclasses of AbstractListener Manager. The fragmentation-related listener manager class diagram is shown as follows: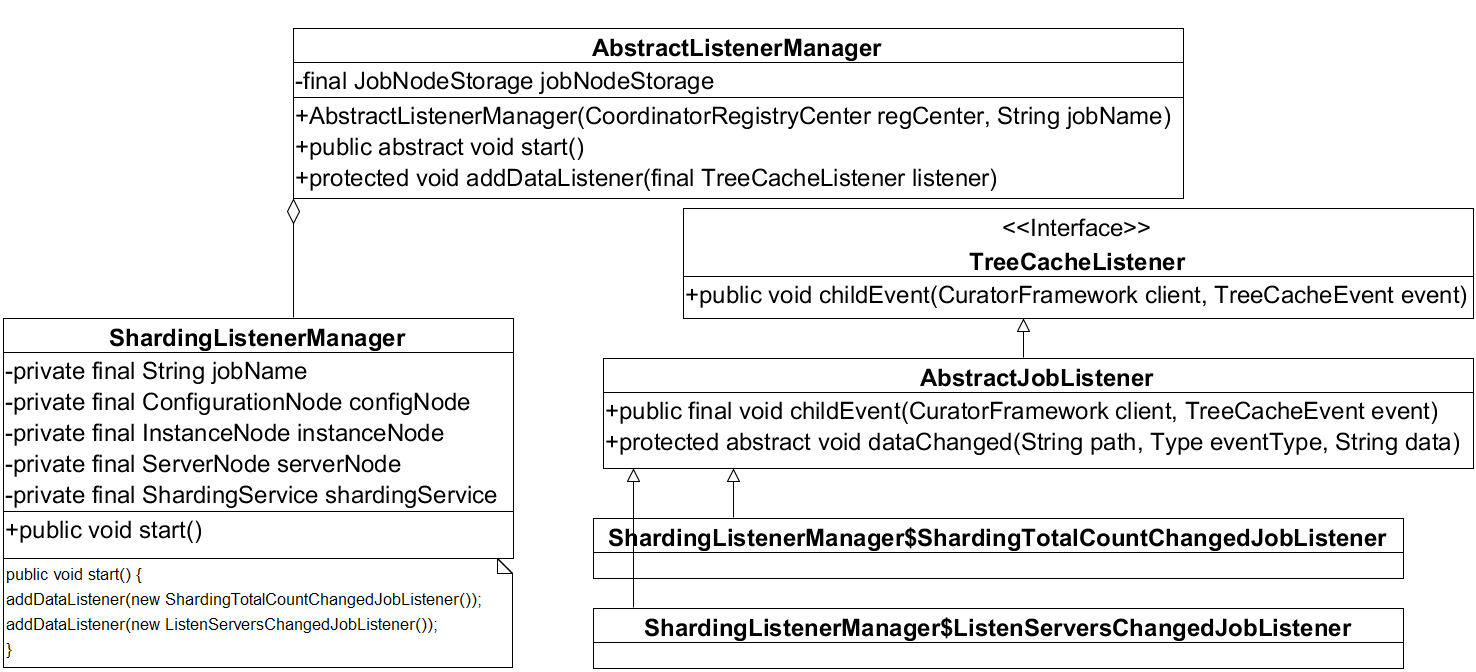
- ShardingListener Manager: Piecewise Listener Manager.
- Sharing Total CountChanged JobListener: The event manager that listens to the total number of fragments is a subclass of TreeCacheListener (curator's event listener).
- ListenServers Changed JobListener: Event listeners after the number of job servers (runtime instances) has changed.
1.1 Source Analysis Sharing Total Count Changed JobListener listener
class ShardingTotalCountChangedJobListener extends AbstractJobListener { @Override protected void dataChanged(final String path, final Type eventType, final String data) { if (configNode.isConfigPath(path) && 0 != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) { int newShardingTotalCount = LiteJobConfigurationGsonFactory.fromJson(data).getTypeConfig().getCoreConfig().getShardingTotalCount(); if (newShardingTotalCount != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) { shardingService.setReshardingFlag(); JobRegistry.getInstance().setCurrentShardingTotalCount(jobName, newShardingTotalCount); } } } }
The total number of fragmented nodes configured by job changes listeners (Elastic Job allows you to modify the total number of fragments per task configuration through the Web interface).
job configuration information is stored on the ${namespace}/jobname/config node, and the content is in json format.
If the content of the ${namespace}/jobname/config node changes, zk triggers the node data change event of the node. If the number of fragmented nodes stored in zk is different from the number of fragmented nodes in memory, calling ShardingService setting requires a re-fragmentation tag (creating ${namespace}/ jobname/leader/sharding/necessity persistent node) and updating the fragmented section in memory. Total number of points.
1.2 Source Analysis ListenServers Changed JobListener listener
class ListenServersChangedJobListener extends AbstractJobListener { @Override protected void dataChanged(final String path, final Type eventType, final String data) { if (!JobRegistry.getInstance().isShutdown(jobName) && (isInstanceChange(eventType, path) || isServerChange(path))) { shardingService.setReshardingFlag(); } } private boolean isInstanceChange(final Type eventType, final String path) { return instanceNode.isInstancePath(path) && Type.NODE_UPDATED != eventType; } private boolean isServerChange(final String path) { return serverNode.isServerPath(path); } }
When the number of fragmented nodes (instances) changes, event listeners need to be re-fragmented when new fragmented nodes are added or the original fragmented instance is down.
Whether the number of nodes under ${namespace}/jobname/servers or ${namespace}/jobname/instances path changes or not, if a change is detected, the setting needs to be re-fragmented.
2. Specific Piecewise Logic
The detailed analysis of the slicing monitoring manager, its function is to monitor a specific ZK directory, when it changes, to determine whether it needs to set up the reprint mark. When set up the need to re fragment the mark, when will trigger the refragmentation?
Before each task is executed, the first thing is to get the slice information (piecewise context), and then pull different data from the server according to the fragment information to process the task. Its source entry is AbstractElasticJobExecutor#execute.
jobFacade.getShardingContexts() method.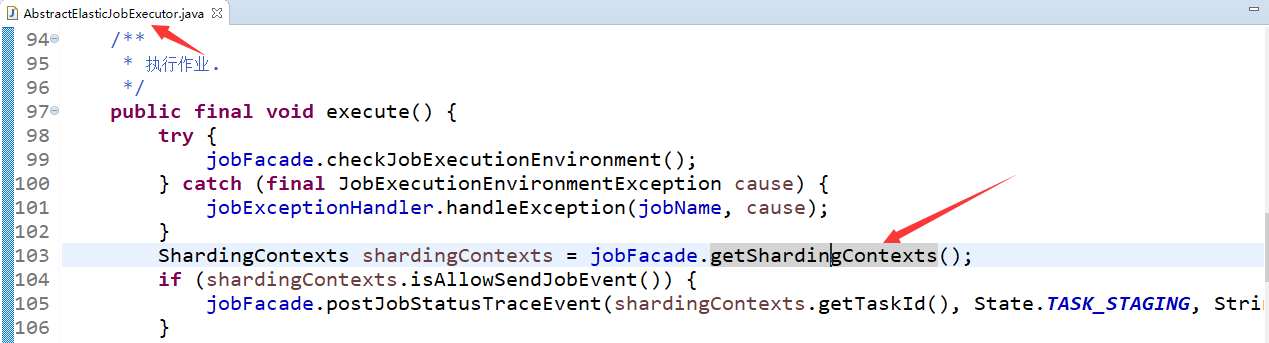
The specific implementation code is LiteJobFacade#getShardingContexts.
public ShardingContexts getShardingContexts() { boolean isFailover = configService.load(true).isFailover(); // @1 if (isFailover) { List<Integer> failoverShardingItems = failoverService.getLocalFailoverItems(); if (!failoverShardingItems.isEmpty()) { return executionContextService.getJobShardingContext(failoverShardingItems); } } shardingService.shardingIfNecessary(); // @2 List<Integer> shardingItems = shardingService.getLocalShardingItems(); // @3 if (isFailover) { shardingItems.removeAll(failoverService.getLocalTakeOffItems()); } shardingItems.removeAll(executionService.getDisabledItems(shardingItems)); // @4 return executionContextService.getJobShardingContext(shardingItems); // @5 }
Code @1: Whether or not to start failover, this article focuses on Elastic Job's fragmentation mechanism, failover is described in detail in the next article, this article assumes that failover is not enabled.
Code @2: If necessary, perform fragmentation. If there is no fragmentation information (first fragmentation) or need to be re-fragmented, then perform the fragmentation algorithm. Next, the implementation logic of fragmentation is analyzed in detail.
Code @3: Get local fragmentation information. All instance nodes under ${namespace}/jobname/sharding/{fragmentation item} are traversed to determine whether the value of jobinstanceId is equal to the current jobInstanceId, and the equivalent is considered to be the fragmentation information of the node.
Code @4: Remove locally disabled fragments and store directories for locally disabled fragments are ${namespace}/jobname
/ sharding/{piecewise item}/disable.
Code @ 5: returns the fragment context environment of the current node. This is mainly to build ShardingContexts object according to the configuration information (fragment parameters) and the current fragment instance.
2.1 shardingService.shardingIfNecessary Explanation [Piecewise Logic]
/** * If fragmentation is required and the current node is the primary node, then job fragmentation. * * <p> * If there are no currently available nodes, they are not fragmented. * </p> */ public void shardingIfNecessary() { List<JobInstance> availableJobInstances = instanceService.getAvailableJobInstances(); // @1 if (!isNeedSharding() || availableJobInstances.isEmpty()) { // @2 return; } if (!leaderService.isLeaderUntilBlock()) { // @3 blockUntilShardingCompleted(); //@4 return; } waitingOtherJobCompleted(); // @5 LiteJobConfiguration liteJobConfig = configService.load(false); int shardingTotalCount = liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount(); // @5 log.debug("Job '{}' sharding begin.", jobName); jobNodeStorage.fillEphemeralJobNode(ShardingNode.PROCESSING, ""); // @6 resetShardingInfo(shardingTotalCount); // @7 JobShardingStrategy jobShardingStrategy = JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass()); // @8 jobNodeStorage.executeInTransaction(new PersistShardingInfoTransactionExecutionCallback(jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount))); // @9 log.debug("Job '{}' sharding complete.", jobName); }
Code @1: Get the currently available instance. First, get all the child nodes in the ${namespace}/jobname/instances directory, and determine whether the server where the IP of the instance node is available. If the value stored by the ${namespace}/jobname/servers/ip node is not DISABLE, the node is considered available.
Code @2: If you don't need to re-fragment (${namespace}/jobname/leader/sharding)
/ necessary node does not exist) or currently does not exist an available instance, then returns.
Code @3, to determine whether it is the primary node, if the primary node is currently being elected, then block until the elector is completed, block the code used here as follows:
while (!hasLeader() && serverService.hasAvailableServers()) { // If there are no instances available for the primary node to discard, Thread.sleep() triggers a selector once. log.info("Leader is electing, waiting for {} ms", 100); BlockUtils.waitingShortTime(); if (!JobRegistry.getInstance().isShutdown(jobName) && serverService.isAvailableServer(JobRegistry.getInstance().getJobInstance(jobName).getIp())) { electLeader(); } } return isLeader();
Code @4: If the current node is not the primary node, wait for the fragmentation to end. The criterion for the end of fragmentation is whether the ${namespace}/ jobname/leader/sharding/necessity node exists or the ${namespace}/jobname/leader/sharding/processing node exists (indicating that the fragmentation operation is being performed). If the fragmentation is not finished, use the Thread.sleep method to block 100 mm and try again.
Code @5: Enter here, indicating that the node is the primary node. Before the main node performs fragmentation, it first waits for the batch of tasks to be completed. The way to judge whether other tasks are running is to determine whether there is ${namespace}/jobname/sharding/{fragmentation item}/running, and if there exists, Thread.sleep(100) is used, and then to judge.
Code @6: Create a temporary node ${namespace}/jobname/leader/sharding/processing node to indicate that the fragment is executing.
Code @7: Reset fragmentation information. Delete the & dollar; {namespace}/ jobname/sharding/{fragmented item}/instance node first, and then create the ${namespace}/ jobname/sharding/{fragmented item} node (if necessary). Then, according to the total number of fragments currently configured, if the current number of ${namespace}/jobname/sharding subnodes is larger than the number of fragmented nodes configured, the redundant nodes (from large to small) are deleted.
Code @8: Get the configuration of the fragmentation algorithm class, the commonly used fragmentation algorithm is the Average Allocation Job Sharing Strategy.
Code @9: Create the corresponding fragment instance information ${namespace}/jobname/{fragment item}/instance within a transaction, and the content stored by the node is the ID of the JobInstance instance.
Perform transactional operations in ZK: JobNodeStorage#executeInTransaction
/** * Perform operations in a transaction. * * @param callback Callbacks to perform operations */ public void executeInTransaction(final TransactionExecutionCallback callback) { try { CuratorTransactionFinal curatorTransactionFinal = getClient().inTransaction().check().forPath("/").and(); // @1 callback.execute(curatorTransactionFinal); // @2 curatorTransactionFinal.commit(); //@3 //CHECKSTYLE:OFF } catch (final Exception ex) { //CHECKSTYLE:ON RegExceptionHandler.handleException(ex); } }
Code @1, using the inTransaction() method of Curator Framework Factory, cascade call check(), and finally return the Curator Transaction Final instance through the and() method, which executes all update node commands in the transaction. The commit() command is then executed to submit uniformly (this method guarantees either total success or total failure).
Code @2, which executes the specific logic by calling back the PersistSharing InfoTransaction Execution Callback method.
Code @3, commit transaction.
See Sharing Service $PersistSharing Info Transaction Execution Callback for the code
class PersistShardingInfoTransactionExecutionCallback implements TransactionExecutionCallback { private final Map<JobInstance, List<Integer>> shardingResults; @Override public void execute(final CuratorTransactionFinal curatorTransactionFinal) throws Exception { for (Map.Entry<JobInstance, List<Integer>> entry : shardingResults.entrySet()) { for (int shardingItem : entry.getValue()) { curatorTransactionFinal.create().forPath(jobNodePath.getFullPath(ShardingNode.getInstanceNode(shardingItem)), entry.getKey().getJobInstanceId().getBytes()).and(); // @1 } } curatorTransactionFinal.delete().forPath(jobNodePath.getFullPath(ShardingNode.NECESSARY)).and(); // @2 curatorTransactionFinal.delete().forPath(jobNodePath.getFullPath(ShardingNode.PROCESSING)).and(); // @3 } }
Code @1: The so-called fragmentation is mainly to create ${namespace}/jobname/sharding/{fragmentation item}/instance, and the content of the node is JobInstance ID.
Code @2: Delete the ${namespace}/ jobname/leader/sharding/necessity node.
Code @3: Delete the ${namespace}/jobname/leader/sharding/processing node to indicate the end of fragmentation.
The following section concludes with a piecewise flow chart: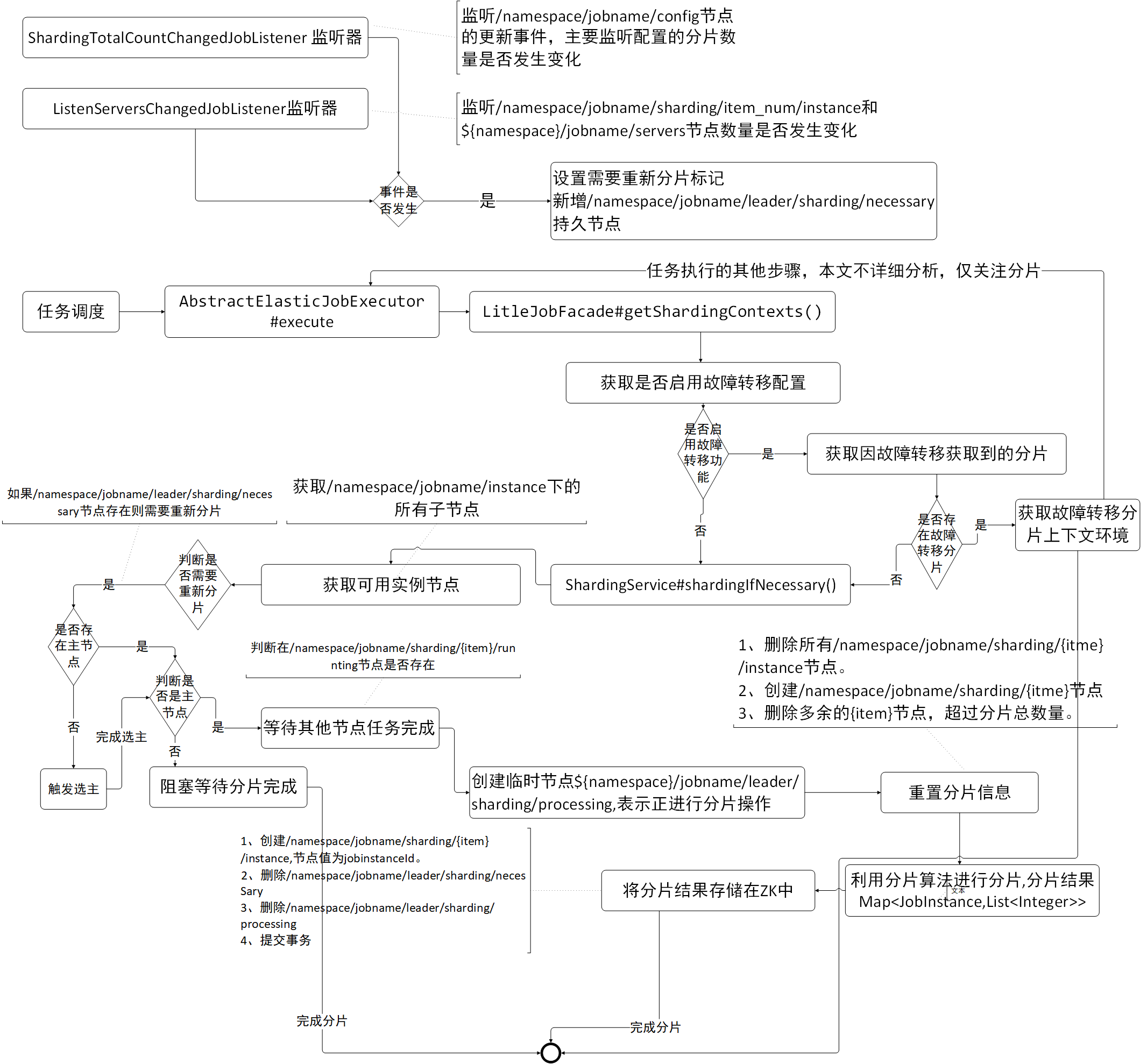
The original release date is 2018-12-02.
Author: Ding Wei, author of RocketMQ Technology Insider.
This article comes from Interest Circle of Middleware To learn about relevant information, you can pay attention to it. Interest Circle of Middleware.