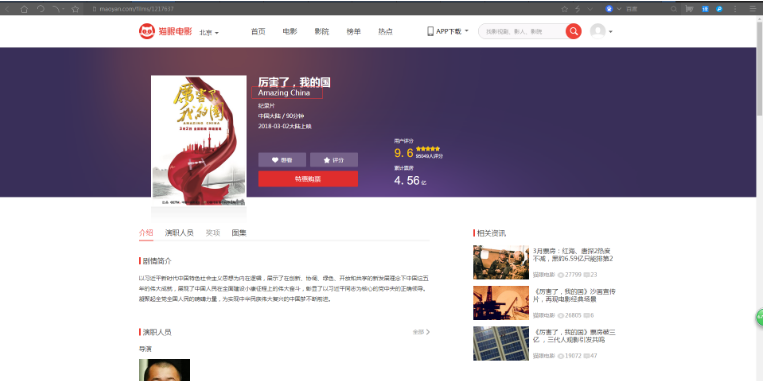
&
[root@xxn maoyan]# cat cat.py
#!/usr/bin/env python
#coding:utf-8
import requests
from bs4 import BeautifulSoup
def movieurl(url):
"""
//One-page url address for getting movies
"""
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36",
}
response = requests.get(url,headers=headers,timeout=10)
soup= BeautifulSoup(response.text,'lxml')
href = soup.find_all('div',class_="channel-detail movie-item-title")[0]
movieurl = "http://maoyan.com%s" % href.find('a')['href']
return movieurl
def moveinfo(url):
"""
//Get the movie's Chinese name, box office unit.
//If the box office unit does not have data, it means that the box office is "temporarily not available".
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36",
}
response = requests.get(url, headers=headers,timeout=5)
soup = BeautifulSoup(response.text, 'lxml')
Chinesename = soup.find('div',class_="movie-brief-container").h3.string
try:
boxofficeunit = soup.find_all('div',class_="movie-index-content box")[0].find('span',class_='unit').string
except:
boxofficeunit = 0
return Chinesename,boxofficeunit
if __name__ == '__main__':
Moviename = input("Please enter the English name of the movie:")
Moviename = Moviename.replace(' ','+')
url = "http://maoyan.com/query?kw=%s&type=0" % Moviename
Chinesename, boxofficeunit = moveinfo(movieurl(url))
print Chinesename,boxofficeunit
&
[root@xxn maoyan]# cat maoyan.py
#!/usr/bin/env python
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import random
from PIL import Image
import pytesseract
import os
import cat
def imagedownlod(url):
"""
//Save a screenshot of a single page of a movie, because we need to get box office data, so we don't load pictures to speed up the process.
"""
dcap = dict(DesiredCapabilities.PHANTOMJS)
USER_AGENTS=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4882.400 QQBrowser/9.7.13059.400'
]
#Choose a browser header randomly from the USER_AGENTS list to disguise the browser
dcap["phantomjs.page.settings.userAgent"] = (random.choice(USER_AGENTS))
driver = webdriver.PhantomJS(desired_capabilities=dcap)
# Without loading pictures, page crawling will be much faster
dcap["phantomjs.page.settings.loadImages"] = False # Disable loading of pictures
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_window_size(1366, 3245)
driver.get(url)
driver.save_screenshot("maoyan.png")
def crop_image(image_path,crop_path):
"""
//Originally, we wanted to use webdriver to get the location of box office elements, and then calculate four parameters according to the location and size of the elements. The location can be obtained normally, but the size of the picture is different, so the matting will be problematic.
//So change the way: I change the screenshots of each page to a uniform size, because the box office is fixed, so this can make the crawler stronger.
"""
# Calculating Absolute Coordinates of Cut-out Area
left = 668
top = 388
right = 668+158
bottom = 388+54
# Open the picture, extract the corresponding area and store it.
img = Image.open(image_path)
out = img.resize((1366, 3245),Image.ANTIALIAS) #resize image with high-quality
out.save('maoyannew.png')
im = Image.open('maoyannew.png')
im = im.crop((left, top, right, bottom))
im.save(crop_path)
os.remove('maoyannew.png')
def words(image):
"""
//Because we normalize pictures of different sizes, some pictures pytesseract can't recognize numbers.
//So I do gray processing first, and then use the parameter config="-psm 8-c tessedit_char_whitelist=1234567890".
"""
im = Image.open(image).convert('L')
im.save(image)
number = pytesseract.image_to_string(Image.open(image),config="-psm 8 -c tessedit_char_whitelist=1234567890")
os.remove(image)
return number
if __name__ == '__main__':
Moviename = input("Please enter the English name of the movie:")
Moviename = Moviename.replace(' ','+')
url = "http://maoyan.com/query?kw=%s&type=0" % Moviename
Chinesename,boxofficeunit = cat.moveinfo(cat.movieurl(url))
imagedownlod(cat.movieurl(url))
crop_image('maoyan.png','piaofang.png')
print words('piaofang.png')
os.remove('maoyan.png')
&
[root@xxn maoyan]# cat catseye.py
#!/usr/bin/env python
# coding=utf-8
import cat
import maoyan
import sys
import os
reload(sys)
sys.setdefaultencoding('utf8')
def main():
moviename = input("Please enter the English name of the movie:")
Moviename = moviename.replace(' ','+')
Moviename = moviename.replace(':','%3A')
url = "http://maoyan.com/query?kw=%s&type=0" % Moviename
Chinesename,boxofficeunit = cat.moveinfo(cat.movieurl(url))
if boxofficeunit == 0:
"""
//If the box office unit is zero, that is, nonexistent, then the movie box office is temporary, so we do not need to dig to identify the number.
"""
print "The English name of the movie you searched for:" + moviename
print "The Chinese name of the movie you searched for:" + Chinesename
print "The box office you are searching for:" + 'No time'
else:
maoyan.imagedownlod(cat.movieurl(url))
maoyan.crop_image('maoyan.png','piaofang.png')
number = maoyan.words('piaofang.png')
print "The English name of the movie you searched for:" + moviename
print "The Chinese name of the movie you searched for:" + Chinesename
print "The box office you are searching for:" + str(number2) + str(boxofficeunit)
os.remove('maoyan.png')
if __name__ == '__main__':
main()
If you are still confused in the world of programming, you can join our Python learning button qun: 784758214 to see how our predecessors learned! Exchange experience! I am a senior Python development engineer, from basic Python scripts to web development, crawler, django, data mining, etc. To every little friend of Python! Share some learning methods and small details that need attention. Click to join us. python learner gathering place
Test: