We customize a main.py as the startup file
main.py
#!/usr/bin/env python # -*- coding:utf8 -*- from scrapy.cmdline import execute #Import and execute scrapy command method import sys import os sys.path.append(os.path.join(os.getcwd())) #Add a new path to the Python interpreter, and add the directory of the main.py file to the Python interpreter execute(['scrapy', 'crawl', 'pach', '--nolog']) #Execute the scrapy command
Crawler file
What can I learn from my learning process?
python Learning Exchange Button qun,784758214
//There are good learning video tutorials, development tools and e-books in the group.
//Share with you python enterprise talent demand and how to learn python from zero basis, and learn what content.
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
import urllib.response
from lxml import etree
import re
class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
passxpath expression
1,

2,
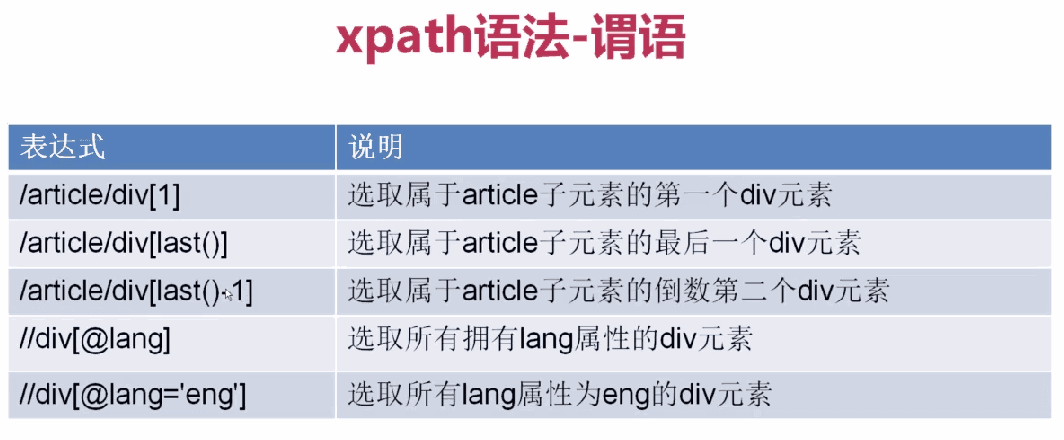
3,
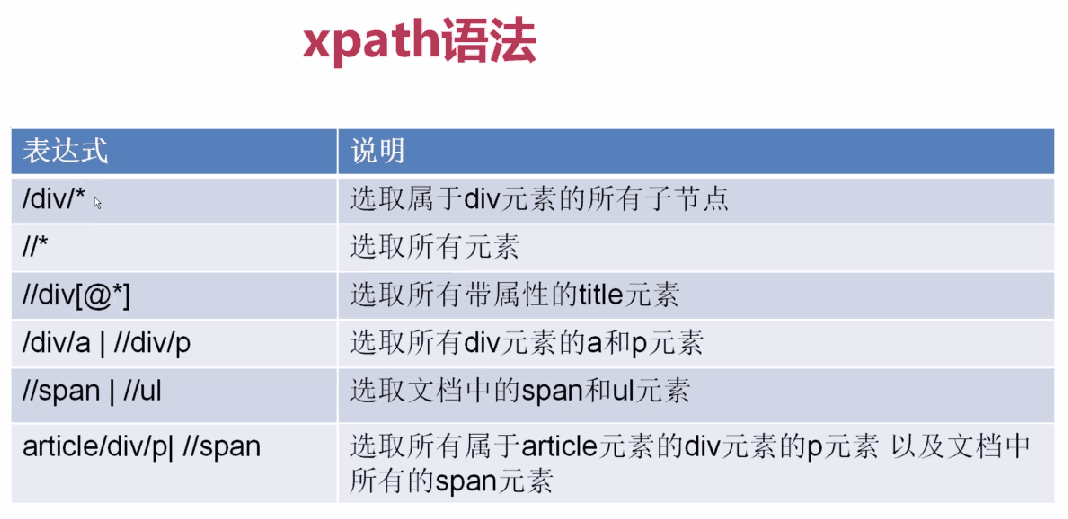
Basic use
allowed_domains sets the crawler start domain name
start_urls Sets the Crawler Start url Address
parse(response) defaults to the crawler callback function, which returns the html information object acquired by the crawler, encapsulating some methods and attributes about htnl information.
Methods and attributes under responsehtml information object
response.url gets the captured rul
response.body retrieves web content
response.body_as_unicode() gets the Unicode code of website content.
The xpath() method filters nodes with xpath expressions
extract() method, which retrieves filtered data and returns a list
If you are still confused in the world of programming, you can join our Python Learning button qun: 784758214 to see how our predecessors learned. Exchange of experience. From basic Python script to web development, crawler, django, data mining, zero-base to actual project data are sorted out. To every little friend of Python! Share some learning methods and small details that need attention. Click to join us. python learner gathering place
# -*- coding: utf-8 -*-
import scrapy
class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
leir = response.xpath('//A [@class= "archive-title"]/text ()'. extract ()# Gets the specified title
leir2 = response.xpath('//A [@class= "archive-title"]/@href'. extract ()# Gets the specified url
print(response.url) #Get the captured rul
print(response.body) #Getting Web Content
print(response.body_as_unicode()) #Get website content unicode encoding
for i in leir:
print(i)
for i in leir2:
print(i)