The problems that redis will encounter when building: 1. On the same machine, you need to use unused ports to achieve master-slave replication. When you set up IP from the slave server of the loop network, you also use the loop network. If you implement master-slave replication on different servers, because you use the real IP network segment must be in the same paragraph.
2. Privilege Verification: redis is not password by default. For the sake of database security, you want the external data to be authenticated. So to set the password, you must set the password of the master configuration file and the password of the slave configuration file. The slave server can only verify the password when it connects to the master server. Success, otherwise the master server will refuse to connect to the slave server, and the slave server will keep trying to connect to the master server until the master-slave replication timeout, leading to failure.
3. In the process of master-slave replication, if the host suddenly goes down, what is the status of the slave server? Will there be any data in it?
127.0.0.1:6379> SHUTDOWN not connected> exit
127.0.0.1:6381> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:down master_last_io_seconds_ago:-1
This is the status of the slave server after the downtime of the primary server and the inquiry of the data in it.
127.0.0.1:6381> keys * 1) "v5" 2) "v1" 3) "v6" 4) "v2" 5) "v3"
Now the slave server is silent, the master-slave replication relationship still exists.
The server restarts replication after silently waiting for the master server to be repaired
Next let's restart the main server and enter several key values in it to see if it can be retrieved from the server.
127.0.0.1:6379> set m7 36 OK 127.0.0.1:6379> set m8 54 OK
127.0.0.1:6381> get m7 "36" 127.0.0.1:6381> get m8 "54"
Principle: Although the master server is down, their relationship will remain unchanged. The slave server will wait silently for the master server to be repaired, then go online again and synchronize the latest data in the master server, instead of replacing it when the master server is down.
How to fix a slave server after it goes down: Fix a problem with the slave server and restart the slave server, but now its identity is not slave, but master. You need to re-execute the command to connect the master server from the slave server before it goes down so that it can be slave again (every time it goes down again), unless you are in the slave. Write configuration changes in configuration files to allow redis to read master-slave replicates at startup
127.0.0.1:6382> SHUTDOWN not connected> exit
[root@sanmao ~]# redis-server /usr/local/myredis/redis6382.conf [root@sanmao ~]# redis-cli -p 6382 -a 666666 127.0.0.1:6382> info replication # Replication role:master connected_slaves:0 master_replid:1d29bfcd6a0319609f8f11de391efddac45ba396 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:214376 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
127.0.0.1:6382> SLAVEOF 127.0.0.1 6379 OK 127.0.0.1:6382> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:1
Another point is that master-slave replication also has the function of read-write separation. The master server can write and read, while the slave server can only read the data of the master server and can not input the data.
In this way, the pressure of the primary server will be considerable. In general, how to optimize the slave server to relieve the pressure of the primary server will require redis'second replication mechanism to spread.

One thing to note here is that from the configuration file not only configure the identity authentication password of the master server, but also set up the identity authentication password that you send to the second slave server, because you both serve as the slave server and the master server (which is equivalent to the relay in sprint, stick-by-stick transmission) the password must be and Your superior master server is the same
In the previous example, under 6379, 6381 and 6382 changed 6381 from servers to 6382 master s, thus alleviating the writing pressure of 6379 and making them a reciprocal relationship.
127.0.0.1:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6381,state=online,offset=217078,lag=0 slave1:ip=127.0.0.1,port=6382,state=online,offset=217064,lag=1
127.0.0.1:6382> SLAVEOF 127.0.0.1 6381 OK
127.0.0.1:6381> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:7 master_sync_in_progress:0 slave_repl_offset:217274 slave_priority:100 slave_read_only:1 connected_slaves:1 slave0:ip=127.0.0.1,port=6382,state=online,offset=217274,lag=0
127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6381,state=online,offset=217358,lag=1
This allows one slave server to bear the write pressure of many other servers as the primary server.
The third replication mechanism of redis is anti-guest. It can change the silent state of the first master-slave replication from the slave server to the active state, make the original two slave servers into a master-slave relationship, and continue the master-slave replication, but when the original master server comes back, they are two different relationships. You can only join as slave

The three replication modes of redis are all introduced, but you can't look at them in real time with the change of technology. What can you do if there is a downtime in the middle of the night? Another mode of redis has been developed by the institute, which is an important sentry mode.
Sentinel mode, as its name implies, is an automatic version of anti-guest mode. It automatically monitors the running status of the main server and votes after the downtime of the main server. It selects one of the remaining servers from the main server to continue to execute the program and monitor, and automatically adds it after the original main server is restarted. Add to slave:
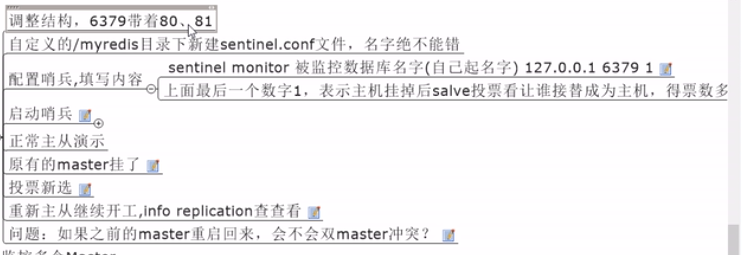
First copy sentinel.conf file in your redis directory to your myredis file, then modify the file name sentinel 6379.conf and configure the file inside. Just copy this line below and delete the comment in your my master (alias) and password save and exit.

Running under redis directory
redis-sentinel /usr/local/myredis/sentinel.conf
[root@sanmao ~]# redis-sentinel /usr/local/myredis/sentinel.conf
4629:X 13 Sep 19:43:25.093 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
4629:X 13 Sep 19:43:25.093 # Redis version=4.0.1, bits=64, commit=00000000, modified=0, pid=4629, just started
4629:X 13 Sep 19:43:25.093 # Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.1 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 4629
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
4629:X 13 Sep 19:43:25.094 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
4629:X 13 Sep 19:43:25.132 # Sentinel ID is 634edb681de8bfafd54f539ff808edb3f4669caa
4629:X 13 Sep 19:43:25.132 # +monitor master mymaster 127.0.0.1 6379 quorum 2
4629:X 13 Sep 19:43:25.132 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
4629:X 13 Sep 19:43:25.169 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
Now the sentry is monitoring your main server. Stop 6379 now and watch the action behind it. Then verify and combine the principles to see how it works.
15798:X 13 Sep 20:19:57.711 # +sdown master mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:57.711 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1 15798:X 13 Sep 20:19:57.711 # +new-epoch 3 15798:X 13 Sep 20:19:57.711 # +try-failover master mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:57.742 # +vote-for-leader e3775f85521398462d76e976c39563b274ba9952 3 15798:X 13 Sep 20:19:57.742 # +elected-leader master mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:57.742 # +failover-state-select-slave master mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:57.827 # +selected-slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:57.827 * +failover-state-send-slaveof-noone slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:57.892 * +failover-state-wait-promotion slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:58.213 # +promoted-slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:58.213 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:58.235 * +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:59.239 * +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:59.239 * +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:59.316 # +failover-end master mymaster 127.0.0.1 6379 15798:X 13 Sep 20:19:59.316 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6382 15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6382 15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382
From the above, we can see that the sentry detected the outage of the main server 6379. The sentry began to failover and selected a new master from the server under the main server, then voted 6382 to be the new master.
127.0.0.1:6382> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6381,state=online,offset=293342,lag=0 master_replid:afd890cd0e2980239ddc3de57f508645d0325040 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:293342 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:251754 repl_backlog_histlen:41589
And 6381 or slave, which is now equivalent to 6382 and 6381 becoming one master-slave relationship, will the original 6379 restart after repair conflict with the current 6382? The answer is no, because the Sentry will automatically change it into slave.
15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6382 15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382 15798:X 13 Sep 20:20:29.338 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382 15798:X 13 Sep 20:35:38.103 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382
127.0.0.1:6379> info replication # Replication role:slave master_host:127.0.0.1 master_port:6382 master_link_status:up master_last_io_seconds_ago:0