PhantomJS Virtual Browser
phantomjs is a headless browser based on JS webkit kernel, that is, a browser without a display interface. With this software, you can get any information loaded by the web site js, that is, information loaded asynchronously by the browser
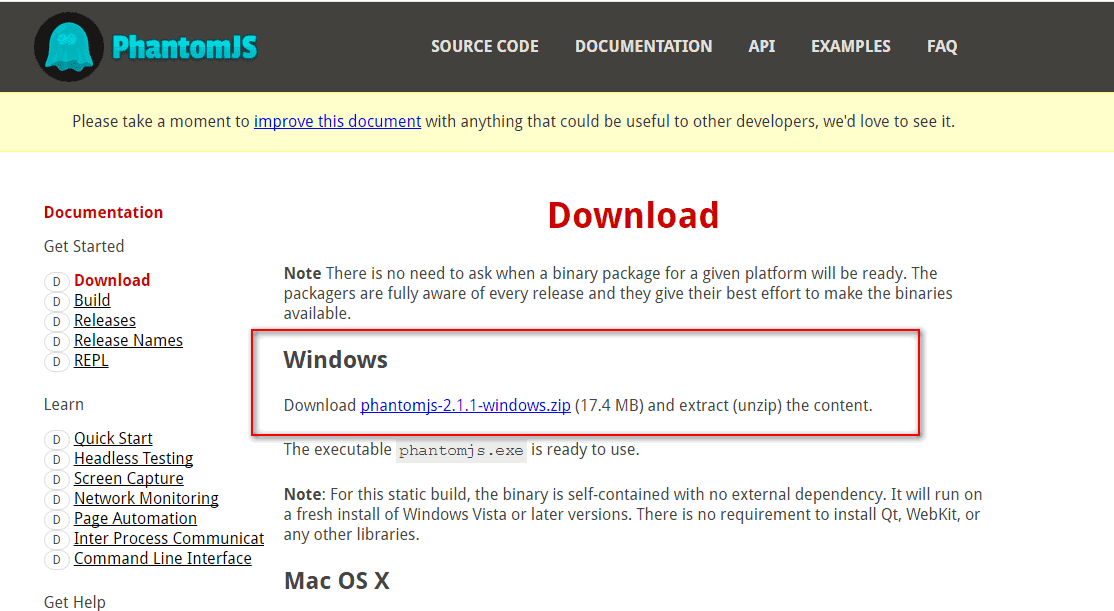
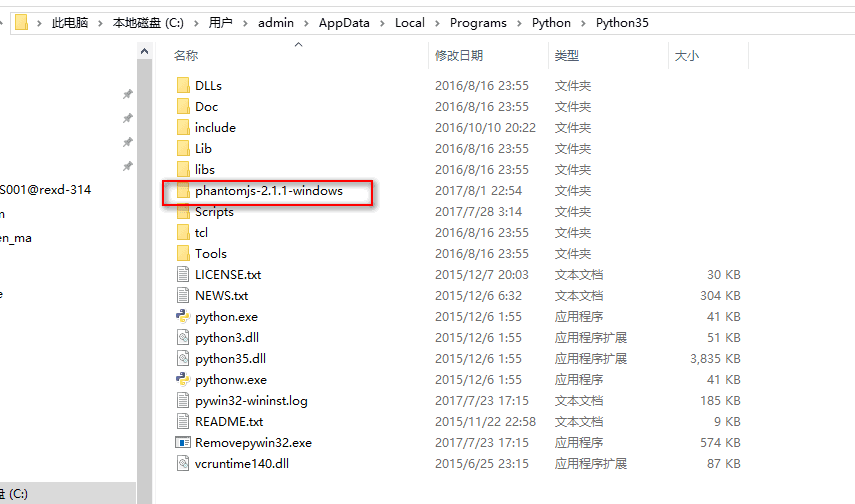
Unzip the Phantom JS file after downloading, unzip the folder, and cut it into the python installation folder
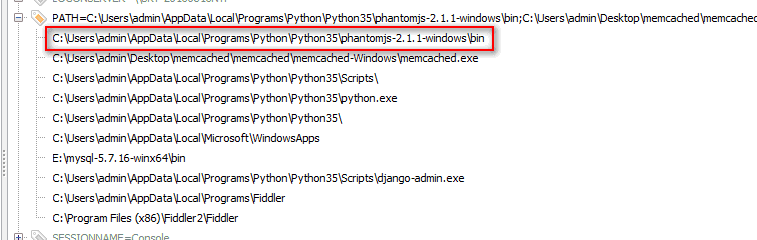
Then add the system environment variable to the bin folder in the PhantomJS folder
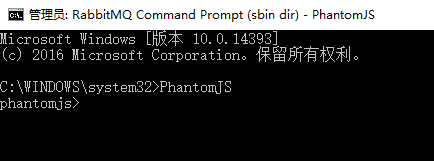
cdm input command: PhantomJS appears with the following information indicating successful installation
selenium module is a module for python to operate PhantomJS software
selenium module PhantomJS software
webdriver.PhantomJS() instantiates PhantomJS browser object
get('url') to visit the website
find_element_by_xpath('xpath expression') Finds the corresponding element through an XPath expression
clear() Clears the contents of the input box
send_keys('Content') writes content to the input box
click() click event
get_screenshot_as_file('Screenshot save path name') Saves a screenshot of a Web page to this directory
page_source Get htnl Source for Web Page
quit() Close PhantomJS browser
I don't know what to add to my learning
python Learning Communication Buttons qun,784758214
//There are good learning video tutorials, development tools and e-books in the group.
//Share with you the current talent needs of the python enterprise and how to learn Python from a zero-based perspective, and what to learn
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #Import selenium module to operate PhantomJS
import os
import time
import re
llqdx = webdriver.PhantomJS() #Instantiate PhantomJS Browser Object
llqdx.get("https://www.baidu.com/") #Visit the web address
# time.sleep(3) #Wait 3 seconds
# llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #Save screenshots of web pages to this directory
#Simulate user action
llqdx.find_element_by_xpath('//*[@id="kw"]').clear() #Find the input box through an xpath expression, and clear() empties the contents of the input box
llqdx.find_element_by_xpath('//*[@id="kw"]').send_keys('hawking network') #Find the input box through the xpath expression, send_keys() writes the content to the input box
llqdx.find_element_by_xpath('//*[@id="su"]').click()#Find the search button through the xpath expression, click() click the event
time.sleep(3) #Wait 3 seconds
llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #Save screenshots of web pages to this directory
neir = llqdx.page_source #Get Web Content
print(neir)
llqdx.quit() #Close Browser
pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #Regularly Match Page Title
print(title)If you are still confused in the world of programming, you can join us in Python learning to deduct qun:784758214 and see how our forefathers learned.Exchange experience.From basic Python scripts to web development, crawlers, django, data mining, and so on, zero-based to project actual data are organized.For every Python buddy!Share some learning methods and small details that need attention, Click to join us python learner cluster
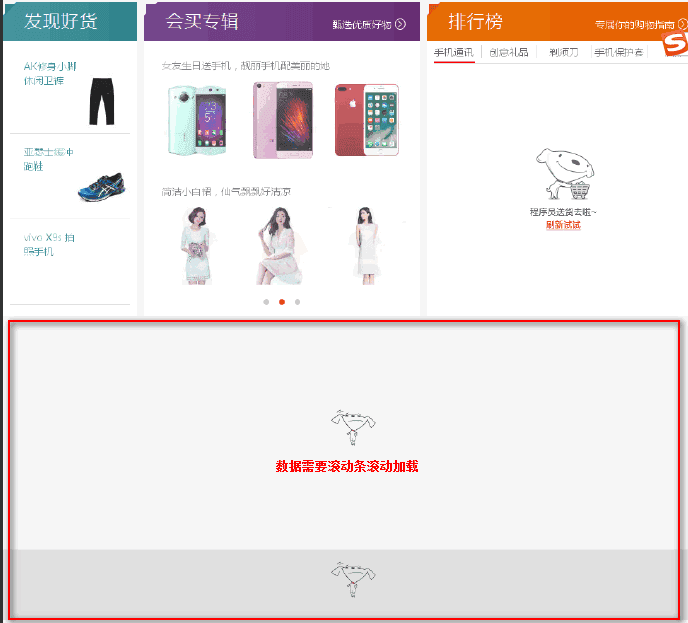
PhantomJS browser masquerade, and scrollbar loading data
Some websites load data dynamically and require scrollbars to scroll through the data
Implementation Code
DesiredCapabilities to disguise browser objects
execute_script() executes js code
current_url Gets the current URL
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #Import selenium module to operate PhantomJS
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities #Import Browser Masquerade Module
import os
import time
import re
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0')
print(dcap)
llqdx = webdriver.PhantomJS(desired_capabilities=dcap) #Instantiate PhantomJS Browser Object
llqdx.get("https://www.jd.com/") #Visit the web address
#Simulate user action
for j in range(20):
js3 = 'window.scrollTo('+str(j*1280)+','+str((j+1)*1280)+')'
llqdx.execute_script(js3) #Execute js language scrollbar
time.sleep(1)
llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #Save screenshots of web pages to this directory
url = llqdx.current_url
print(url)
neir = llqdx.page_source #Get Web Content
print(neir)
llqdx.quit() #Close Browser
pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #Regularly Match Page Title
print(title)