crapy crawls Baidu News, crawls Ajax dynamically generated information, and grabs the news rul address of Baidu News Home Page
There are many websites, when you visit the browser, the information you see can not be found in the html source file. If you scroll the information or scroll bar to the corresponding location before displaying the information, then this kind of information is usually generated by the Ajax dynamic request of js.
We are listed in Baidu News:
1. Analytical website
First, our browser opens Baidu News and finds a news message in the middle of the page.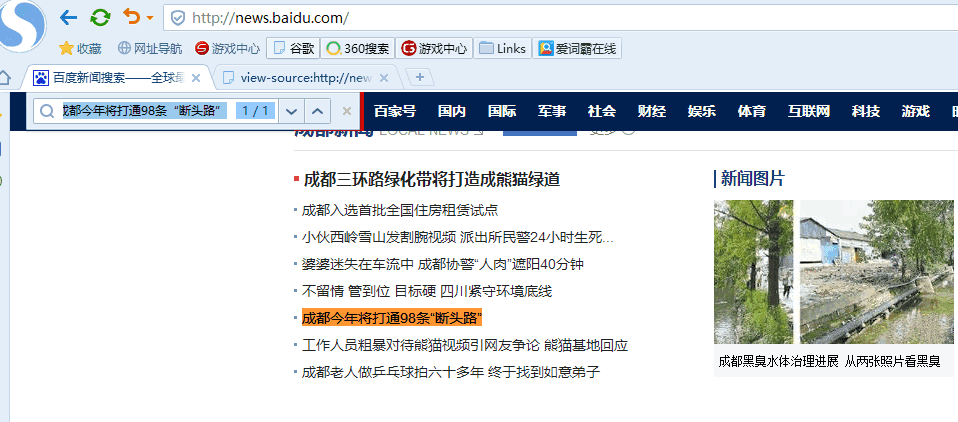
Then look at the source code to see if there is this news in the source code. You can see that there is no such information in the source file. In this case, the crawler can not crawl the information.
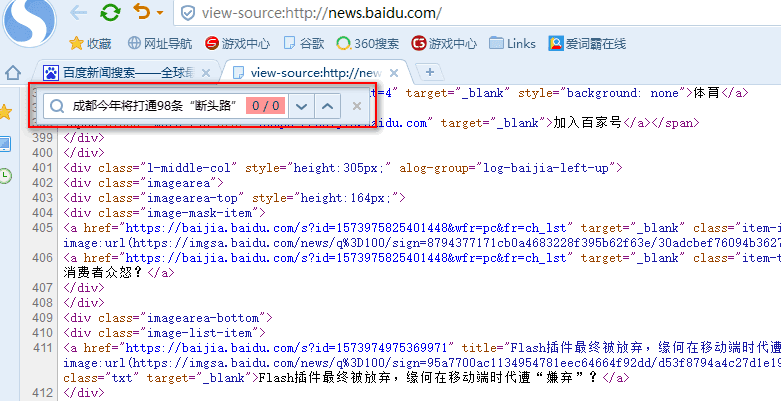
Then we need to grab the package analysis, start the package grabbing software and the package browser, before and after the said software, not to mention, at this time we see that this information is generated dynamically through Ajax JSON data, that is to say, when the html page is loaded, we can not generate it in the source file. Find, of course, the crawler can't find it.
If you are still confused in the world of programming, you can join our Python Learning button qun: 784758214 to see how our predecessors learned. Exchange of experience. From basic Python script to web development, crawler, django, data mining, zero-base to actual project data are sorted out. To every Python buddy! Share some learning methods and small details that need attention. Click to join us. python learner gathering place

Let's first take out the JSON data address and go to the browser to see if all the data we need is in it. At this time, we can see that there are only 17 pieces of information in this request. Obviously, the information we need is not entirely in it, and we have to continue to look at other js packages.
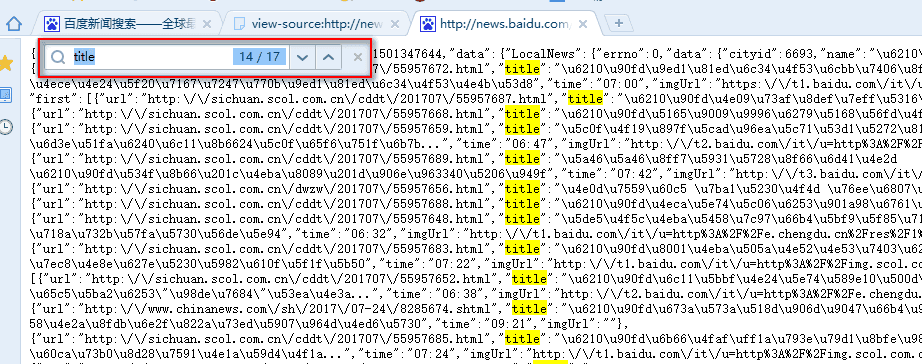
We will scroll down the browser scroll bar to trigger all js requests, and then continue looking for js packages, we will find all js packages and never see the news packages.

That information is not in the js package. We look back at other types of requests. At this time, we see that many get requests respond to the news information we need, which shows that only the JSON data returned by the first Ajax request, and the string data returned by the subsequent Ajax request is html type.

We compare the address of JSON data returned by Ajax request and the address of string data returned by Ajax request in html type to see if we can find some rules.
At this point, we can see that the JSON data address and the html type string data address are a request address.
It's just that the parameters passed in the request are different. It means that no matter what type of data is returned, it's processed at the same request address. It's just that different types of data are returned according to different parameters.
http://News.baidu.com/widget?Id=LocalNews&ajax=json&t=1501348444467 JSON data web site http://News.baidu.com/widget?Id=civilnews&t=1501348728134 HTML type string data address http://News.baidu.com/widget?Id=International News&t=1501348728196 HTML type string data address
We can add html type string data URLs with JSON data URLs parameters. Will that return JSON data types? Give it a try and it worked out.
http://News. baidu. com/widget? Id = civilnews & Ajax = JSON adds html-type string data URLs to JSON data URLs http://News. baidu. com/widget? Id = International News & Ajax = JSON adds html-type string data URLs to JSON data URLs

That's all right. Find all html-type string data URLs, convert them into JSON data URLs according to the above method, and then visit the converted JSON data URLs in a circular way to get all the news URLs.
crapy implementation
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re
import json
from adc.items import AdcItem
from scrapy.selector import Selector
class PachSpider(scrapy.Spider): #To define reptiles, you must inherit scrapy.Spider
name = 'pach' #Set the crawler name
allowed_domains = ['news.baidu.com'] #Crawling Domain Names
start_urls = ['http://news.baidu.com/widget?id=civilnews&ajax=json']
qishiurl = [ #To all page IDS
'InternationalNews',
'FinanceNews',
'EnterNews',
'SportNews',
'AutoNews',
'HouseNews',
'InternetNews',
'InternetPlusNews',
'TechNews',
'EduNews',
'GameNews',
'DiscoveryNews',
'HealthNews',
'LadyNews',
'SocialNews',
'MilitaryNews',
'PicWall'
]
urllieb = []
for i in range(0,len(qishiurl)): #Construct all idURL s
kaishi_url = 'http://news.baidu.com/widget?id=' + qishiurl[i] + '&ajax=json'
urllieb.append(kaishi_url)
# print(urllieb)
def parse(self, response): #Options for all connections
for j in range(0, len(self.urllieb)):
a = 'Processing%s Columns:url The address is:%s' % (j, self.urllieb[j])
yield scrapy.Request(url=self.urllieb[j], callback=self.enxt) #Add crawlers to the url each time you loop
def enxt(self, response):
neir = response.body.decode("utf-8")
pat2 = '"m_url":"(.*?)"'
url = re.compile(pat2, re.S).findall(neir) #Get the URL of the crawled page by regularization
for k in range(0,len(url)):
zf_url = url[k]
url_zf = re.sub("\\\/", "/", zf_url)
pduan = url_zf.find('http://')
if pduan == 0:
print(url_zf) #Output all URLs obtained
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.