1.flume configuration
Create a file that flume listens to instead of a kafka producer to transfer content to consumers. The configuration is as follows
###############to sinnsource,channel give a name###############a kafka_agent.sources = kafka_source kafka_agent.sinks = kafka_sink kafka_agent.channels = kafka_channel ##############To configure source##################### #Docking file kafka_agent.sources.kafka_source.type = exec kafka_agent.sources.kafka_source.command = tail -F /usr/local/flume1.8/test/MultilevelComputing.log kafka_agent.sources.tailsource-1.shell = /bin/bash -c ###############To configure sink###################### #Docking kafka kafka_agent.sinks.kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink #Configure which topic to transfer to kafka_agent.sinks.kafka_sink.kafka.topic = Multilevel #address kafka_agent.sinks.kafka_sink.kafka.bootstrap.servers = htkj101:9092 #Batch size, one message processing at a time kafka_agent.sinks.kafka_sink.kafka.flumeBatchSize = 1 #Successful Input Data Transmission Strategy kafka_agent.sinks.kafka_sink.kafka.producer.acks = -1 kafka_agent.sinks.kafka_sink.kafka.producer.linger.ms = 1 kafka_agent.sinks.kafka_sink.kafka.producer.compression.type = snappy ############################To configure channel################### #Temporary caching of data using files for channel configuration descriptions is more secure kafka_agent.channels.kafka_channel.type = file kafka_agent.channels.kafka_channel.checkpointDir = /home/uplooking/data/flume/checkpoint kafka_agent.channels.kafka_channel.dataDirs = /home/uplooking/data/flume/data ###########################Integrate three components######################### kafka_agent.sources.kafka_source.channels = kafka_channel kafka_agent.sinks.kafka_sink.channel = kafka_channel
2.storm accepts kafka data and calculates it in real time
2.1pom.xml
<dependencies> <!--Introduce storm --> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.0</version> <!--<scope>provided</scope>--> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> </exclusion> </exclusions> </dependency> <!--Introduce kafka-clients--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.0.1</version> </dependency> <!--Introduce kafka--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.0.1</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> </exclusion> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka-client</artifactId> <version>1.1.0</version> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-jdbc</artifactId> <version>1.1.1</version> </dependency> <!--mysql Driver package--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.31</version> </dependency> </dependencies>
2.2 KafkaSpout
Get data from kafka, which is also a topology, and configure it in this class
package com.htkj.multilevelcomputing.Storm; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.StringDeserializer; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.kafka.spout.KafkaSpout; import org.apache.storm.kafka.spout.KafkaSpoutConfig; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; import org.apache.storm.utils.Utils; public class KafkaTopo { public static void main(String[] args) { //Create TopologyBuilder TopologyBuilder topologyBuilder = new TopologyBuilder(); KafkaSpoutConfig.Builder<String, String> kafkaSpoutConfigBuilder; //kafka connection information String bootstrapServers="htkj101:9092,htkj102:9093,htkj103:9094"; //theme String topic = "Multilevel"; /** * Constructing the kafkaSpoutConfigBuilder constructor * * bootstrapServers: Kafka Link address ip:port * StringDeserializer: key Deserializer Deserialization of topic key s * StringDeserializer: value Deserializer Deserialization of topic value * topic: Topic Name */ kafkaSpoutConfigBuilder = new KafkaSpoutConfig.Builder<>( bootstrapServers, StringDeserializer.class, StringDeserializer.class, topic); //Use the kafkaSpoutConfigBuilder constructor to construct kafkaSpoutConfig and configure the corresponding properties KafkaSpoutConfig<String, String> kafkaSpoutConfig = kafkaSpoutConfigBuilder /** * Setting up groupId */ .setProp(ConsumerConfig.GROUP_ID_CONFIG, topic.toLowerCase() + "_storm_group") /** * Set session timeout, which should be between * [group.min.session.timeout.ms, group.max.session.timeout.ms] [6000,300000] * Default value: 10000 */ .setProp(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "100000") /** * Set up maximum pull capacity */ .setProp(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, "1048576") /** * Set the maximum amount of time that controls the client to wait for a request response * Default value: 30000 */ .setProp(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, "300000") /** * Set the expected time between heartbeat and consumer coordinator. * The heartbeat is used to ensure that the consumer's conversation remains active and to promote rebalancing when new consumers join or leave the group. * Default value: 3000 (generally less than one third of session.timeout.ms) */ .setProp(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, "30000") /** * Set offset submission time 15s by default 30s */ .setOffsetCommitPeriodMs(15000) /** * Set the maximum number of pull-outs that are best handled during session timeout */ .setMaxPollRecords(20) /** * Setting pull-out policy */ .setFirstPollOffsetStrategy(KafkaSpoutConfig.FirstPollOffsetStrategy.LATEST) /** * Constructing kafkaSpoutConfig */ .build(); //setSpout receives data from kafka topologyBuilder.setSpout("kafkaSpout",new KafkaSpout(kafkaSpoutConfig)); //setbolt processes data received from kafka topologyBuilder.setBolt("KafkaSpoutBolt", new KafkaBolt()).localOrShuffleGrouping("kafkaSpout"); //setbolt processes the data it receives from KafkaSpoutBolt topologyBuilder.setBolt("MultiBolt",new MultiBolt()).fieldsGrouping("KafkaSpoutBolt",new Fields("orderSn","cateId","goodsAmount","parentId","CEOId")); //setbolt processes the data it receives from MultiBolt topologyBuilder.setBolt("ComputingBolt",new ComputingBolt()).fieldsGrouping("MultiBolt",new Fields("CEOId","parentId","goodsAmount")); Config config = new Config(); /** * Set the communication timeout between supervisor and worker. * Over this time supervisor will restart the worker (in seconds) */ config.put("supervisor.worker.timeout.secs",600000); /** * Set the timeout between store and zookeeper. */ config.put("storm.zookeeper.session.timeout",1200000000); /** * Setting debug mode log output is more complete * Only enabled in local LocalCluster mode */ config.setDebug(true); LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("KafKaTopo", config, topologyBuilder.createTopology()); Utils.sleep(Long.MAX_VALUE); localCluster.shutdown(); } }
2.3KafkaBolt
Here we get the data from kafka and cut it.
package com.htkj.multilevelcomputing.Storm; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; public class KafkaBolt extends BaseBasicBolt { @Override public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { String s = tuple.getString(4); //Cut into a space System.out.println("kafkabolt-----"+s); String[] split = s.split(" "); Integer orderSn=Integer.valueOf(split[0]); Integer cateId=Integer.valueOf(split[1]); Integer goodsAmount=Integer.valueOf(split[2]); Integer parentId=Integer.valueOf(split[3]); Integer CEOId=Integer.valueOf(split[4]); //Submission basicOutputCollector.emit(new Values(orderSn,cateId,goodsAmount,parentId,CEOId)); } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("orderSn","cateId","goodsAmount","parentId","CEOId")); } }
2.4MultiBolt
In this business logic judgment, some commodities can not enter the performance calculation.
package com.htkj.multilevelcomputing.Storm; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; public class MultiBolt extends BaseBasicBolt { @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("CEOId", "parentId", "goodsAmount")); } @Override public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { //get data Integer orderSn = tuple.getIntegerByField("orderSn"); Integer cateId = tuple.getIntegerByField("cateId"); Integer goodsAmount = tuple.getIntegerByField("goodsAmount"); Integer parentId = tuple.getIntegerByField("parentId"); Integer CEOId = tuple.getIntegerByField("CEOId"); System.out.println("orderSn:" + orderSn + "cateId:" + cateId + "goodsAmount:" + goodsAmount + "parentId:" + parentId + "CEOId:" + CEOId); //Articles can not be accessories and facial mask. if (cateId != 9 && cateId != 65) { System.out.println("Success"); basicOutputCollector.emit(new Values(CEOId, parentId, goodsAmount)); } } }
2.5ComputingBolt
Here, the database is connected and the calculated order data is added to the database.
package com.htkj.multilevelcomputing.Storm; import com.google.common.collect.Maps; import org.apache.storm.jdbc.common.Column; import org.apache.storm.jdbc.common.ConnectionProvider; import org.apache.storm.jdbc.common.HikariCPConnectionProvider; import org.apache.storm.jdbc.common.JdbcClient; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Tuple; import java.sql.Types; import java.util.ArrayList; import java.util.List; import java.util.Map; public class ComputingBolt extends BaseRichBolt { private OutputCollector collector; //Creating database connection objects private ConnectionProvider connectionProvider; //Operating object of database private JdbcClient jdbcClient; //The amount obtained by the primary agent from the database private Integer parentAmount; //Total Amount of First-Class Agency private Integer parentAllAmount; //The amount the CEO obtains from the database private Integer CEOAmount; //Total CEO Amount private Integer CEOAllAmount; @Override public void prepare(Map stormConf, TopologyContext topologyContext, OutputCollector collector) { this.collector = collector; //Create a map collection to store connection properties Map map = Maps.newHashMap(); //driver map.put("dataSourceClassName","com.mysql.jdbc.jdbc2.optional.MysqlDataSource"); //url map.put("dataSource.url", "jdbc:mysql:///yazan"); //User name map.put("dataSource.user","root"); //Password map.put("dataSource.password","123456"); //Creating Connection Objects connectionProvider = new HikariCPConnectionProvider(map); //Initialization of database connections connectionProvider.prepare(); //Create database operation object, parameter 2: Query timeout jdbcClient = new JdbcClient(connectionProvider,30); } @Override public void execute(Tuple tuple) { Integer goodsAmount=tuple.getIntegerByField("goodsAmount"); Integer parentId=tuple.getIntegerByField("parentId"); Integer CEOId=tuple.getIntegerByField("CEOId"); System.out.println("goodsAmount-->"+goodsAmount+"parentId-->"+parentId+"CEOId-->"+CEOId); //Conditions for creating collections and storing columns List<Column> parent = new ArrayList<Column>(); //Adding Conditions parent.add(new Column("user_id", parentId, Types.INTEGER)); //Query user_id if parentId List<List<Column>> selectParentId = jdbcClient.select("SELECT user_id ,amount from test WHERE user_id = ?", parent); //If there is no ParentId, execution increases if (selectParentId.size()==0){ System.out.println("no data"); jdbcClient.executeSql("INSERT INTO test (user_id,amount,lid,lid_name) VALUES("+parentId+","+goodsAmount+",10,'General Agent')"); } //If there is a ParentId, find the amount and modify it else { for (List<Column> columns : selectParentId) { for (Column column : columns) { String columnName= column.getColumnName(); if("amount".equalsIgnoreCase(columnName)){ //Get the current amount parentAmount= (Integer) column.getVal(); System.out.println("Current amount"+parentAmount); } } } parentAllAmount=parentAmount+goodsAmount; System.out.println("Total amount"+parentAllAmount); jdbcClient.executeSql("UPDATE test SET amount = "+parentAllAmount+" WHERE user_id = '"+parentId+"'"); } List<Column> CEO = new ArrayList<Column>(); CEO.add(new Column("user_id", CEOId, Types.INTEGER)); List<List<Column>> selectCEOId = jdbcClient.select("SELECT user_id ,amount from test WHERE user_id = ?", CEO); //If there is no CEOId, execution increases if (selectCEOId.size()==0){ System.out.println("no data"); jdbcClient.executeSql("INSERT INTO test (user_id,amount,lid,lid_name) VALUES("+CEOId+","+goodsAmount+",9,'CEO')"); } //If there is a CEOId, find the amount and modify it. else { for (List<Column> columns : selectCEOId) { for (Column column : columns) { String columnName= column.getColumnName(); if("amount".equalsIgnoreCase(columnName)){ //Get the current amount CEOAmount= (Integer) column.getVal(); System.out.println("Current amount"+CEOAmount); } } } CEOAllAmount=CEOAmount+goodsAmount; System.out.println("Total amount"+CEOAllAmount); jdbcClient.executeSql("UPDATE test SET amount = "+CEOAllAmount+" WHERE user_id = '"+CEOId+"'"); } collector.ack(tuple); } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } }
3.shell script
Write a shell script for testing
#!/bin/bash file='/usr/local/flume1.8/test/MultilevelComputing.log ' for((i=0;i<1000000;i++)) do orderSn=$RANDOM cateId=$(($RANDOM%100+1)) goodsAmount=$RANDOM parentId=$(($RANDOM%50+51)) CEOId=$(($RANDOM%50+1)) echo $orderSn $cateId $goodsAmount $parentId $CEOId >> $file; sleep 0.001; done
4. Test results
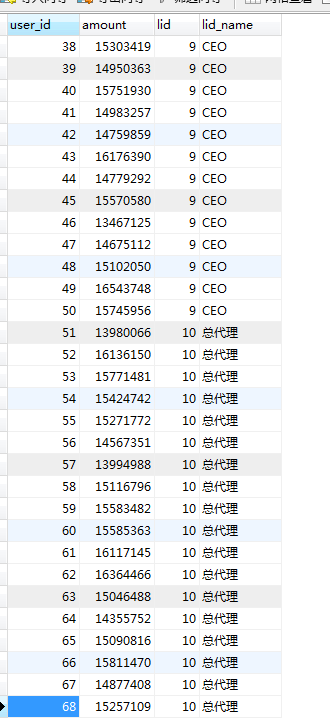
5. Some Notices
- The Problems of Repeated Consumption Computation of kafka+storm
At first I thought it was kafka's problem, and then I checked it out.
ComputingBolt inherits the BaseRichBolt class without ack anchoring
At the end of the code
collector.ack(tuple);
Successful solution.
The point here is that if you inherit BaseBasic Bolt, you don't have to anchor an ack because he has already written it for us.
- Some errors in storm-jdbc
A mistake like this was reported at the time of writing.

This is because the sql statement at that time directly wrote select * from xxx
The storm-jdbc operation queries based on the properties of the columns in the collection we created.
At that time, I only add ed userId to this column, and naturally I couldn't find anything else.