/*
the waiting game:
Although life is so difficult, don't give up; don't compromise; don't lose hope.
*/
With the upgrade of MySQL MGR version and the maturity of technology, MGR has become the preferred solution for high availability of MySQL after MHA has been pulled down from the altar.
The construction of MGR is not very complicated, but there are a series of manual operation steps. In order to simplify the construction and fault diagnosis of MGR, an automated script is completed here to realize the automated construction, automated fault diagnosis and repair of MGR.
Automation of MGR
For the sake of simplicity, the test is carried out in the mode of single machine and multiple instances.
Firstly, three MySQL instances are installed. The port number is 7001,7002,7003, of which 7001 is the write node, and the other two nodes are the read section. 8000 nodes are another test node of the author. Please ignore it.
When the master and slave nodes are specified, the following test demo is used to build the MGR cluster for the mgr_tool.py key
MGR Fault Simulation 1
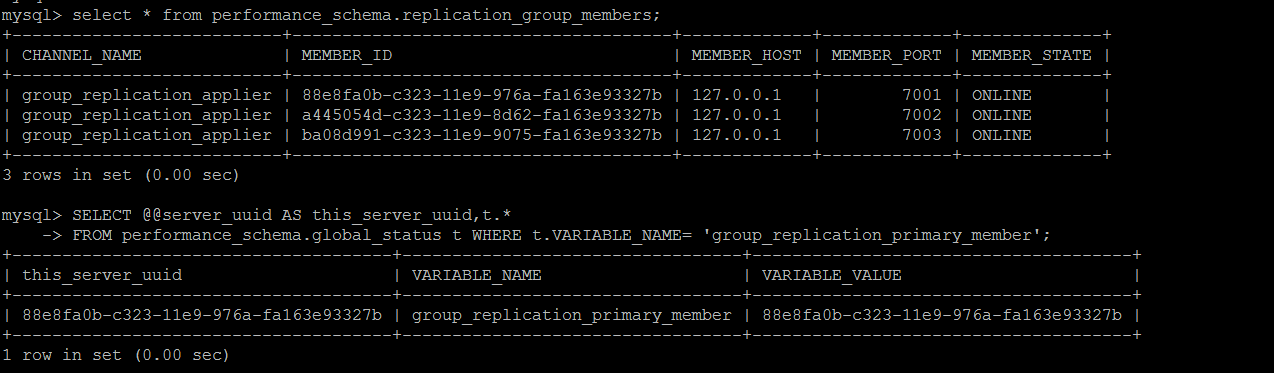
The MGR node fault automatic monitoring and self-healing are realized. The following is the MGR cluster built after completion. At present, the cluster is in a completely normal state.
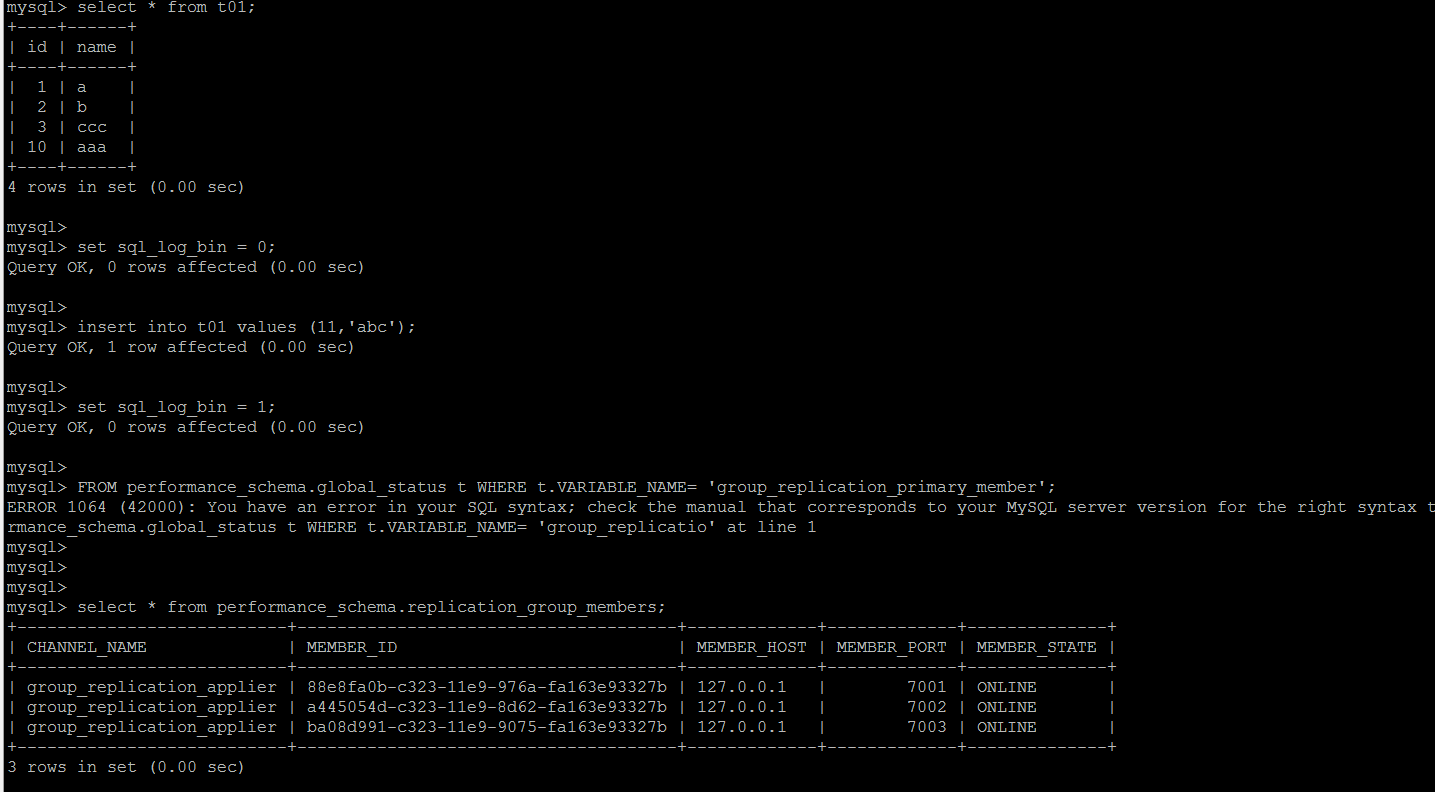
Subjectively causing binlog loss between master and slave nodes
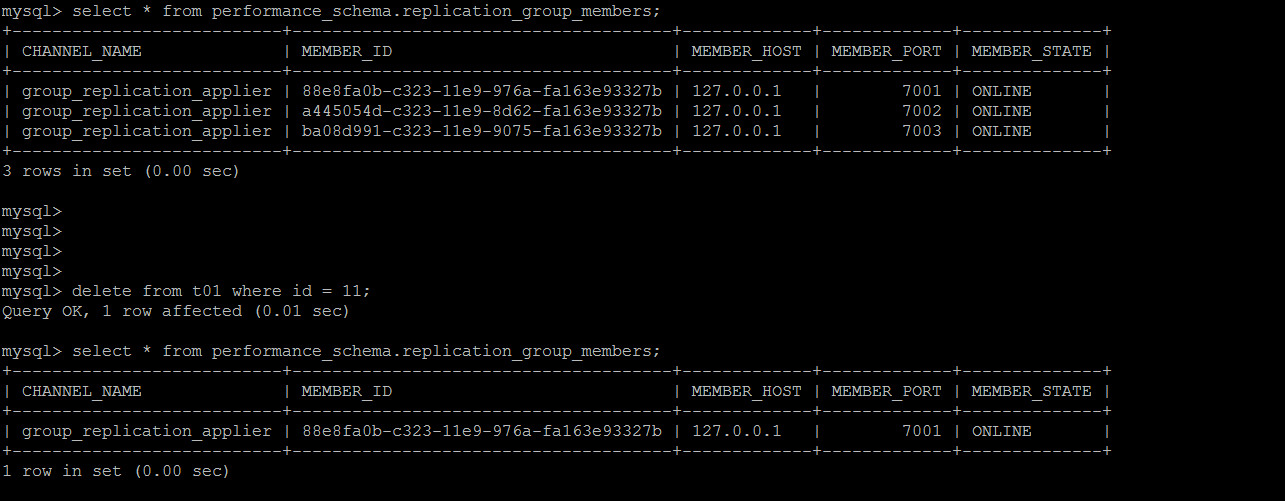
For data operations lost from the primary node, GTID cannot find the corresponding data, and group replication goes off immediately.
Error at non-write node
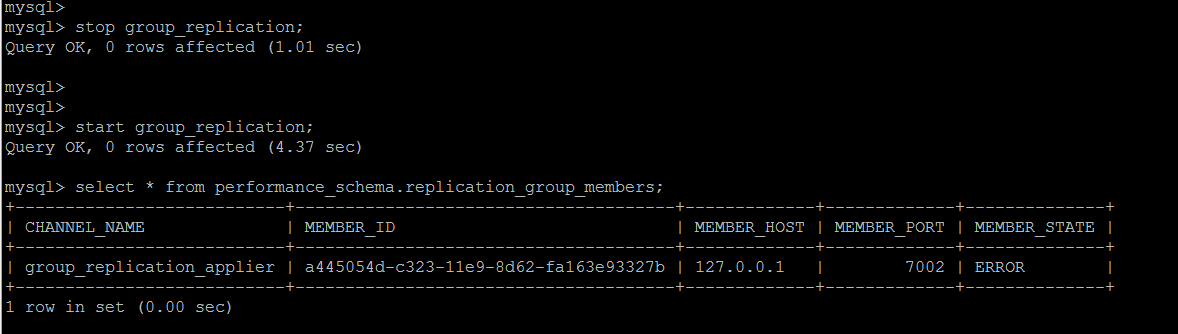
Look at errorlog
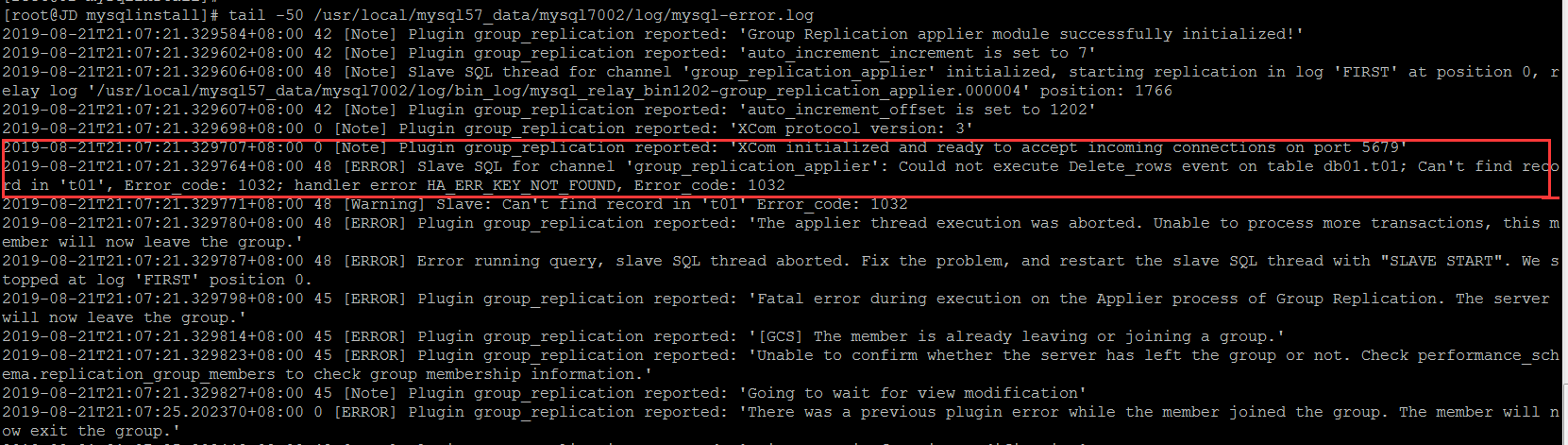
If it's done manually, it's still GTID that skips the wrong routine, GTID information on master

Try to skip the latest thing ID and reconnect to the group. You can connect to the group normally, and the other node is still in error state.
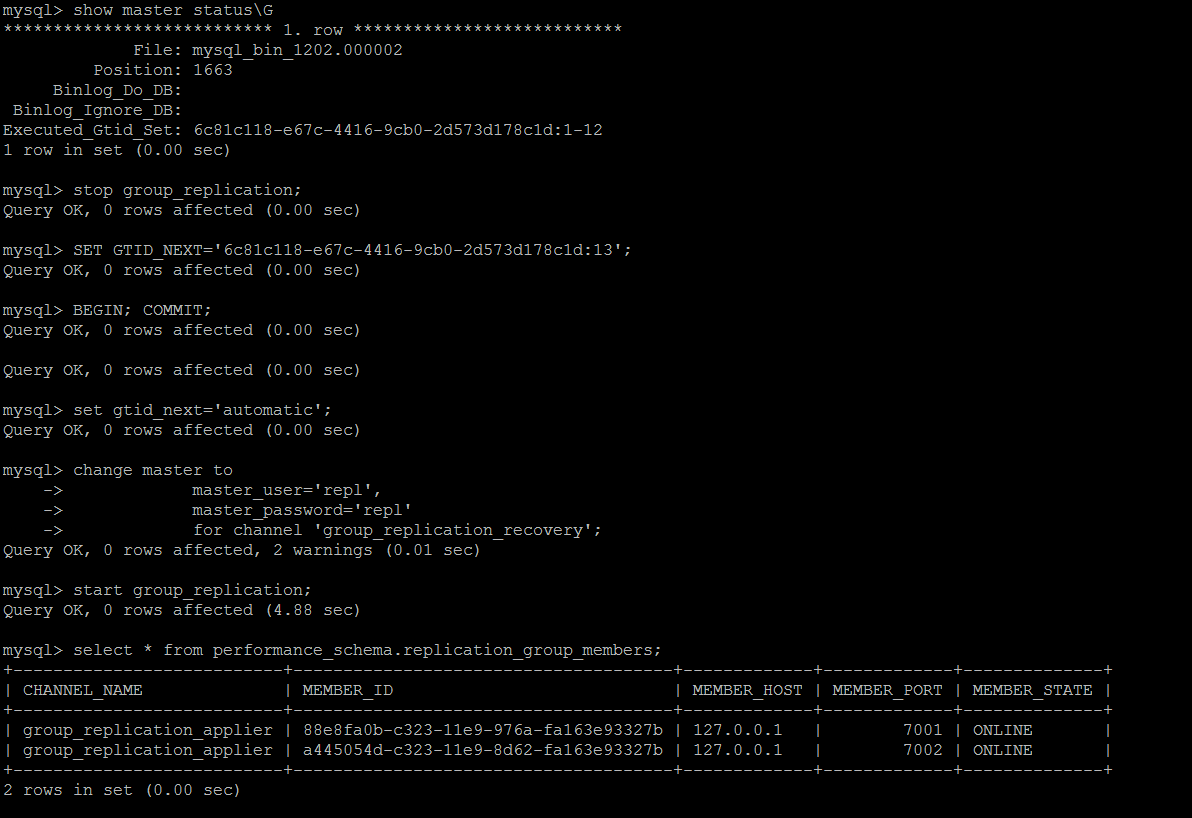
The other node is similar and solved in turn.
MGR Fault Simulation 2
Departure from Group from Node
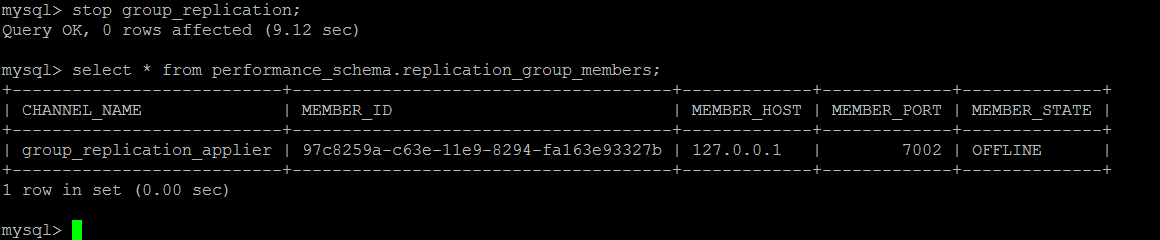
This is a relatively simple case. Just start group_replication again.
Automatic Detection and Repair of MGR Faults
For the two cases mentioned above,
1. If something loses its primary node from the slave node, try to skip GTID from the slave node and start replication again.
2. If the slave node does not lose the master node thing, try to restart group replication from the slave node.
The implementation code is as follows
def auto_fix_mgr_error(conn_master_dict,conn_slave_dict): group_replication_status = get_group_replication_status(conn_slave_dict) if(group_replication_status[0]["MEMBER_STATE"]=="ERROR" or group_replication_status[0]["MEMBER_STATE"] == "OFFLINE"): print(conn_slave_dict["host"]+str(conn_slave_dict["port"])+'------>'+group_replication_status[0]["MEMBER_STATE"]) print("auto fixing......") while 1 > 0: master_gtid_list = get_gtid(conn_master_dict) slave_gtid_list = get_gtid(conn_slave_dict) master_executed_gtid_value = int((master_gtid_list[-1]["Executed_Gtid_Set"]).split("-")[-1]) slave_executed_gtid_value = int(slave_gtid_list[-1]["Executed_Gtid_Set"].split("-")[-1]) slave_executed_gtid_prefix = slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[0] slave_executed_skiped_gtid = slave_executed_gtid_value + 1 if (master_executed_gtid_value > slave_executed_gtid_value): print("skip gtid and restart group replication,skiped gtid is " + slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[-1].split("-")[0] + ":"+str(slave_executed_skiped_gtid)) slave_executed_skiped_gtid = slave_executed_gtid_prefix+":"+str(slave_executed_skiped_gtid) skip_gtid_on_slave(conn_slave_dict,slave_executed_skiped_gtid) time.sleep(10) start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break else: start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break elif (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("mgr cluster is normal,nothing to do") check_replication_group_members(conn_slave_dict)
Automated Repair of GTID Inconsistence for Fault Type 1
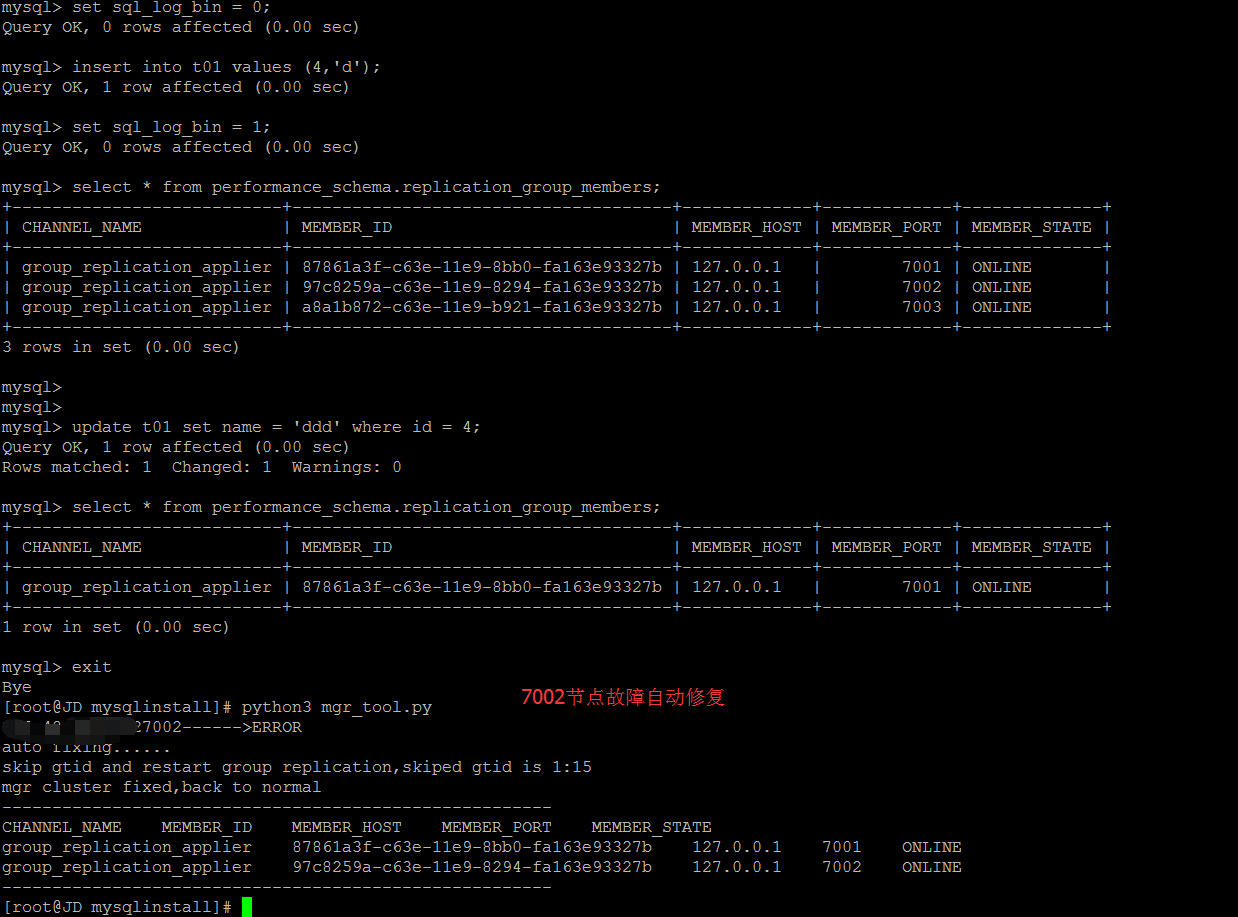
Automated Repair of Fault Type 2 Slave Node offline
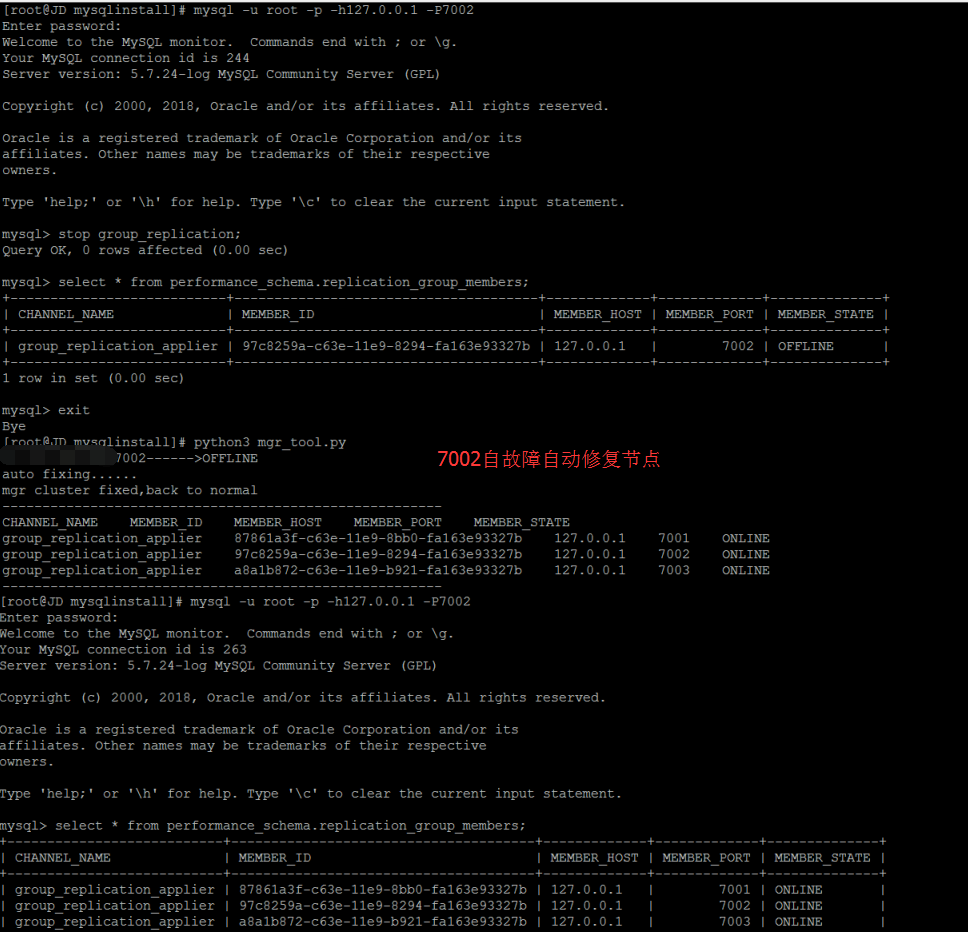
Complete implementation code
This process requires that MySQL instances must satisfy the basic requirements of MGR. If the environment itself cannot satisfy MGR, nothing can be talked about. Therefore, we should be very clear about the basic requirements of MGR environment.
The completed implementation code is as follows. It took one afternoon to write. At present, there are the following shortcomings.
1. When creating a replicate user, no specific slave machine was specified. Currently, the direct specified%: create user repl @'%'identified by repl
2. For the repair of slave, at present, it can not be repaired as a whole, only one repair can be done one by one. In fact, it is a process of judging slave by a circular machine.
3. At present, reset master (master and slave, mainly cleaning up the possible residual GTID) will be used before building, so it is only suitable for the new environment.
4. Currently, only offline and gtid conflict type repair is supported, but other MGR error type repair is not supported.
5. The development environment is single-machine and multi-instance mode testing, which is not fully tested in multi-machine and single-instance mode.
All these will be gradually improved and strengthened.
# -*- coding: utf-8 -*- import pymysql import logging import time import decimal def execute_query(conn_dict,sql): conn = pymysql.connect(host=conn_dict['host'], port=conn_dict['port'], user=conn_dict['user'], passwd=conn_dict['password'], db=conn_dict['db']) cursor = conn.cursor(pymysql.cursors.DictCursor) cursor.execute(sql) list = cursor.fetchall() cursor.close() conn.close() return list def execute_noquery(conn_dict,sql): conn = pymysql.connect(host=conn_dict['host'], port=conn_dict['port'], user=conn_dict['user'], passwd=conn_dict['password'], db=conn_dict['db']) cursor = conn.cursor() cursor.execute(sql) conn.commit() cursor.close() conn.close() return list def get_gtid(conn_dict): sql = "show master status;" list = execute_query(conn_dict,sql) return list def skip_gtid_on_slave(conn_dict,gtid): sql_1 = 'stop group_replication;' sql_2 = '''set gtid_next='{0}';'''.format(gtid) sql_3 = 'begin;' sql_4 = 'commit;' sql_5 = '''set gtid_next='automatic';''' try: execute_noquery(conn_dict, sql_1) execute_noquery(conn_dict, sql_2) execute_noquery(conn_dict, sql_3) execute_noquery(conn_dict, sql_4) execute_noquery(conn_dict, sql_5) except: raise def get_group_replication_status(conn_dict): sql = '''select MEMBER_STATE from performance_schema.replication_group_members where (MEMBER_HOST = '{0}' or ifnull(MEMBER_HOST,'') = '') AND (MEMBER_PORT={1} or ifnull(MEMBER_PORT,'') ='') ; '''.format(conn_dict["host"], conn_dict["port"]) result = execute_query(conn_dict,sql) if result: return result else: return None def check_replication_group_members(conn_dict): print('-------------------------------------------------------') result = execute_query(conn_dict, " select * from performance_schema.replication_group_members; ") if result: column = result[0].keys() current_row = '' for key in column: current_row += str(key) + " " print(current_row) for row in result: current_row = '' for key in row.values(): current_row += str(key) + " " print(current_row) print('-------------------------------------------------------') def auto_fix_mgr_error(conn_master_dict,conn_slave_dict): group_replication_status = get_group_replication_status(conn_slave_dict) if(group_replication_status[0]["MEMBER_STATE"]=="ERROR" or group_replication_status[0]["MEMBER_STATE"] == "OFFLINE"): print(conn_slave_dict["host"]+str(conn_slave_dict["port"])+'------>'+group_replication_status[0]["MEMBER_STATE"]) print("auto fixing......") while 1 > 0: master_gtid_list = get_gtid(conn_master_dict) slave_gtid_list = get_gtid(conn_slave_dict) master_executed_gtid_value = int((master_gtid_list[-1]["Executed_Gtid_Set"]).split("-")[-1]) slave_executed_gtid_value = int(slave_gtid_list[-1]["Executed_Gtid_Set"].split("-")[-1]) slave_executed_gtid_prefix = slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[0] slave_executed_skiped_gtid = slave_executed_gtid_value + 1 if (master_executed_gtid_value > slave_executed_gtid_value): print("skip gtid and restart group replication,skiped gtid is " + slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[-1].split("-")[0] + ":"+str(slave_executed_skiped_gtid)) slave_executed_skiped_gtid = slave_executed_gtid_prefix+":"+str(slave_executed_skiped_gtid) skip_gtid_on_slave(conn_slave_dict,slave_executed_skiped_gtid) time.sleep(10) start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break else: start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break elif (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("mgr cluster is normal,nothing to do") check_replication_group_members(conn_slave_dict) ''' reset master ''' def reset_master(conn_dict): try: execute_noquery(conn_dict, "reset master;") except: raise def install_group_replication_plugin(conn_dict): get_plugin_sql = "SELECT name,dl FROM mysql.plugin WHERE name = 'group_replication';" install_plugin_sql = '''install plugin group_replication soname 'group_replication.so'; ''' try: result = execute_query(conn_dict, get_plugin_sql) if not result: execute_noquery(conn_dict, install_plugin_sql) except: raise def create_mgr_repl_user(conn_master_dict,user,password): try: reset_master(conn_master_dict) sql_exists_user = '''select user from mysql.user where user = '{0}'; '''.format(user) user_list = execute_query(conn_master_dict,sql_exists_user) if not user_list: create_user_sql = '''create user {0}@'%' identified by '{1}'; '''.format(user,password) grant_privilege_sql = '''grant replication slave on *.* to {0}@'%';'''.format(user) execute_noquery(conn_master_dict,create_user_sql) execute_noquery(conn_master_dict, grant_privilege_sql) execute_noquery(conn_master_dict, "flush privileges;") except: raise def set_super_read_only_off(conn_dict): super_read_only_off = '''set global super_read_only = 0;''' execute_noquery(conn_dict, super_read_only_off) def open_group_replication_bootstrap_group(conn_dict): sql = '''select variable_name,variable_value from performance_schema.global_variables where variable_name = 'group_replication_bootstrap_group';''' result = execute_query(conn_dict, sql) open_bootstrap_group_sql = '''set @@global.group_replication_bootstrap_group=on;''' if result and result[0]['variable_value']=="OFF": execute_noquery(conn_dict, open_bootstrap_group_sql) def close_group_replication_bootstrap_group(conn_dict): sql = '''select variable_name,variable_value from performance_schema.global_variables where variable_name = 'group_replication_bootstrap_group';''' result = execute_query(conn_dict, sql) close_bootstrap_group_sql = '''set @@global.group_replication_bootstrap_group=off;''' if result and result[0]['variable_value'] == "ON": execute_noquery(conn_dict, close_bootstrap_group_sql) def start_group_replication(conn_dict): start_group_replication = '''start group_replication;''' group_replication_status = get_group_replication_status(conn_dict) if not (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): execute_noquery(conn_dict, start_group_replication) def connect_to_group(conn_dict,repl_user,repl_password): connect_to_group_sql = '''change master to master_user='{0}', master_password='{1}' for channel 'group_replication_recovery'; '''.format(repl_user,repl_password) try: execute_noquery(conn_dict, connect_to_group_sql) except: raise def start_mgr_on_master(conn_master_dict,repl_user,repl_password): try: set_super_read_only_off(conn_master_dict) reset_master(conn_master_dict) create_mgr_repl_user(conn_master_dict,repl_user,repl_password) connect_to_group(conn_master_dict,repl_user,repl_password) open_group_replication_bootstrap_group(conn_master_dict) start_group_replication(conn_master_dict) close_group_replication_bootstrap_group(conn_master_dict) group_replication_status = get_group_replication_status(conn_master_dict) if (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("master added in mgr and run successfully") return True except: raise print("############start master mgr error################") exit(1) def start_mgr_on_slave(conn_slave_dict,repl_user,repl_password): try: set_super_read_only_off(conn_slave_dict) reset_master(conn_slave_dict) connect_to_group(conn_slave_dict,repl_user,repl_password) start_group_replication(conn_slave_dict) # wait for 10 time.sleep(10) # then check mgr status group_replication_status = get_group_replication_status(conn_slave_dict) if (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("slave added in mgr and run successfully") if (group_replication_status[0]['MEMBER_STATE'] == 'RECOVERING'): print("slave is recovering") except: print("############start slave mgr error################") exit(1) def auto_mgr(conn_master,conn_slave_1,conn_slave_2,repl_user,repl_password): install_group_replication_plugin(conn_master) master_replication_status = get_group_replication_status(conn_master) if not (master_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): start_mgr_on_master(conn_master,repl_user,repl_password) slave1_replication_status = get_group_replication_status(conn_slave_1) if not (slave1_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): install_group_replication_plugin(conn_slave_1) start_mgr_on_slave(conn_slave_1, repl_user, repl_user) slave2_replication_status = get_group_replication_status(conn_slave_2) if not (slave2_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): install_group_replication_plugin(conn_slave_2) start_mgr_on_slave(conn_slave_2, repl_user, repl_user) check_replication_group_members(conn_master) if __name__ == '__main__': conn_master = {'host': '127.0.0.1', 'port': 7001, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'} conn_slave_1 = {'host': '127.0.0.1', 'port': 7002, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'} conn_slave_2 = {'host': '127.0.0.1', 'port': 7003, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'} repl_user = "repl" repl_password = "repl" #auto_mgr(conn_master,conn_slave_1,conn_slave_2,repl_user,repl_password) auto_fix_mgr_error(conn_master,conn_slave_1) check_replication_group_members(conn_master)