Recently, with the deepening of the experiment, the scale of the experiment is getting larger and larger, and the calculation of single GPU is not enough. At the same time, I often need to test different models. It will be very troublesome to build a framework every time. So I separated the framework from the model this time. In the future, only a little modification is needed to run it immediately.
principle
Tensorflow multi-GPU operation has two modes: asynchronous mode and synchronous mode. In asynchronous mode, different GPUs run back propagation algorithms and update data independently. This mode is the fastest in theory, but may not achieve better training results. In synchronous mode, after each GPU completes backpropagation, the CPU calculates the average value of all GPU gradients, and finally updates all parameters together. In this process, the GPU waits for parameter updates, which reduces the efficiency. However, the GPU on the same server is generally the same model, the same calculation, waste of time is acceptable, so choose synchronous training mode.
The synchronous computing model is as follows: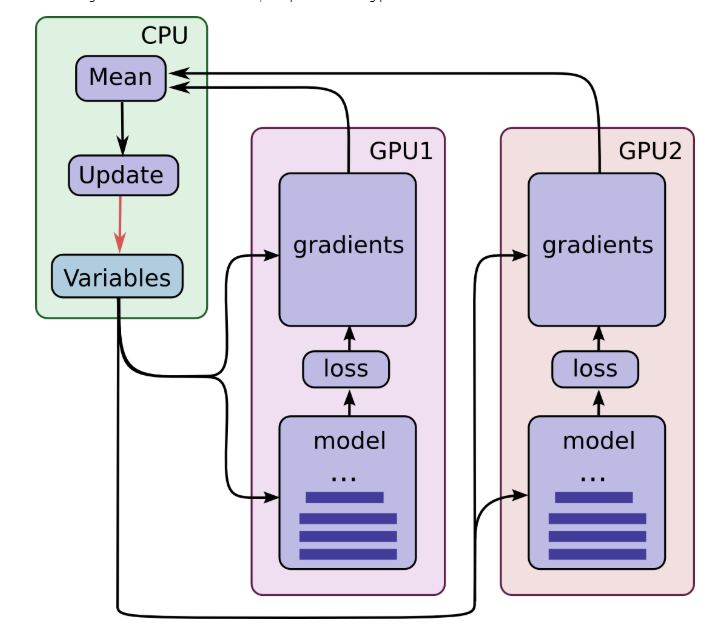
The catalogue of project files is as follows
-----NNN-CMQ
|
–checkpoint
|
–logs
|
–Test
|
–Train
|
–generateH5.py
|
–NNN.py
|
–Train.py
|
–modelFrame.py
Backbone: main.py
Inside main.py, there are various Super-parameters and various logos.
Super Participation Identification:
parser = argparse.ArgumentParser() parser.add_argument("--imgsize",default=30,type=int) parser.add_argument("--output_channels",default=1,type=int) parser.add_argument("--scale",default=3,type=int) parser.add_argument("--resBlocks",default=2,type=int) parser.add_argument("--featuresize",default=4,type=int)#32 parser.add_argument("--batchsize",default=32,type=int) parser.add_argument("--savedir",default='checkpoint') parser.add_argument("--saveID",default='2',type=int)#1 parser.add_argument("--model_name",default='WSDR_A') parser.add_argument("--logs",default='logs') parser.add_argument("--reGenerateH5",default=False,type=bool) parser.add_argument("--epoch",default=50,type=int) parser.add_argument("--isTrain",default=True,type=bool) os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" gpus = os.getenv('CUDA_VISIBLE_DEVICES') parser.add_argument("--gpus",default=gpus) args = parser.parse_args()
Next, organize data production classes, multi-GPU frameworks and tests:
#session configuration parameters config = tf.ConfigProto(allow_soft_placement=True) with tf.Session(config=config) as sess: #When I make data sets, I use H5. In the future, I will change to dataset, which will reduce the amount of code. if(args.reGenerateH5): data(args) #Building multi-gpu framework network = modelFrame(args,sess) if (args.isTrain == True): network.trainMultiGpus()#train else: network.resume(args.savedir) network.test()#test
Data Set Production: Generate H5.py
The py file here is a class for making H5 data:
class data(object): def __init__(self, args): is_train = True imgsize = 90 imgchannel = 1 scale = 3 savepath="checkpoint" data_dir = "../SRimage/Train" if is_train: ``` //Here is the production of training data. ``` dir = os.path.join(data_dir,"*.tif") data = glob.glob(dir) random.shuffle(data) sub_input_sequence = [] sub_label_sequence = [] ``` //Intermediate process... ``` sub_input_sequence = np.asarray(sub_input_sequence) sub_label_sequence = np.asarray(sub_label_sequence) #Scrambling permutation = np.random.permutation(len(sub_input_sequence)) shuffled_input = sub_input_sequence[permutation, :, :, :] shuffled_label = sub_label_sequence[permutation, :, :, :] with h5py.File(savepath+"/data_train.h5", 'w') as hf: hf.create_dataset('train_input', data=shuffled_input) hf.create_dataset('train_label', data=shuffled_label) else: ``` //Write test data here... ```
Main Framework: modelFrame.py
Find a py file is the model class, which contains multiple gpus builds:
class modelFrame(object): def __init__(self,args,sess): #There are various kinds of super parameters. self.args = args self.sess = sess self.img_size = args.imgsize self.output_channels = args.output_channels self.scale = args.scale self.num_layers = args.resBlocks self.feature_size = args.featuresize self.batch_size = args.batchsize self.savedir = args.savedir self.saveID = args.saveID self.model_name = args.model_name self.logs = args.logs self.epoch = args.epoch self.isTrain = args.isTrain self.gpus = args.gpus.split(',') # Start building a multi-GPU framework, pay attention to the above image understanding #Define some operations in the cpu first with tf.device("/cpu:0"): global_step = tf.train.get_or_create_global_step() tower_grads = [] #Define input self.X = tf.placeholder(tf.float32, [None, self.img_size, self.img_size, self.output_channels], name="images") self.Y = tf.placeholder(tf.float32, [None, 21, 21, self.output_channels], name="labels") opt = tf.train.AdamOptimizer(0.001) count = 0 with tf.variable_scope(tf.get_variable_scope()): for i in self.gpus: with tf.device("/gpu:%c" % i): # Considering that sometimes the gpu will choose 2,3 or 1,3, this is not incremental. with tf.name_scope("tower_%c" % i): #No tower corresponds to a graphics card. Here we set up its batch. _x = self.X[count * self.batch_size:(count + 1) * self.batch_size] _y = self.Y[count * self.batch_size:(count + 1) * self.batch_size] #Call model classes to build networks self.out = SRCNN(self.args, _x).getNet() # Calculating parameters print("total-", self.get_total_params()) self.loss = tf.reduce_mean(tf.squared_difference(_y, self.out)) tf.summary.scalar("loss", self.loss) grads = opt.compute_gradients(self.loss) opt.apply_gradients(grads) tower_grads.append(grads) ``` //Note that here, you must calculate the gradient, or you will report errors, specifically related to the adm optimizer, you can test it yourself. ``` tf.get_variable_scope().reuse_variables() PSNR = tf.image.psnr(_y, self.out, max_val=1.0) PSNR = tf.reduce_sum(PSNR) PSNR = tf.div(PSNR, self.batch_size) tf.summary.scalar('PSNR', PSNR) if count == 0: self.testNet = self.out count =count+1 grads = self.average_gradients(tower_grads)#Calculate the average gradient on all GPUs self.train_op = opt.apply_gradients(grads) self.merged = tf.summary.merge_all() logName = "%s_%s_%s_%s" % (self.model_name, self.num_layers, self.feature_size, self.saveID) self.logs_dir = os.path.join(self.logs, logName) if not os.path.exists(self.logs_dir): os.makedirs(self.logs_dir) self.train_writer = tf.summary.FileWriter(self.logs_dir, self.sess.graph) self.saver = tf.train.Saver()
Preservation and Restoration Model
def save(self, checkpoint_dir, step): model_dir = "%s_%s_%s_%s" % (self.model_name, self.num_layers, self.feature_size, self.saveID) checkpoint_dir = os.path.join(checkpoint_dir, model_dir) if not os.path.exists(checkpoint_dir): os.makedirs(checkpoint_dir) self.saver.save(self.sess, os.path.join(checkpoint_dir, self.model_name), global_step=step) def resume(self, checkpoint_dir): print(" [*] Reading checkpoints...") model_dir = "%s_%s_%s_%s" % (self.model_name, self.num_layers, self.feature_size, self.saveID) checkpoint_dir = os.path.join(checkpoint_dir, model_dir) ckpt = tf.train.get_checkpoint_state(checkpoint_dir) if ckpt and ckpt.model_checkpoint_path: ckpt_name = os.path.basename(ckpt.model_checkpoint_path) self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name)) print("Reading sucess!") return True else: return False
Calculating average gradient
def average_gradients(self, tower_grads): average_grads = [] for grad_and_vars in zip(*tower_grads): grads = [] for g, _ in grad_and_vars: expend_g = tf.expand_dims(g, 0) grads.append(expend_g) grad = tf.concat(grads, 0) grad = tf.reduce_mean(grad, 0) v = grad_and_vars[0][1] grad_and_var = (grad, v) average_grads.append(grad_and_var) return average_grads
Get all the parameters
def get_total_params(self): num_params = 0 for variable in tf.trainable_variables(): shape = variable.get_shape() num_params += reduce(mul, [dim.value for dim in shape], 1)#Here we import two packages return num_params
Prediction of model
def predict(self): print("Predicting...") def test(self): print("test!")
Model: NNN.py
The model here is arbitrary, as long as the getNet() function is implemented and the output of the network is returned, it can be independent of the framework. After that, it is very simple to build a new model.
class SRCNN(object): def __init__(self,args,x):#Initialization functions require input to the network self.image_size = 33 self.label_size = 21 self.batch_size = 128 self.weights = { 'w1': tf.Variable(tf.random_normal([9, 9, 1, 64], stddev=1e-3), name='w1'), 'w2': tf.Variable(tf.random_normal([1, 1, 64, 32], stddev=1e-3), name='w2'), 'w3': tf.Variable(tf.random_normal([5, 5, 32, 1], stddev=1e-3), name='w3') } self.biases = { 'b1': tf.Variable(tf.zeros([64]), name='b1'), 'b2': tf.Variable(tf.zeros([32]), name='b2'), 'b3': tf.Variable(tf.zeros([1]), name='b3') } conv1 = tf.nn.relu( tf.nn.conv2d(x, self.weights['w1'], strides=[1, 1, 1, 1], padding='VALID') + self.biases['b1']) conv2 = tf.nn.relu( tf.nn.conv2d(conv1, self.weights['w2'], strides=[1, 1, 1, 1], padding='VALID') + self.biases['b2']) conv3 = tf.nn.conv2d(conv2, self.weights['w3'], strides=[1, 1, 1, 1], padding='VALID') + self.biases['b3'] self.out = conv3 #Return the output of the network def getNet(self): return self.out
All code
All the code has been submitted to github. Please download it if you need it. If it's helpful to you, please send it to a star.
link.