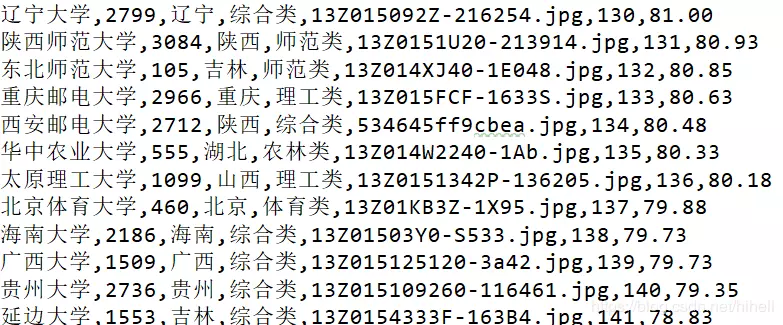
1. College Entrance Examination School College Data - Write in front
Finally, scrapy crawler framework is written, which can be said to be the highest rate of emergence in the python crawler framework, we will focus on its use rules next.
Installation process Baidu itself, you can find more than three installation methods, one can be installed anywhere.
You can refer to the official instructions of https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html for installation.
2. College Entrance Examination Data-Creation of Scapy Project
Generic use of the following commands to create
scrapy startproject mySpider
After completion, the catalog structure of your project is
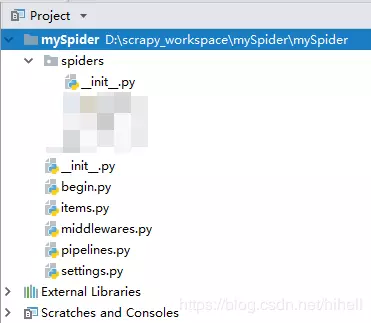
The corresponding meaning of each file is
- Configuration file for scrapy.cfg project
- mySpider / root directory
- The object file of the mySpider / items.py project, which specifies the data format, is used to define the attributes or fields corresponding to the parsed object.
- Pipeline files for mySpider/pipelines.py project, which handles projects extracted by spiders. Typical processes are cleanup, validation, and persistence (such as access to a database)
- Settings file for mySpider/settings.py project
- mySpider / spiders / crawler home directory
- *middlewares.py Spider middleware is a specific hook (specific hook) between the engine and Spider, handling spider input (response) and output (items and requests). It provides a simple mechanism to extend Scrapy by inserting custom code. * This article does not cover it.
College Entrance Examination School College Data Creating Scrapy Reptiles
Go to the mySpider / spiders / directory from the command line and execute the following commands
scrapy genspider College entrance examination " www.gaokaopai.com "
Open the college entrance examination in mySpider / spiders / directory and add the following code by default
import scrapy
class GaoKaoSpider(scrapy.Spider):
name = "GaoKao"
allowed_domains = ["www.gaokaopai.com"]
start_urls = ['http://www.gaokaopai.com/']
def parse(self, response):
pass
The default generated code, a class of all game GaoKaoSpider, which is inherited from scrapy.Spider in English
And three attribute adverbial clauses are implemented by default: one method
Name = "" This is the name of the reptile. It must be unique. Different names need to be defined for different reptiles.
allowed_domains = domain name range, restricting crawlers to crawl pages under the current domain name
start_urls = crawled URL tuples / lists. The crawler starts crawling data from here. The first page crawled is from here. Other URLs will be generated from the results of crawling these initial URLs.
The method of parsing web pages by self (response). When an initial web site is downloaded, it will be invoked. When invoked, the response object returned by each initial URL will be passed as the only parameter. The main function of this method is 1. It is responsible for parsing the returned web page data, response.body 2, and generating the URL request for the next page.
University Data of College Entrance Examination School--The First Case
The data we need to crawl is http://www.gaokaopai.com/rank-index.html.
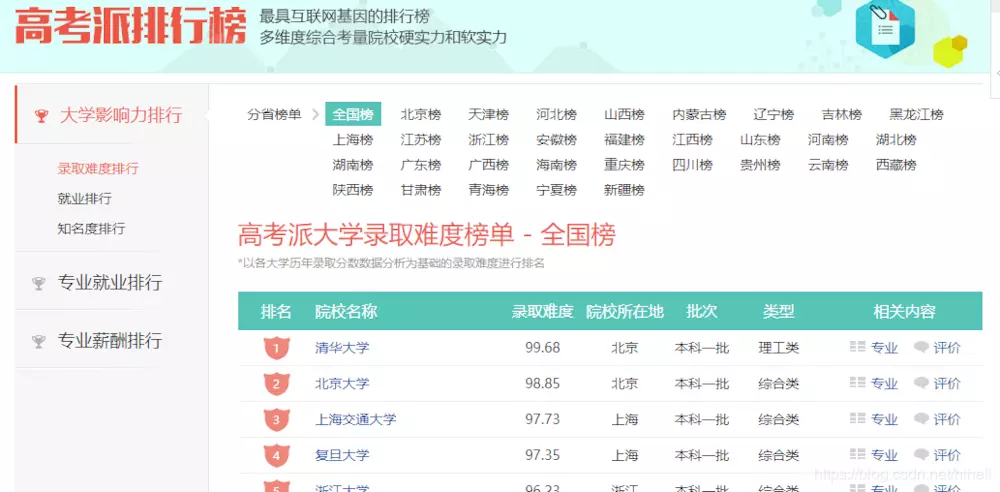
There is a load more at the bottom of the page. Click on the crawl link.
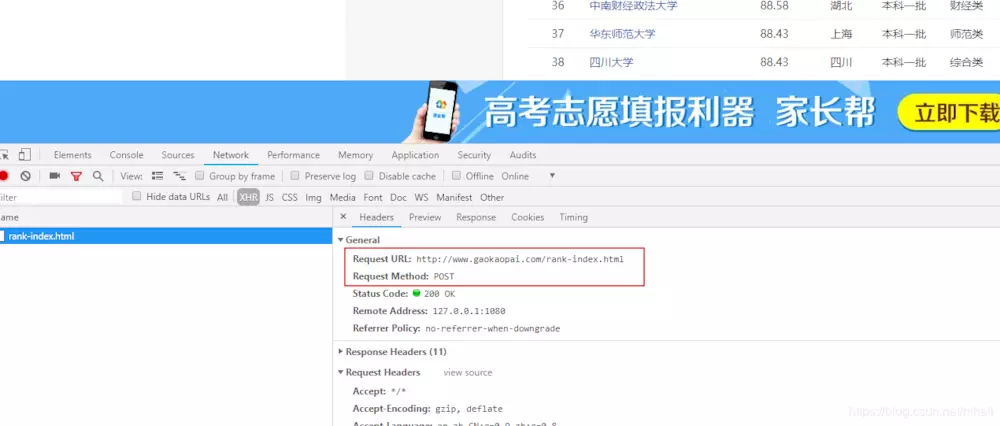
The embarrassing thing happened. It was a POST request. It was intended to implement a GET. This time, the amount of code was a bit too large.

The scrapy mode is a GET request. If we need to modify it to POST, we need to rewrite the start_requests (self) method of the Spider class and not call the url in start_urls anymore. So, let's make some changes to the code. After rewriting the code, notice the following code
request = FormRequest(self.start_url,headers=self.headers,formdata=form_data,callback=self.parse)
FormRequest needs to introduce modules from scrapy import FormRequest
formdata is the address of self.start_url to write the post request.
Used to submit form data
callback calls page parsing parameters
The final yield request indicates that the function is a generator
import scrapy
from scrapy import FormRequest
import json
from items import MyspiderItem
class GaokaoSpider(scrapy.Spider):
name = 'GaoKao'
allowed_domains = ['gaokaopai.com']
start_url = 'http://www.gaokaopai.com/rank-index.html'
def __init__(self):
self.headers = {
"User-Agent":"Find one for yourself UA",
"X-Requested-With":"XMLHttpRequest"
}
# You need to override the start_requests() method
def start_requests(self):
for page in range(0,7):
form_data = {
"otype": "4",
"city":"",
"start":str(25*page),
"amount": "25"
}
request = FormRequest(self.start_url,headers=self.headers,formdata=form_data,callback=self.parse)
yield request
def parse(self, response):
print(response.body)
print(response.url)
print(response.body_as_unicode())
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
In our def parse(self, response): function, output the content of the web page, this place, need to use a knowledge point.
Get the page content response.body response.body_as_unicode()
- response.url gets the grabbed RUL
- response.body retrieves the content byte type of a web page
- response.body_as_unicode() Gets the type of the content string of the Web site
Now we can run the crawler program.
The project creates an begin.py file in the root directory, which writes the following code
from scrapy import cmdline
cmdline.execute(("scrapy crawl GaoKao").split())
Running this file, remember that in other py files in scrapy, running will not show the corresponding results. Every time you test, you need to run begin.py. Of course, you can name it by another name.
If you don't, then you can only use the following operation, which is more troublesome.
cd to the crawler directory to execute the scrapy crawl Gao Kao-nolog command Description: scrapy crawl Gao Kao (Gao Kao denotes the name of the crawler) -- nolog(--nolog denotes no log display)

Running, the data is printed on the console. It's easy to test. You can change the number 7 in the above code to 2. The interested person can see my small text.
pycharm prints a lot of red words on the console during its operation. That's OK. That's not BUG.
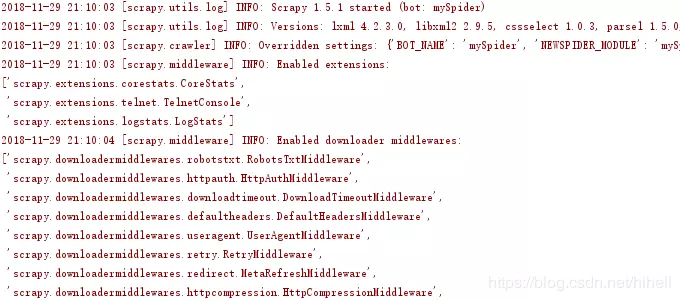
Be sure to find the black word in the middle of the red word. The black word is the data you print out. As follows, if you get such content, you will be more than half successful.
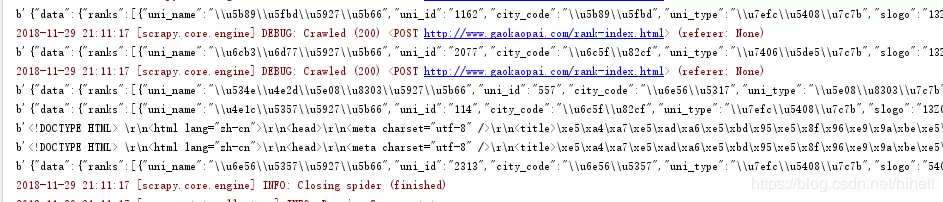
But there is a small pit in this place, that is, you will find that the data returned is inconsistent. I tested this, because the data returned on the first page is not JSON format, but ordinary web pages. Then we need to deal with it pertinently. This is not to be taken care of first, and we need to improve items.py.
import scrapy
class MyspiderItem(scrapy.Item):
# School Name
uni_name = scrapy.Field()
uni_id = scrapy.Field()
city_code = scrapy.Field()
uni_type = scrapy.Field()
slogo = scrapy.Field()
# Admission Difficulty
safehard = scrapy.Field()
# Location of Institutions
rank = scrapy.Field()
Then, in the GaokaoSpider class just now, we continue to improve the analytic function and judge that we can confirm this by response.headers["Content-Type"]. The English HTML format of the page, or JSON format.
if(content_type.find("text/html")>0):
# print(response.body_as_unicode())
trs = response.xpath("//table[@id='results']//tr")[1:]
for item in trs:
school = MyspiderItem()
rank = item.xpath("td[1]/span/text()").extract()[0]
uni_name = item.xpath("td[2]/a/text()").extract()[0]
safehard = item.xpath("td[3]/text()").extract()[0]
city_code = item.xpath("td[4]/text()").extract()[0]
uni_type = item.xpath("td[6]/text()").extract()[0]
school["uni_name"] = uni_name
school["uni_id"] = ""
school["city_code"] = city_code
school["uni_type"] = uni_type
school["slogo"] = ""
school["rank"] = rank
school["safehard"] = safehard
yield school
else:
data = json.loads(response.body_as_unicode())
data = data["data"]["ranks"] # get data
for item in data:
school = MyspiderItem()
school["uni_name"] = item["uni_name"]
school["uni_id"] = item["uni_id"]
school["city_code"] = item["city_code"]
school["uni_type"] = item["uni_type"]
school["slogo"] = item["slogo"]
school["rank"] = item["rank"]
school["safehard"] = item["safehard"]
# Give the acquired data to pipelines, which are defined in settings.py
yield school
Execution mechanism of parse () method
- Use output to return data, not revenue. This parsing is then treated as a generator. scarpy parses the generated data and returns it one by one.
- If the return value is a request, join the crawl queue. If it is an item type, it is handed over to the pipeline and other types report errors.
Here, if you want the data ready to go into the pipeline, you need to turn the configuration on in set. PY
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
}
Relation Writing Simultaneous pipeline.py File
import os
import csv
class MyspiderPipeline(object):
def __init__(self):
# csv file
store_file = os.path.dirname(__file__)+"/spiders/school1.csv"
self.file = open(store_file,"a+",newline='',encoding="utf-8")
self.writer = csv.writer(self.file)
def process_item(self, item, spider):
try:
self.writer.writerow((
item["uni_name"],
item["uni_id"],
item["city_code"],
item["uni_type"],
item["slogo"],
item["rank"],
item["safehard"]
))
except Exception as e:
print(e.args)
def close_spider(self,spider):
self.file.close()
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Well, the code is all written, it's still relatively simple. Modify the number above to Figure 7, why 7, because only the first 150 data can be obtained.