Out of octopus, scrapy has been used to climb a commodity website in the past two days, which could have been much faster. One day, I spent time on a line of code and finally changed a parameter around a big circle. I hope you will take less detours.
Many of them are a summary of Mucho. com. https://www.imooc.com/video/17519
Very good!
It's more sensitive, so use the code example of the course.
For the first time, it is unavoidable to teach more professionally.
1. New projects
The first step is to install it first. You can install it according to the video.
In the example, what we want to climb is: https://movie.douban.com/top250
First:
scrapy startproject douban
You created a folder called douban.
Enter cd douban in the Douban folder on cmd and then into the subdirectory cd douban/
Okay, now we need a package associated with the website, cmd input
scrapy genspider douban_spider movie.douban.com
Then we can use pycharm or sublime to import the package and check it.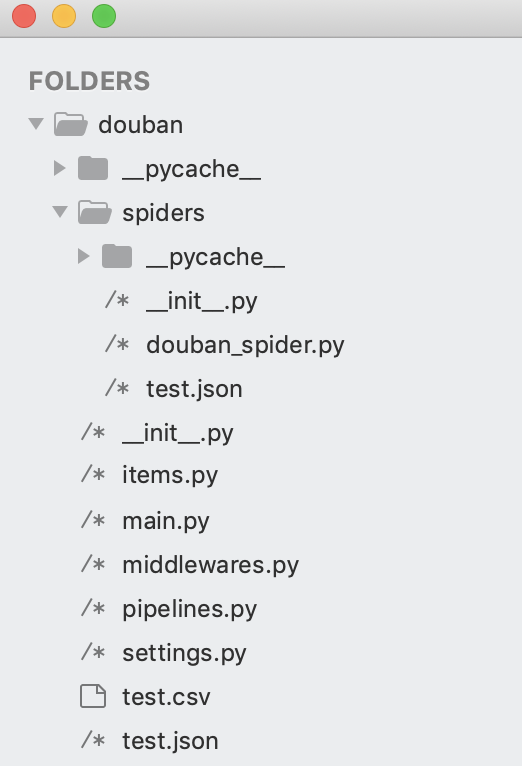
Don't be nervous if you are different from me. Then you should create a new file called main.py in the douban directory.
Find the Settings.py file - > find the user agent that was # dropped -> (this is not a real user agent, we need to open https://movie.douban.com/top250, win directly F12, Mac option+command+I, open the check bar)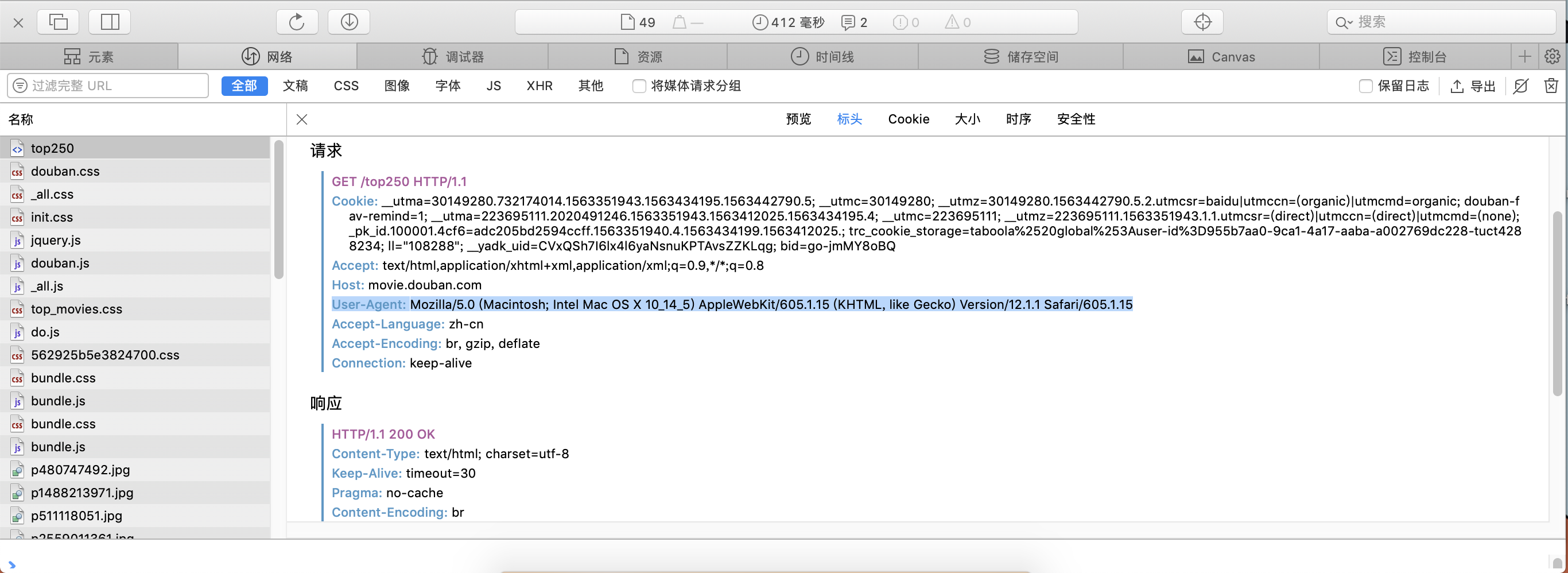
Copy the black text behind the user agent on settings.py. Don't forget to remove the comments.
2. Fast running
In the main.py file, let him replace the function of the terminal and run in the environment.
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())
3. Modify douban_spider.py
Paste the source code first
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']/div[@class='pic']/em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first()
content = i_item.xpath(".//div[@class='info']/div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
yield douban_item
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("http://product.asmag.com.cn"+next_link,callback=self.parse)
First import two packages
import scrapy from douban.items import DoubanItem
Then make a slight change: change start_urls to our code header, what is the code header?
The code header is a piece of code that remains unchanged when each page is automatically turned over.
Let's make an analogy.
The first page to crawl a page is https://www.baidu.com/0-0-1.html
The second page to crawl a page is https://www.baidu.com/0-0-2.html
that https://www.baidu.com It's the code header.
start_urls = ['http://movie.douban.com/top250']
Here's how to write the method
(First of all, we need to learn to check the elements.)
To find the items file, we need to define the target first. In this case, we grab these six elements.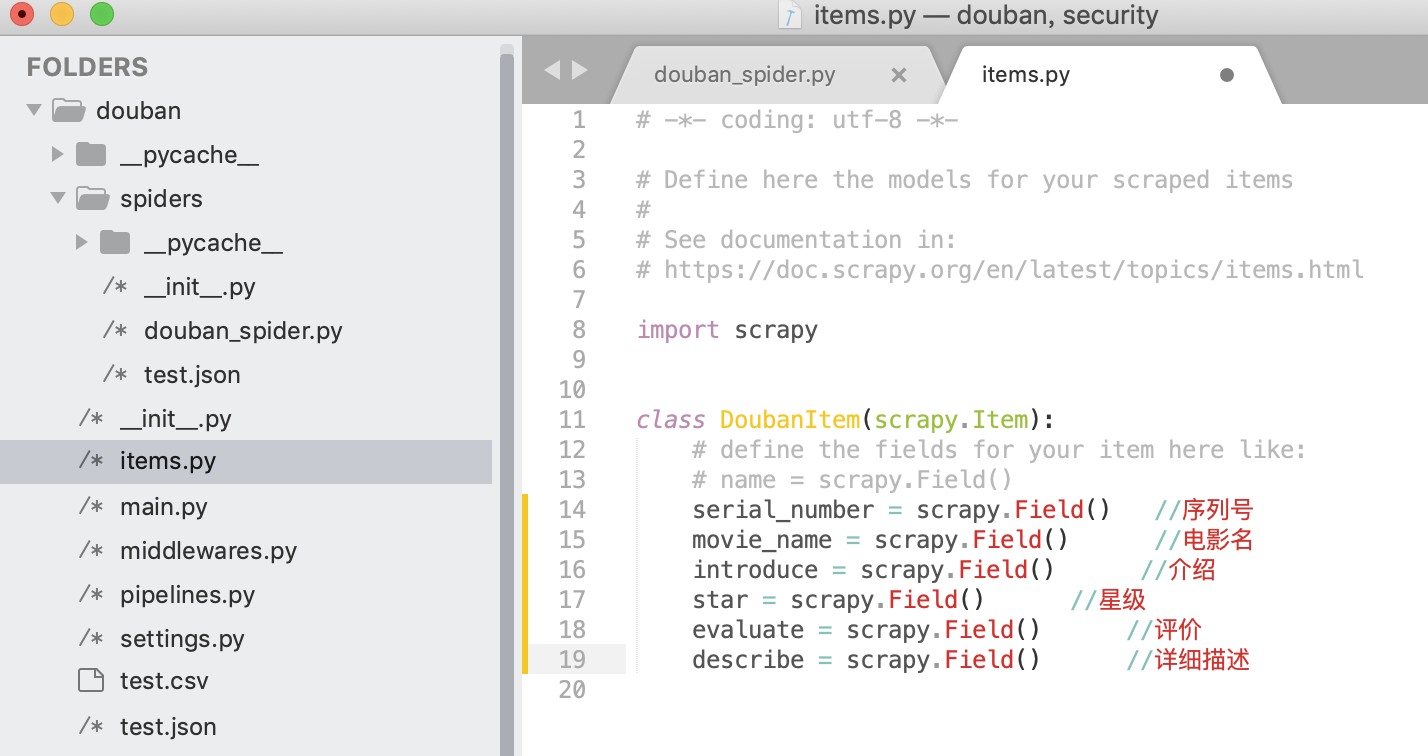
Then we started to find douban_spider.py and write
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
Create movie_list and sneak into a root directory? This means that in the face of html, most of the text elements we check appear after div/ol/li, and carefully observe the folded < li > below. </li > is the detailed information of 25 items on a page.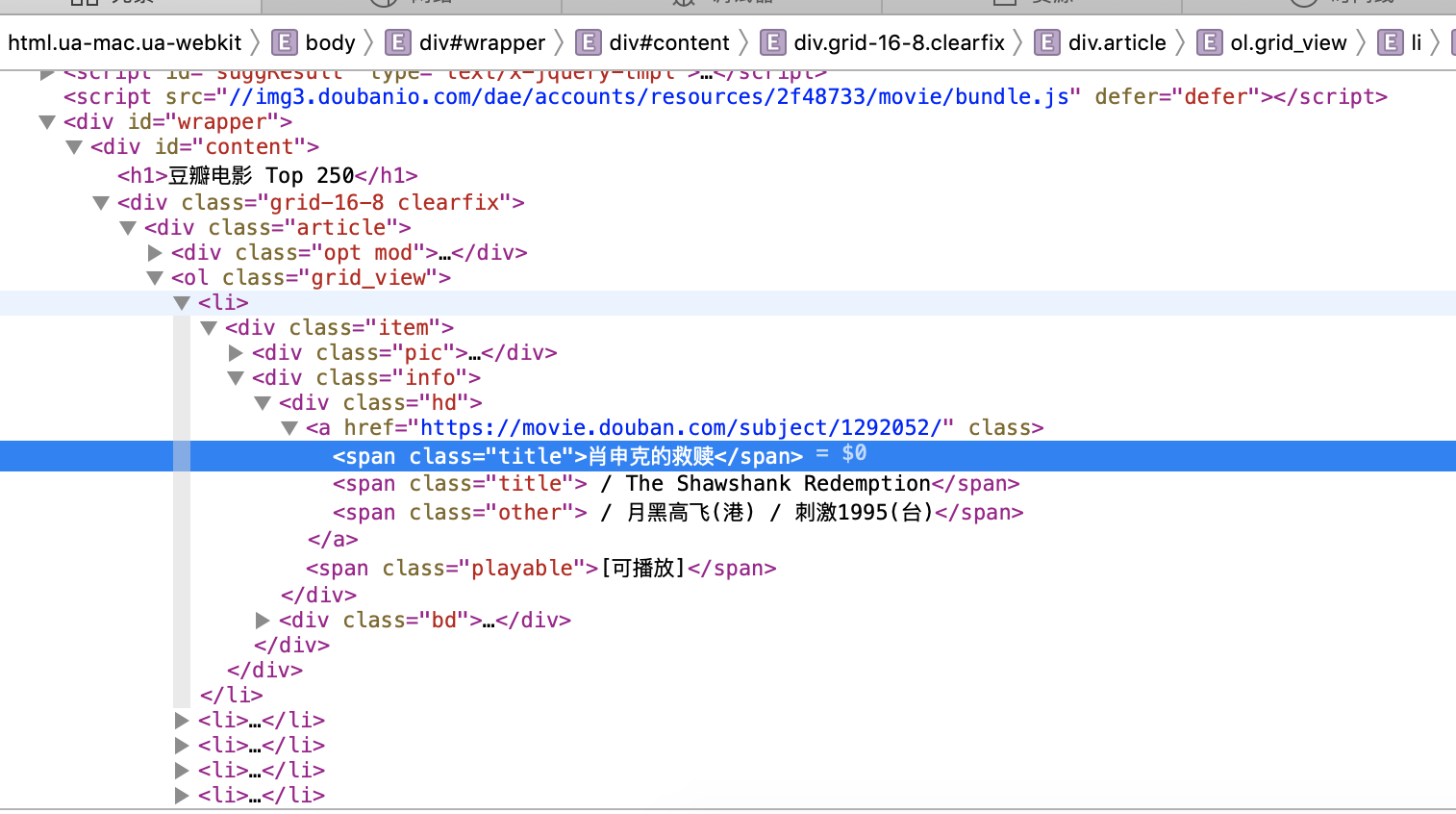
The next step is to change the code in i_item.
Locate each element separately
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']/div[@class='pic']/em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first()
content = i_item.xpath(".//div[@class='info']/div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
yield douban_item #Throwback processing
Remember, the most important thing is:
- Don't forget that the'. 'after xpath serves as the root directory based on the address of the previous movie_list, which is accessed downward as the root directory.
- yield douban_item cannot be omitted, it must be thrown back
- For introduce, because the content is displayed in separate lines, we also need to use a loop to complete the normal fetching.
- For the use of xpath, see what I said above or check the XPath grammar on the Internet.
Finally, turn the page automatically.
With a sigh, Douban is so friendly! The next page button exists, so it's good to execute the address that the next page element points to each time.
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("http://product.asmag.com.cn"+next_link,callback=self.parse)
If the following meaning is, if there is the next page to get the web site has been going on!
But there is no next page in my project. That's how I handled it.
next_link = response.xpath("//div[@class='listpage']/a[@class='on']/following-sibling::a/@href").extract()
The idea is to find the element of a[@class='on'], which represents the current page, and then we find his / following-sibling::a / which is the next sibling element, and then get /@href.
In addition, I have tried BeautifulSoup's method and cssselect's get method, but it's not necessary for this kind of grabbing.
3. Save files
An exciting moment. Back to cmd.
scrapy crawl douban_spider -o test.csv
Save it in csv format and you can see it in the douban folder
But through excel we'll find that it's messy! awsl
Nothing. win can open a notepad and save it as a modified code.
mac users refer to this link: https://www.jianshu.com/p/0a3f587f630e
Well, the perfect solution.