I don't know much about hadoop, but I have encountered a lot of unexpected mistakes in the course of construction. Now I summarize how to build and common error solutions, hoping to help you all. If the following contents are infringed, please contact the author to delete, thank you! First of all, the author uploaded the software version used by the author in Baidu cloud, as well as some testing procedures. [http://pan.baidu.com/s/1miSER12]
1. Installation of JDK
If installed, skip.
JDK choose version 1.7, otherwise there will be compatibility problems, uploaded data has been shared.
First, choose the installation path. The author is / usr/local/java./
You will find that the java folder needs to be created by yourself, as follows:
sudo mkdir /usr/local/java/Check to see if the setup was successful
Find the storage path of the compressed package and extract it under the java folder:
sudo tar -zxf /home/java/jdk-7u80-linux-x64.tar.gz -C /usr/local/javaNote that the first file path is your jdk storage path!
Next, set the environment variables (note the path, file name is the same as yours). For the convenience of the latter, the author set hadoop, hbase, hdfs together:
First find / etc/profile, suggest that the notebook modify this file, use the following commands, remember to use sudo, otherwise there is no permission!
sudo gedit /etc/profileCopy and save the following:
JAVA_HOME=/usr/local/java/jdk1.7.0_80
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export JAVA_HOME
export PATH
Set the default JDK (note the path, file name is the same as yours):
sudo update-alternatives --remove-all "java"
sudo update-alternatives --remove-all "javac"
sudo update-alternatives --remove-all "javaws"
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/local/java/jdk1.7.0_80/bin/java" 1
sudo update-alternatives --install "/usr/bin/javac" "javac" "/usr/local/java/jdk1.7.0_80/bin/javac" 1
sudo update-alternatives --install "/usr/bin/javaws" "javaws" "/usr/local/java/jdk1.7.0_80/bin/javaws" 1
sudo update-alternatives --set java /usr/local/java/jdk1.7.0_80/bin/java
sudo update-alternatives --set javac /usr/local/java/jdk1.7.0_80/bin/javac
sudo update-alternatives --set javaws /usr/local/java/jdk1.7.0_80/bin/javaws
Testing jdk
java -version
2.hadoop
Again, pay attention to your zip path and name!
Here you need to copy the work file of the author's uploaded data to your / home / directory, which can be directly copied.
Unzip installation package
```
sudo tar -zxf /home/gaoxun/download/hadoop-2.6.0.tar.gz -C /usr/local/javaConfiguration file, first change the read and write permissions:
xxx is your username
cd /usr/local/java/
sudo chown -R ××× ./hadoop-2.6.0Configure core-site.xml.
sudo gedit /usr/local/java/hadoop-2.6.0/etc/hadoop/core-site.xml The configuration changes are as follows:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/×××/work/hdfs</value>
</property>
</configuration>
Configure hdfs-site.xml
sudo gedit /usr/local/java/hadoop-2.6.0/etc/hadoop/hdfs-site.xmlChange to:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>The following configuration path:
Enter the / home / directory and use ctrl+h to open the hidden file and find the. bashrc file.
Copy as follows:
export JAVA_HOME=/usr/local/java/jdk1.7.0_80
HADOOP_DIR=/usr/local/java/hadoop-2.6.0
HBASE_DIR=/usr/local/java/hbase-0.98.24-hadoop2
export CLASSPATH=.:${HADOOP_DIR}/etc/hadoop:${HADOOP_DIR}/share/hadoop/common/lib/*:${HADOOP_DIR}/share/hadoop/common/*:${HADOOP_DIR}/share/hadoop/hdfs:${HADOOP_DIR}/share/hadoop/hdfs/lib/*:${HADOOP_DIR}/share/hadoop/hdfs/*:${HADOOP_DIR}/share/hadoop/yarn/lib/*:${HADOOP_DIR}/share/hadoop/yarn/*:${HADOOP_DIR}/share/hadoop/mapreduce/lib/*:${HADOOP_DIR}/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar:${HBASE_DIR}/lib/*
export PATH=${PATH}:${HADOOP_DIR}/bin:${HADOOP_DIR}/sbin:${HBASE_DIR}/binMake the. bashrc file effective
source ~/.bashrcAt this point, you can use the hadoop command in any directory of the terminal.
hadoop version
Start hdfs
start-dfs.shUse
jps
If the jps command fails, try using haoop version and then using jps
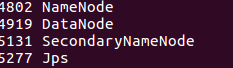
If there is no data node, the start error will occur. Looking at the log log will find that the data node ID is inconsistent with the name node ID. The simplest direct solution is to delete the data data. (Note that the stored data will be deleted. If you configure it for the first time, you don't need to worry about this.)
First close hdfs
stop-dfs.shdata is located in
/home/***/work/hdfs/dfs/dataIn the path, find deletion and restart hdfs.
Setting up folders for hdfs to store files
hdfs dfs -mkdir /hw1It is strongly recommended to configure the hbase file by the way so as not to forget it later.
hdfs dfs -mkdir hbaseYou can use commands to view
hdfs dfs -ls /
Put files into hdfs
hdfs dfs -put ~/work/hw1/tpch/region.tbl /hw1You can use commands to see if you put them in
hdfs dfs -ls /hw1
Testing java programs:
Note that the file name in the java program may not be the same as what I uploaded. Please correct it yourself.
cd ~/work/hw1
javac HDFSTest.java
java HDFSTest.javaIt prints out the content of that file and tests it out.
3.hbase
Note that the hbase file has been generated in hdfs (see previous step), because the following configuration file will be set like this
decompression
sudo tar -zxf /home/***/download/hbase-0.98.24-hadoop2-bin.tar.gz -C /usr/local/javaChange read and write permissions
Note * your username
cd /usr/local/java/
sudo chown -R ××× ./hbase-0.98.24-hadoop2To configure
sudo gedit ./conf/hbase-site.xmlcopy
Note * your username
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/××××/work/hbase-zookeeper</value>
</property>
</configuration>
Start hbase
** Make sure that hdfs is started. Pay attention to opening hdfs first and hbase second.
Turn off hbase before closing hdfs
Remember to turn it off every time you use it, otherwise there will be unexpected mistakes**
start-hbase.shjps view, if the jps command error, you can try to use haoop version after using jps 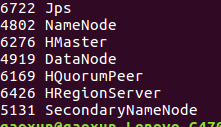
Verify java programs
cd ~/work/hw1
javac HBaseTest.java
java HBaseTest.java** log4j errors may be reported at runtime due to jar package conflicts. The solutions are as follows:
Search log4j under. / hbase-0.98.24-hadoop2/lib and cut the jar package into a new compartment folder. For example, I put it in orig ** 
After the program runs, you can use the hbase command to view it.
hbase shell
scan "Name of table"
disable "Table name" //Delete tables
drop "Table name" //Delete tables
exit
4. Summary
So far, hadoop and hbase are basically completed. In this process, there may be unexpected errors. We should learn to summarize, cite one another, check the error log, the most direct and effective way, try to operate several times, thank you for browsing.
The next blog is expected to outline the following eclipse and hadoop, hbase building.