Configuration of Hot Word Lexicon
1. Using IK built-in Thesaurus
Advantages: Easy deployment, no additional lexical location required
Disadvantage: Single participle, can not specify the entry to be participled
2.IK External Static Lexicon
Advantages: Deployment is relatively convenient, and you can get the desired entries by editing the specified file participle file
Disadvantage: You need to specify external static files, each time you need to manually edit the entire participle file, then put it in the specified file directory, restart ES before it takes effect.
3.IK Remote Lexicon
Advantages: Setting up the lexical information of IK participle by specifying a static file proxy server
Disadvantage: It is necessary to edit the whole participle file manually to add entries. Last-Modified ETag identifier in IK source code is used to judge whether it is updated or not. Sometimes it is not valid.
Combining the advantages and disadvantages of the above, Mysql is chosen as the external hot words lexicon to update the hot words and stop words regularly.
Dead work
1. Download the appropriate version of Elastic Search IK segmenter: https://github.com/medcl/elastic search-analysis-ik
2. Let's look at the files under its config folder: Because I installed ES locally is version 5.5.0, I downloaded an IK adapter version 5.5.0.
Because I installed ES locally is version 5.5.0, I downloaded an IK adapter version 5.5.0.
3. Analyse the IKAnalyr.cfg.xml configuration file:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer Extension Configuration </comment> <! - Users can configure their own extended dictionary here - >. <entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry> <! - Users can configure their extended stop word dictionary here - >. <entry key="ext_stopwords">custom/ext_stopword.dic</entry> <! - Users can configure a remote extended dictionary here - >. <!-- <entry key="remote_ext_dict">words_location</entry> --> <! - Users can configure a remote extended stop word dictionary here - >. <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
ext_dict: The location of the corresponding extended hot word dictionary, with semicolons between multiple hot word files
ext_stopwords: Dictionary locations for extended stopwords, with semicolons between multiple
remote_ext_dict: Remote extension hotword locations such as https://xxx.xxx.xxx.xxx/ext_hot.txt
remote_ext_stopwords: Remote extended stop word locations such as https://xxx.xxx.xxx.xxx/ext_stop.txt
4. In addition to the IKAnalyr.cfg.xml file in the config/folder, we can download the functions of other files under the config folder:
The single method public static synchronized Dictionary initial(Configuration cfg) in Dictionary
private DictSegment _MainDict; private DictSegment _SurnameDict; private DictSegment _QuantifierDict; private DictSegment _SuffixDict; private DictSegment _PrepDict; private DictSegment _StopWords; ... public static synchronized Dictionary initial(Configuration cfg) { if (singleton == null) { synchronized (Dictionary.class) { if (singleton == null) { singleton = new Dictionary(cfg); singleton.loadMainDict(); singleton.loadSurnameDict(); singleton.loadQuantifierDict(); singleton.loadSuffixDict(); singleton.loadPrepDict(); singleton.loadStopWordDict(); if(cfg.isEnableRemoteDict()){ // Establishing monitoring threads for (String location : singleton.getRemoteExtDictionarys()) { // 10 seconds is the initial delay that can be modified by 60 seconds is the interval time unit seconds pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS); } for (String location : singleton.getRemoteExtStopWordDictionarys()) { pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS); } } return singleton; } } } return singleton; }
The load * method in initial is to initialize the member variables declared above in Dictionary by using other text files in config:
_ MainDict: The main dictionary object, which is also used to store hot words
_ Surname Dict: Surname Dictionary
_ Quantifier Dict: Quantifier Dict: Dictionary of quantifiers, such as two or two of one
_ Suffix Dict: Suffix Dict
_ PrepDict: Adverb/Preposition Dictionary
_ StopWords: Stop Words Dictionary
Modify Dictionary source code
Dictionary class: Update dictionary this.loadMySQLExtDict()
private void loadMySQLExtDict() { Connection conn = null; Statement stmt = null; ResultSet rs = null; try { Path file = PathUtils.get(getDictRoot(), "jdbc-loadext.properties"); prop.load(new FileInputStream(file.toFile())); logger.info("jdbc-reload.properties"); for(Object key : prop.keySet()) { logger.info(key + "=" + prop.getProperty(String.valueOf(key))); } logger.info("query hot dict from mysql, " + prop.getProperty("jdbc.reload.sql") + "......"); conn = DriverManager.getConnection( prop.getProperty("jdbc.url"), prop.getProperty("jdbc.user"), prop.getProperty("jdbc.password")); stmt = conn.createStatement(); rs = stmt.executeQuery(prop.getProperty("jdbc.reload.sql")); while(rs.next()) { String theWord = rs.getString("word"); logger.info("hot word from mysql: " + theWord); _MainDict.fillSegment(theWord.trim().toCharArray()); } } catch (Exception e) { logger.error("erorr", e); } finally { if(rs != null) { try { rs.close(); } catch (SQLException e) { logger.error("error", e); } } if(stmt != null) { try { stmt.close(); } catch (SQLException e) { logger.error("error", e); } } if(conn != null) { try { conn.close(); } catch (SQLException e) { logger.error("error", e); } } } }
Dictionary class: Update the stop word this.loadMySQLStopwordDict()
private void loadMySQLStopwordDict() { Connection conn = null; Statement stmt = null; ResultSet rs = null; try { Path file = PathUtils.get(getDictRoot(), "jdbc-loadext.properties"); prop.load(new FileInputStream(file.toFile())); logger.info("jdbc-reload.properties"); for(Object key : prop.keySet()) { logger.info(key + "=" + prop.getProperty(String.valueOf(key))); } logger.info("query hot stopword dict from mysql, " + prop.getProperty("jdbc.reload.stopword.sql") + "......"); conn = DriverManager.getConnection( prop.getProperty("jdbc.url"), prop.getProperty("jdbc.user"), prop.getProperty("jdbc.password")); stmt = conn.createStatement(); rs = stmt.executeQuery(prop.getProperty("jdbc.reload.stopword.sql")); while(rs.next()) { String theWord = rs.getString("word"); logger.info("hot stopword from mysql: " + theWord); _StopWords.fillSegment(theWord.trim().toCharArray()); } } catch (Exception e) { logger.error("erorr", e); } finally { if(rs != null) { try { rs.close(); } catch (SQLException e) { logger.error("error", e); } } if(stmt != null) { try { stmt.close(); } catch (SQLException e) { logger.error("error", e); } } if(conn != null) { try { conn.close(); } catch (SQLException e) { logger.error("error", e); } } } }
Exposure methods:
public void reLoadSQLDict() { this.loadMySQLExtDict(); this.loadMySQLStopwordDict(); }
MySQLDictReloadThread Runnable implementation class to execute reLoadSQLDict() load hotwords:
import org.apache.logging.log4j.Logger; import org.elasticsearch.common.logging.ESLoggerFactory; /** * Created with IntelliJ IDEA. * * @author: zhubo * @description: Timing execution * @time: 2018 23:05:24, July 22, 2000 * @modifytime: */ public class MySQLDictReloadThread implements Runnable { private static final Logger logger = ESLoggerFactory.getLogger(MySQLDictReloadThread.class.getName()); @Override public void run() { logger.info("reloading hot_word and stop_worddict from mysql"); Dictionary.getSingleton().reLoadSQLDict(); } }
The final code is a timing call: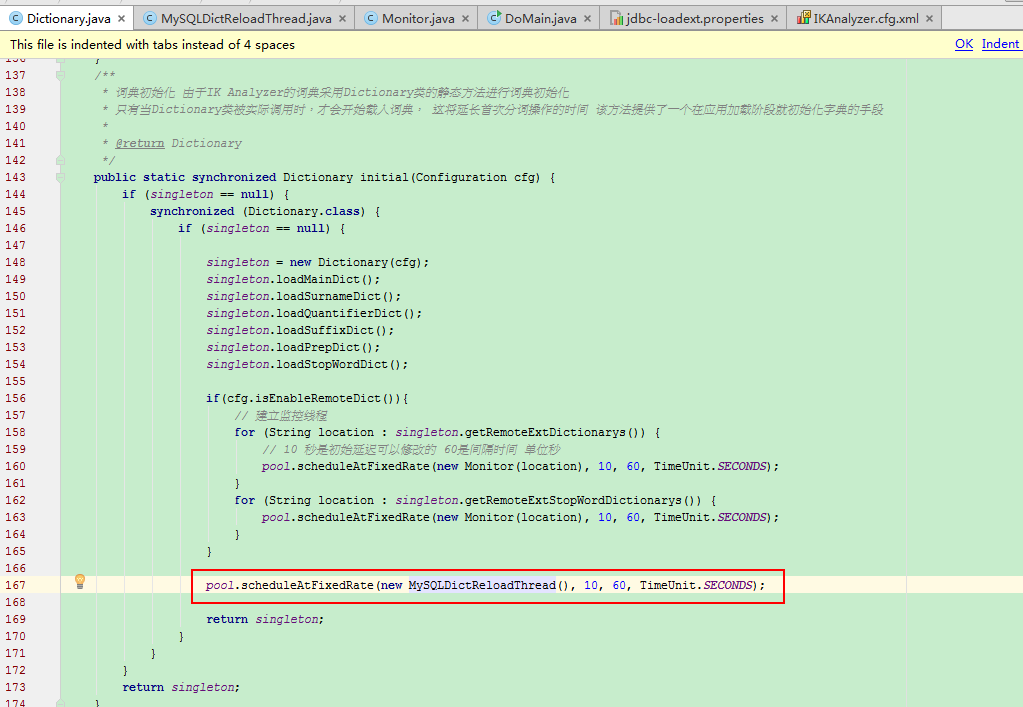
Some of the details will not be covered.
jdbc-loadext.properties
jdbc.url=jdbc:mysql://172.16.11.119:3306/stop_word?useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8 jdbc.user=root jdbc.password=123456 jdbc.reload.sql=select word from hot_words jdbc.reload.stopword.sql=select stopword as word from hot_stopwords
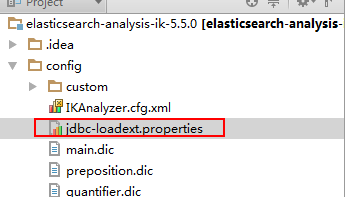 Files in this location
Files in this location
Pack
Because we are linking to the mysql database, the maven project will introduce mysql driver:
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>6.0.6</version> </dependency>
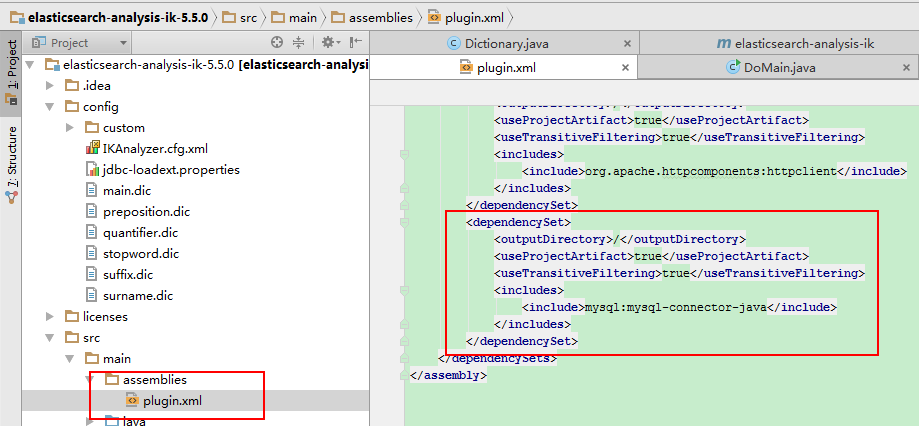
This alone is not enough. You need to modify the plugin.xml file (when you encounter this pit, the newly introduced dependency packages that modify the pom don't always go in):
Ready: Execute packing. mvn clean package
 Packing is done. Upload, restart the experiment. C
Packing is done. Upload, restart the experiment. C
experimental result
Database insertion record
GET http://172.16.11.119:9200/g_index/_analysis? Text = real cannon & analyzer = ik_smart { "tokens": [ { "token": "It's really a mountain gun.", "start_offset": 0, "end_offset": 4, "type": "CN_WORD", "position": 0 } ] } GET http://172.16.11.119:9200/g_index/_analysis? Text = big eared Rabbit & analyzer = ik_smart { "tokens": [ { "token": "Big-eared Rabbit", "start_offset": 0, "end_offset": 5, "type": "CN_WORD", "position": 0 } ] } GET http://172.16.11.119:9200/g_index/_analysis? Text = big eared rabbit. You're a real cannon & analyzer = ik_smart { "tokens": [ { "token": "Big-eared Rabbit", "start_offset": 0, "end_offset": 5, "type": "CN_WORD", "position": 0 }, { "token": "you", "start_offset": 5, "end_offset": 6, "type": "CN_CHAR", "position": 1 }, { "token": "It's really a mountain gun.", "start_offset": 6, "end_offset": 10, "type": "CN_WORD", "position": 2 } ] } GET http://172.16.11.119:9200/g_index/_analysis? Text = big eared rabbit. You're a real cannon & analyzer = ik_max_word { "tokens": [ { "token": "Big-eared Rabbit", "start_offset": 0, "end_offset": 5, "type": "CN_WORD", "position": 0 }, { "token": "Ear", "start_offset": 1, "end_offset": 3, "type": "CN_WORD", "position": 1 }, { "token": "ear", "start_offset": 1, "end_offset": 2, "type": "CN_WORD", "position": 2 }, { "token": "Duo", "start_offset": 2, "end_offset": 3, "type": "CN_WORD", "position": 3 }, { "token": "Rabbit", "start_offset": 3, "end_offset": 5, "type": "CN_WORD", "position": 4 }, { "token": "rabbit", "start_offset": 3, "end_offset": 4, "type": "CN_WORD", "position": 5 }, { "token": "son", "start_offset": 4, "end_offset": 5, "type": "CN_CHAR", "position": 6 }, { "token": "you", "start_offset": 5, "end_offset": 6, "type": "CN_CHAR", "position": 7 }, { "token": "It's really a mountain gun.", "start_offset": 6, "end_offset": 10, "type": "CN_WORD", "position": 8 }, { "token": "Really", "start_offset": 6, "end_offset": 8, "type": "CN_WORD", "position": 9 }, { "token": "Mountain Gun", "start_offset": 8, "end_offset": 10, "type": "CN_WORD", "position": 10 }, { "token": "cannon", "start_offset": 9, "end_offset": 10, "type": "CN_WORD", "position": 11 } ] }
(o)... I don't know why I cite such an example, let's just count on it. Mountain cannon