Background metasomatism
In fact, there are many websites involved in the anti-climbing circle. At present, websites often bullied by the reptile coder, cat's eye movies, automobile homes, public comments, 58 cities, day-eye checks... There are still many, tens of millions of skilled technicians, there are always various anti-climbing technologies, for the reptile coder, do! That's it. It's 996 anyway.~
As a series of articles, it is inevitable to take cat's eye movies and TV "learning" it, why? Because it's typical.~
Cat eye video
Open Cat Eye Professional Edition, General Operations, Google Browser, Developer Tools, Grab DOM Nodes,
Note that all the digit positions in the following figure are square in the DOM structure.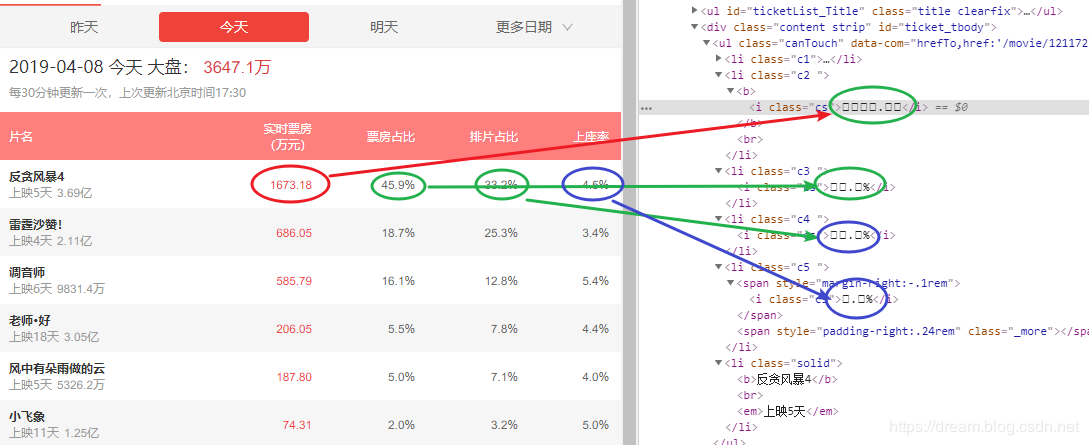
Font Anti-climbing Literacy
Font anti-crawling is a common anti-crawling technology. The website uses a custom font file to display normally on the browser, but the data captured by the crawler is either scrambled or changed into other characters. Custom font file is a new feature of CSS3. Those who are familiar with the front end may know that it is font-face attribute.
Collection of some important cracking materials
Find the font-family attribute, look at the settings, and find that the font is cs, which is obviously a custom font. Retrieve CS in the web page.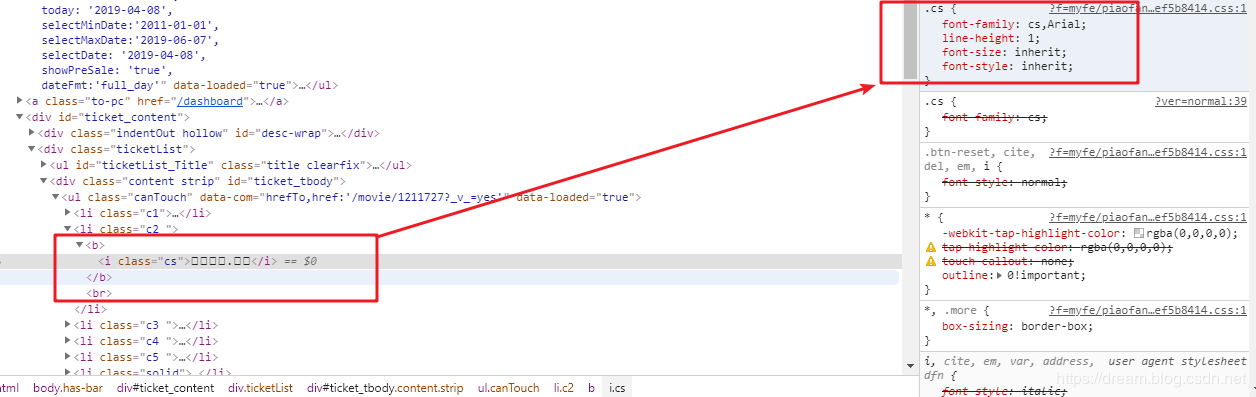
Font definition was found in HTML source code of the page
Note that the beginning of the file is base64, which means that the file has been encoded by Base64 and needs to be decoded, then saved as a ttf font file.
The screenshot above has a woff format
Web Open Font Format (WOFF) is a standard font format used in Web pages. This font format developed in 2009 and is now being standardized by the Web Font Working Group of the World Wide Web Consortium to become a recommendation standard. This font format not only reduces file size by compression, but also does not contain encryption and is not restricted by DRM (Digital Copyright Management).
Decoding operation
import base64
font_face = "d09GRgABAAAAAAggAAsAAAAAC7gAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7laVY21hcAAAAYAAAAC8AAACTA/VLRxnbHlmAAACPAAAA5EAAAQ0l9+jTWhlYWQAAAXQAAAALwAAADYUwblKaGhlYQAABgAAAAAcAAAAJAeKAzlobXR4AAAGHAAAABIAAAAwGhwAAGxvY2EAAAYwAAAAGgAAABoF2gTmbWF4cAAABkwAAAAfAAAAIAEZADxuYW1lAAAGbAAAAVcAAAKFkAhoC3Bvc3QAAAfEAAAAXAAAAI/gSKzLeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2Bk0mWcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr7LMev812GIYdZhuAIUZgTJAQDZjgsneJzFkj0OgzAMhV8KpT906NiJE3ThUIgrsLL0BD1Fxk5dOAC3iEgkJEYWRvoSs1SCtXX0RbId+Vl2AOwBROROYkC9oeDtxagK8QjnEI/xoH/DlZEjKpMb3Vnbuto1fTkUo56yeeaL7cyaKVZcOz6TUOlE9R0O7DOlqu8w2aj0A1P/k/62S7ifi5eSaoEtmlzg/GC04HfcWYEzhW0Fv1tXC5wzXCNw4uhLwf+RoRC81qgF7gNTJiD+ANtoRPR4nEWTz2/aZhzG39dUOCWEkGHjQlrAmNgGkuDY2ARwDMWBNj8ZCRBCWhqiltJsbbOo6dI22lr2Q2qn/QHdZdIOu1Q79N5J03raOrU59A+o1Otum9RLRPbaIZkPr/S+0vs+n+f7PAYQgMO/gQgIgAGQkEjCR/AAfdBcDrGXwAWAS6ZJhwW34owGE0oCLTG4z+jTksvTtwaHnP60L0tjtyr5UPPeg2z9k0hL3b2dvMSiJzDznQPsL2ADAwDQMi1DaUgiGZIbskC9+ycsXGw2a++eleB+Vyg9O0Bnvx7dO/wXA9gbwIAYIvNBSUS6GpyCcc6KW5kgK8cVSfRBknBAJsixHIyzTNBKEpRbVL7rV4VImnNYceiJjSZW73+5Mb2jpu8WK3HFBttLk+lqOHKv+Isqj2iyVxnuO2WNeL0PN29+M/d958lPlfFYBabnVxuLhXB05f957CAeO3LBDDkgLpuTkOBOLdDmZyaH+f4kJvhUZyUoegTq6A7ycAr7Hfh7DhQTEedcNEnjGjpwk4ThBdF/a5tRsrWqHtWJ5Ty82n3PBaaZxqNk/vONKa3vZT638bTK+m1wq/ybm3p0ff3iijJZP+b6gLhCAIyQdDyhWQysYyUNGhpWHPGiBOGHLtdvG+aTbKpIhufUzDysn959vUtHCV3gReqjvnLZ7/PEYnJAmD03eW1mtmBr3diujC2IVIanx85QAz1f/6BuvAHRE18cksMTlKjIPWElgdKhfBBpGxkZgXGdwQuKVuHCqjdkcyRXM4o0bas5k6lySpyQxYnMhcftK3un/5jLVfc43rYA01NCRssN1mMT3jO19Tn34KXC5a+26uC4H7CLGAJgFCGxJoDhk+zN1WgF6oiJ4aYgYXIiuqAV/mAnQ/FIIELZBwJr0spe6mru1pN5/bOKItu7T7k8q5SKd8uYO06NUP7kuWVlYrzT0u9M/fhiv7EkjJe7r0Yr0frCzEoVWE56SqCUx9C/YvTSzNW0jaJF+wThlkQjk6DVQrgptFGOds8/3XqxvZnLd96ezxaEXFxgaL11/mxwJBgOSGS4/EUJfs1vfnzj9nybd1/JXd7T1Gah8XM8E/A39Gz3MZcnXCTBPVwqnczkoMcCXKgL0DTfa4DRM0QiKk6ORbOKeLztxe30WafT7hi+VryuFuql+8sR/kFoDDY7s4vltUhWvZlpcYvLs7VXz+/swPV0SsqB/wAGjODCAAAAeJxjYGRgYADixSuWzY3nt/nKwM3CAAI3LlqdRND/37AwMJ0HcjkYmECiAGAmDGEAeJxjYGRgYNb5r8MQw8IAAkCSkQEV8AAAM2IBzXicY2EAghQGBiYd4jAAN4wCNQAAAAAAAAAMADAATACUAK4A4AEaAVwBoAHmAhoAAHicY2BkYGDgYTBgYGYAASYg5gJCBob/YD4DAA6DAVYAeJxlkbtuwkAURMc88gApQomUJoq0TdIQzEOpUDokKCNR0BuzBiO/tF6QSJcPyHflE9Klyyekz2CuG8cr7547M3d9JQO4xjccnJ57vid2cMHqxDWc40G4Tv1JuEF+Fm6ijRfhM+oz4Ra6eBVu4wZvvMFpXLIa40PYQQefwjVc4Uu4Tv1HuEH+FW7i1mkKn6Hj3Am3sHC6wm08Ou8tpSZGe1av1PKggjSxPd8zJtSGTuinyVGa6/Uu8kxZludCmzxMEzV0B6U004k25W35fj2yNlCBSWM1paujKFWZSbfat+7G2mzc7weiu34aczzFNYGBhgfLfcV6iQP3ACkSaj349AxXSN9IT0j16JepOb01doiKbNWt1ovippz6sVYYwsXgX2rGVFIkq7Pl2PNrI6qW6eOshj0xaSq9mpNEZIWs8LZUfOouNkVXxp/d5woqebeYIf4D2J1ywQB4nG2KOxKAIBBDN/hBEe8ioKAlKt7Fxs4Zj++4tKZ5k7yQoBxF/9EQKFCiQg2JBi0UOmj0hEfe15nG2TCHGD8ewSTuwYe8u+zHdWdv8y/Z5JhuW5jRT0QvGVQXkQ=="
print(len(font_face))
b = base64.b64decode(font_face)
with open('font.ttf','wb') as f:
f.write(b)There are three ways to process ttf files. The first way is to use FontCreator to open ttf files directly. The second way is to use Python third-party library font Tools, which can also operate ttf files. The third way is to use Baidu fontstore. http://fontstore.baidu.com/static/editor/index.html
FontCreator software can find this easily
You can search for Baidu by yourself or open my Baidu Disk to download directly.
Links: https://pan.baidu.com/s/1ZyWwk37hNeo0vIsTqdK2fg Extraction code: kk2h
After installation, you can try it out directly, or you can use the state-supported harmony method to achieve harmony.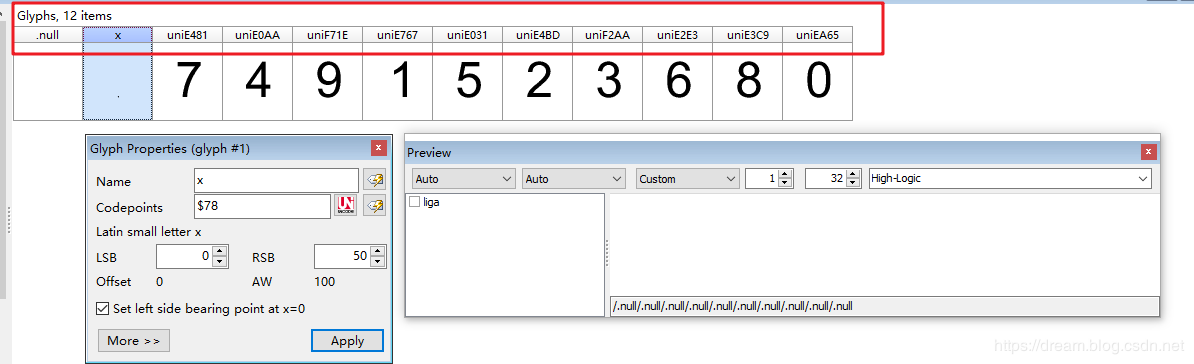
Check the html encoding in source
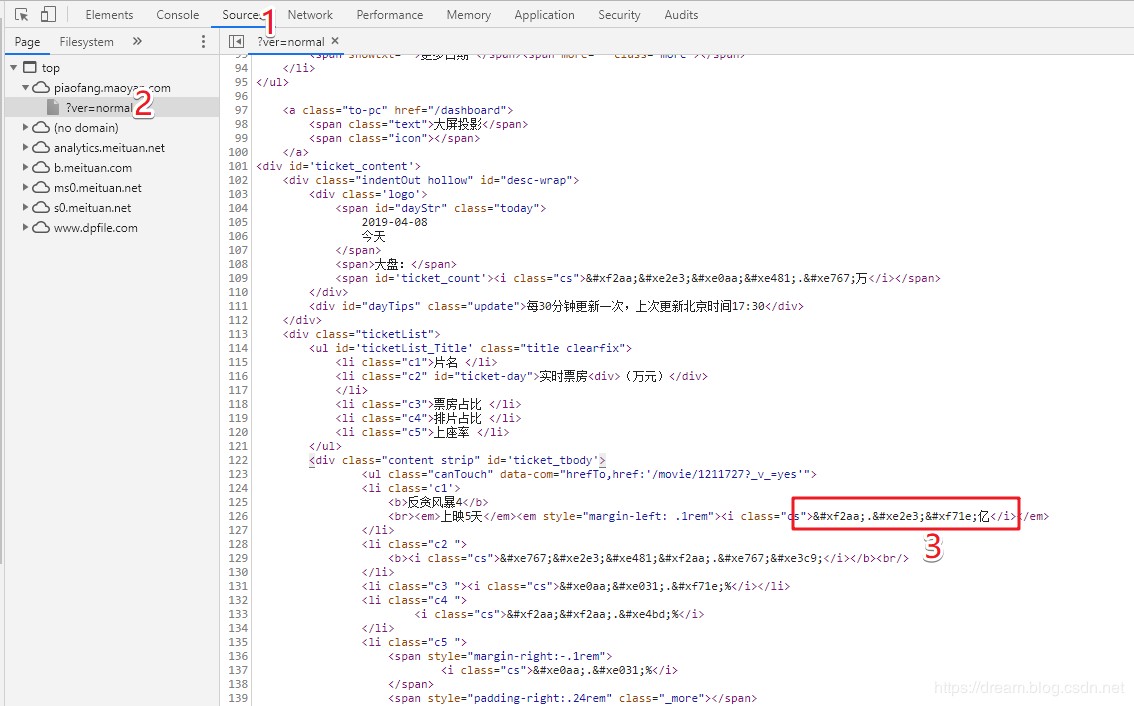
Number comparison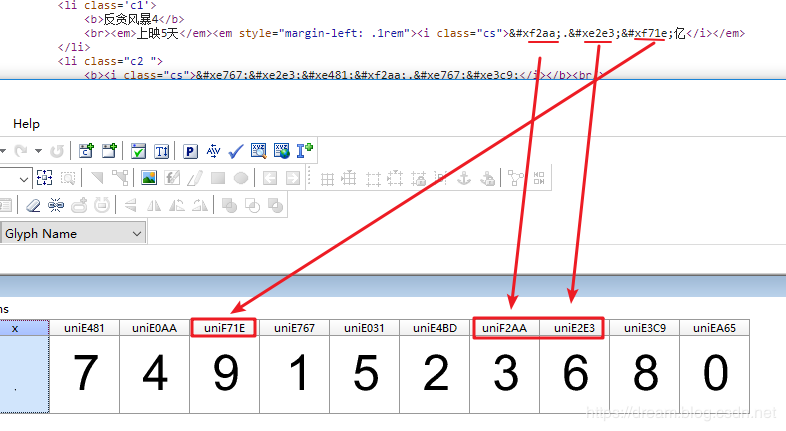
By the way, record the corresponding relationship between the codes in this place for the convenience of subsequent operation.
'uniE481': '7', 'uniE0AA': '4', 'uniF71E': '9', 'uniE767': '1', 'uniE031': '5', 'uniE4BD': '2', 'uniF2AA': '3', 'uniE2E3': '6', 'uniE3C9': '8', 'uniEA65': '0'
Number comparisons are totally okay at 369 million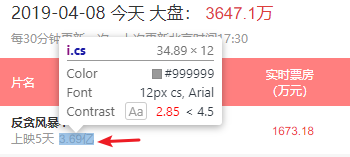
Start coding crack font crawl
Some web pages are nested with multiple fonts, which increases the cost of anti-crawling, and can be studied by oneself at that time.
With fontTools, you can get every character object, which you can simply understand as preserving the shape information of the character.
And the encoding can be used as the id of this object, which has a one-to-one correspondence.
Similar to cat-eye movies, the encoding of characters corresponding to multiple fonts is changed, but the shape of the characters is unchanged, that is to say, the object is unchanged.
Parsing font files through font Tools
Install fonttools
pip install fonttools
The font Tools library details: https://darknode.in/font/font-tools-guide/
Basic use
from fontTools.ttLib import TTFont
font = TTFont('font.ttf')
font.saveXML('01.xml')Open the xml file
At the beginning, all the codes are displayed. Note that the ID here is the number. Never use it as the corresponding number.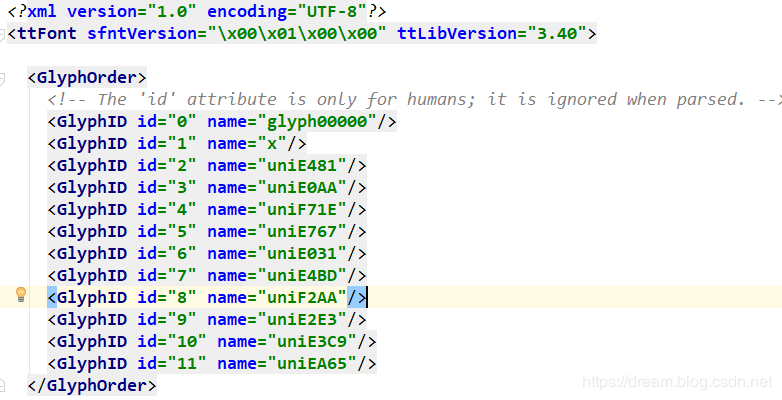
The following corresponds to the font information. The computer only needs to know the black and white pixels.
Notice that you need to pay attention to when you write code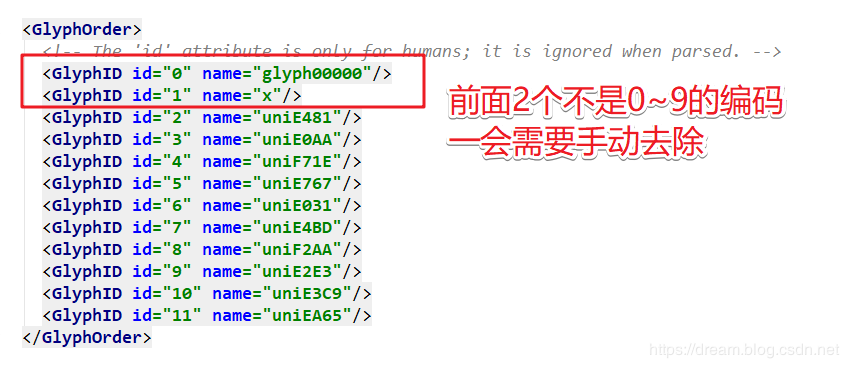

Summary of Cat's Eye Font Crawling Back
In practice, you will find that cat's eye movies, each refresh character encoding is changed, but the font object, that is, the pixels are consistent.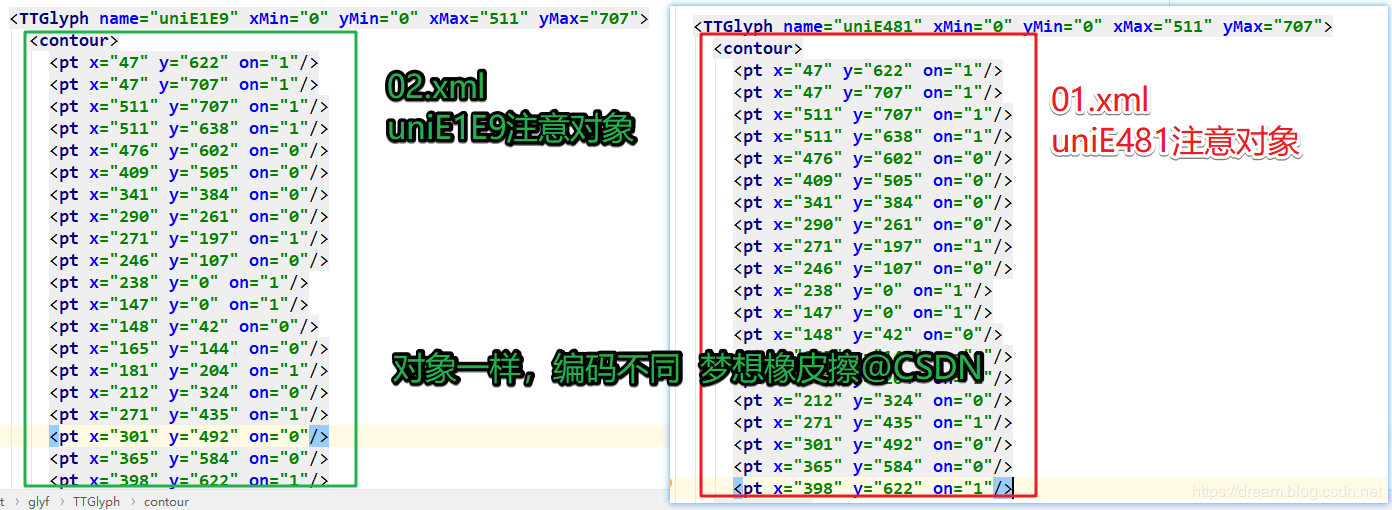
You can download a font file base_font.ttf for the first time and write down the corresponding codes. When you refresh the page for the second time, you can retrieve the font file online_font.ttf and compare the object information in the two font files. If the object is the same, you can know the corresponding number.
Get font file for the first time
# Font processing that has been downloaded locally
base_font = TTFont('font.ttf') #Open the local ttf file
base_uni_list = base_font.getGlyphOrder()[2:] # Get all the codes and remove the first two. See the previous illustration.
# Write out the encoding of the first font file and the corresponding font
origin_dict = {'uniE481': '7', 'uniE0AA': '4', 'uniF71E': '9', 'uniE767': '1', 'uniE031': '5', 'uniE4BD': '2','uniF2AA': '3', 'uniE2E3': '6', 'uniE3C9': '8', 'uniEA65': '0'}Getting online fonts
# Get the online font after refresh
# Getting base64 encoding for font files
online_ttf_base64 = re.findall(r"base64,(.*)\) format", response)[0]
online_base64_info = base64.b64decode(online_ttf_base64)
with open('online_font.ttf', 'wb')as f:
f.write(online_base64_info)
online_font = TTFont('online_font.ttf') # Font files downloaded dynamically on the Internet.
online_uni_list = online_font.getGlyphOrder()[2:]
for uni2 in online_uni_list:
obj2 = online_font['glyf'][uni2] # Get the corresponding object of coding uni2 in online_font.ttf
for uni1 in base_uni_list:
obj1 = base_font['glyf'][uni1] # Get the corresponding object coded uni1 in base_font.ttf
if obj1 == obj2: # Judging whether two objects are equal
dd = "&#x" + uni2[3:].lower() + ';' # Modified to Unicode encoding format
if dd in response: # If the Unicode encoding format for uni2 is in response, replace the number in origin_dict.
response = response.replace(dd, origin_dict[uni1])response is acquired by request module
url = 'https://piaofang.maoyan.com/?ver=normal'
headers = {
'User-Agent': 'Browser UA',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
response = requests.get(url=url, headers=headers).content # Get bytes
charset = chardet.detect(response).get('encoding') # Get the encoding format
response = response.decode(charset, "ignore") # Decode to get a string
Operation results display

Focus on Wechat Public Account: Non-undergraduate programmer, reply 0409 for download address
