Assignment 1: Designing color visualization works for movie posters. Imitate the color of movie posters on page 43 of Chapter IV of PPT for visualization since 1914. Design and implement the color visualization works of domestic movie posters from 2008 to 2018. Specific requirements are as follows:
Python language is used to compile a crawler program to obtain poster pictures of Chinese domestic movies from 2008 to 2018 on the Internet and store them in annual classifications.
For these pictures, the color values of each pixel on each picture are obtained.
Statistics of pixel color values in each poster image;
Longitudinal coordinates represent from top to bottom from 2008 to 2018, and abscissa represents the colors contained in the movie posters of that year (simply 7-color light as statistical unit)
From left to right, red, orange, yellow, green, blue and purple
An analysis and interpretation of the work at the perceptual and cognitive levels
According to the general process of PPT page 4 of this chapter, describe the process of completion and experience of writing works.
1. Using Python to Crawl the Data of 1905 Website
On this basis, I made some modifications to meet the needs of teachers.
# Responsible for downloading movie posters
def download_img(title, img_addr, headers, time):
# If no picture folder exists, it is automatically created
if os.path.exists("./Top250_movie_images/"):
pass
else:
os.makedirs("./Top250_movie_images/")
if os.path.exists("./Top250_movie_images/" + time + "/"):
pass
else:
os.makedirs("./Top250_movie_images/" + time + "/")
# Getting Binary Data of Pictures
image_data = requests.get(img_addr, headers=headers).content
# Setting the path and name of poster storage
image_path = "./Top250_movie_images/" + time + "/" + title[0] + '.jpg'
# Store poster pictures
with open(image_path, "wb+") as f:
f.write(image_data)
# Get data according to url, print it to screen and save it as a file
def get_movies_data(url, headers):
# Get the response content of the page
db_response = requests.get(url, headers=headers)
# Converting the obtained source code to etree
db_reponse_etree = etree.HTML(db_response.content)
# Extract all movie data
db_movie_items = db_reponse_etree.xpath('//*[@class="fl line"]/a')
print(len(db_movie_items))
# Traversing the movie data list,
for db_movie_item in db_movie_items:
# The knowledge of xpath is used here.
db_title = db_movie_item.xpath('img/@alt')
print(db_title)
db_date = db_movie_item.xpath('img/@data-original')
db_img_addr = db_movie_item.xpath('img/@src')
word = 'uploadfile'
index = [m.start() + 11 for m in re.finditer(word, str(db_date[0]))]
print(index)
db_movie_date = db_date[0][index[0]:index[0]+4]
print("Title:", db_title[0]+" time:", db_movie_date + " URL:", db_date[0])
# a denotes the addition mode, b denotes writing in binary mode, and + denotes automatic creation if the file does not exist
with open("./douban_movie_top250.txt", "ab+") as f:
tmp_data = "Title:"+str(db_title)+ "-" + str(db_movie_date) + "\n"
f.write(tmp_data.encode("utf-8"))
db_img_addr = str(db_img_addr[0].replace("\'", ""))
download_img(db_title, db_img_addr, headers, str(db_movie_date))
The screenshot shows a crawl of movie posters from 2008 to 2019
2. For these pictures, get the color value of each pixel on each picture.
Use list_all_files('. / Top250_movie_images') to traverse the generated posters
Import from PIL import Image and use toRGB(name) to generate corresponding color values for each poster
Generate corresponding files using data_write_csv(file_name, datas) or text_save (file name, data)
def data_write_csv(file_name, datas): # file_name is the path to write to the CSV file, and data is the list of data to write to.
file_csv = codecs.open(file_name, 'w+', 'utf-8') # Append
writer = csv.writer(file_csv, delimiter=' ',
quotechar=' ', quoting=csv.QUOTE_MINIMAL)
for data in datas:
writer.writerow(data)
print("Save the file successfully and finish processing")
def text_save(filename, data): # filename is the path to write CSV files and data is the list of data to write.
file = open(filename, 'a')
for i in range(len(data)):
s = str(data[i]).replace(
'[', '').replace(']', '') # Remove [], and the two lines are optional depending on the data.
s = s.replace("'", '').replace(',', '') + '\n' # Remove single quotation marks, commas, and add line breaks at the end of each line
file.write(s)
file.close()
print("Save the file successfully")
def list_all_files(rootdir):
import os
_files = []
list = os.listdir(rootdir) # List all directories and files under folders
for i in range(0, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isdir(path):
_files.extend(list_all_files(path))
if os.path.isfile(path):
_files.append(path)
print(path)
name = path[22:]
toRGB(name)
# print(name)
return _files
def toRGB(name):
time = name[:4]
title = name[5:-4]
print(title + " " + time)
img = Image.open("C:\\Users\\Ifand\\Top250_movie_images\\" + name)
img_array = img.load()
width, height = img.size
all_pixels = []
for x in range(width):
for y in range(height):
cpixel = img_array[x, y]
all_pixels.append(cpixel)
# print(img_array[6, 4])
print(len(all_pixels))
# If no folder exists, it is automatically created
if os.path.exists("./Top250_movie_images/RGBFiles"):
pass
else:
os.makedirs("./Top250_movie_images/RGBFiles")
if os.path.exists("./Top250_movie_images/RGBFiles/" + time + "/"):
pass
else:
os.makedirs("./Top250_movie_images/RGBFiles/" + time + "/")
# data_write_csv("./Top250_movie_images/RGBFiles/" + time + "/" + title + ".csv", all_pixels)
text_save("./Top250_movie_images/RGBFiles/" + time + "/" + title + ".txt", all_pixels)Three. Generated Data Visualization Interface
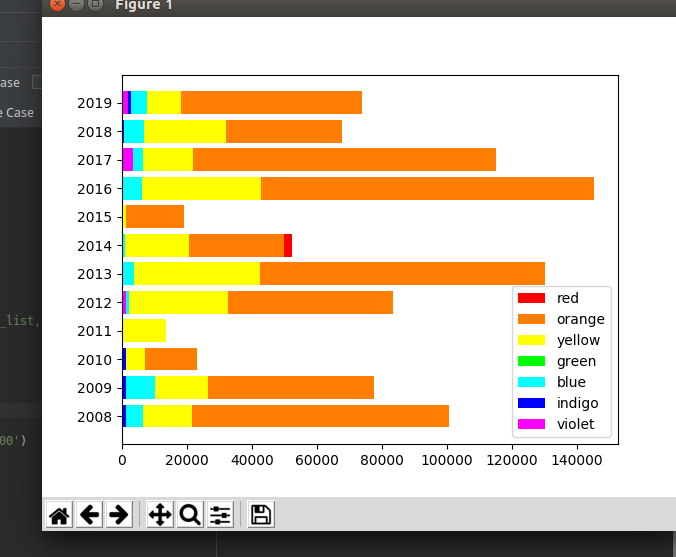
Code address: https://fgk.pw/i/pz0ohi73031
Because the website may be updated, it is recommended to run task3.py code first. View the effect.