python version: 3.7
Introduction:
Change user_id and cookie in main_spider to their ID and cookie.
Open Microblog Mobile Edition https://m.weibo.cn/
Enter the designated user's home page, such as Li Ronghao's home page: https://m.weibo.cn/u/1739046981?uid=1739046981&luicode=10000011&lfid=231093_-_selffollowed
1739046981 is the user id.
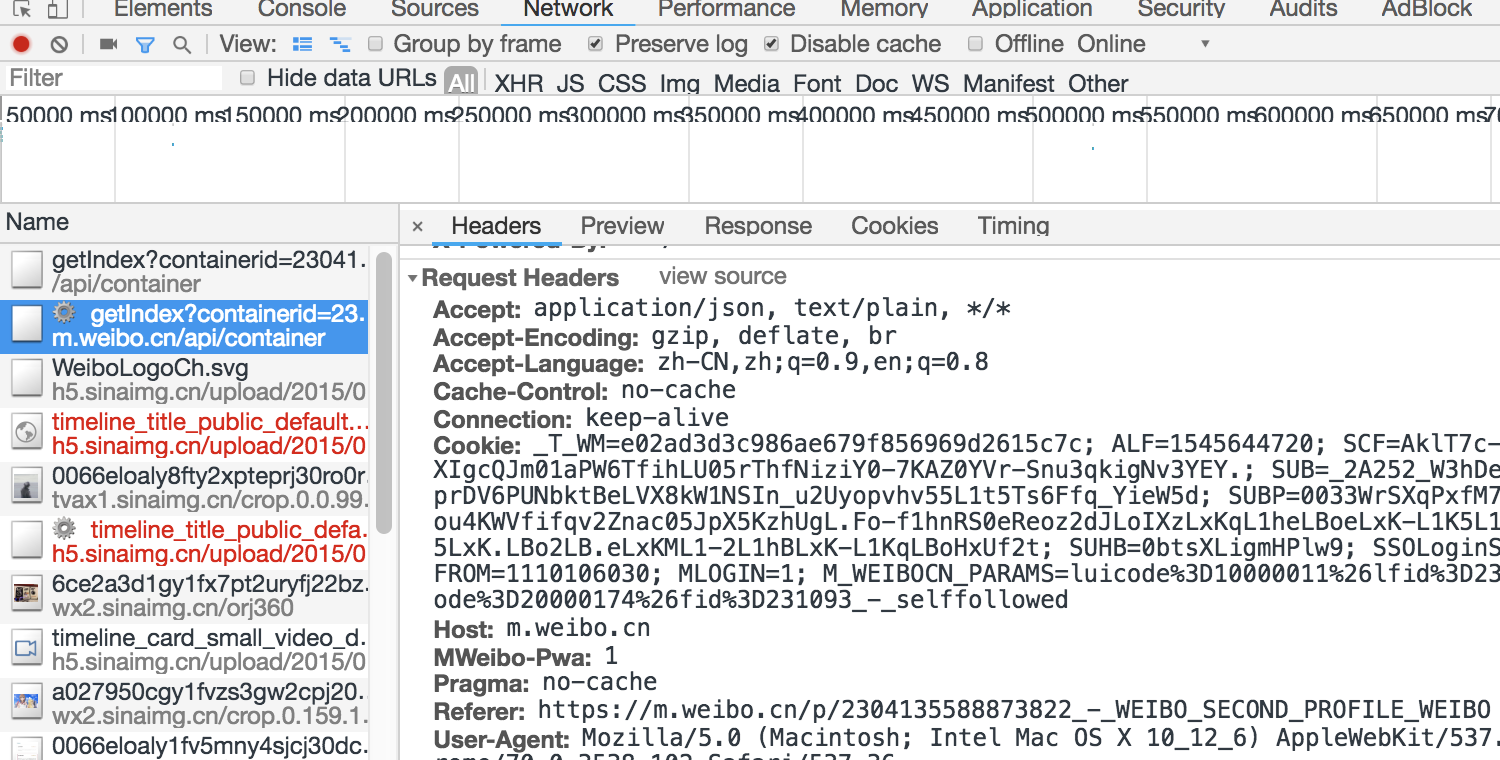
Log on to Weibo, enter the personal home page, right-click on the review element, switch to the Network bar, and check perserve log.
Find the url of m.weibo.cn (or other cookies) in the left name bar, find COOKIE in the right response header, and copy and paste it into the code.
main_spider.py code
# _*_ coding: utf-8 _*_ import sys import os from bs4 import BeautifulSoup # Beautiful Soup is a python reptile Library import requests # Network Request Library import time from lxml import etree # python parsing library, supporting HTML, XML, XPath parsing from urllib.request import urlretrieve # Used for picture download # Change to your own user_id and cookie user_id = YOUR_ID cookie = {"Cookie": "YOUR_COOKIE"} # Initial url url = 'http://weibo.cn/%d/profile?page=1'%user_id # Get the html content of the initial url page, get user_id and cookie (in the response header returned) html = requests.get(url, cookies = cookie).content print ('user_id and cookie Successful reading') # html element selector selector = etree.HTML(html) # Get the total number of microblog pages of this user through xpath pageNum = int(selector.xpath('//input[@name="mp"]')[0].attrib['value']) result = "" word_count = 1 # The number of microblogs and pictures crawled image_count = 1 imgsrc_list = [] # Picture Link List print ('The number of pages on the user's microblog : ',pageNum) times = 5 one_step = int(pageNum/times) for step in range(times): if step < times - 1: i = int(step * one_step + 1) j = int((step + 1) * one_step + 1) else: i = int(step * one_step + 1) j = int(pageNum + 1) for page in range(i, j): try: # Target page url url = 'http://weibo.cn/%d/profile?page=%d'%(user_id,page) print('Crawling url : ',url) # Get the current url page microblog content lxml = requests.get(url, cookies = cookie).content selector = etree.HTML(lxml) # Get the microblog list on this page content = selector.xpath('//span[@class="ctt"]') # Travel through each microblog for each in content: # Get the text content, add result, and record the number of entries text = each.xpath('string(.)') text = "%d: "%(word_count) +text+"\n" result = result + text word_count += 1 print ('The first%d Page microblog content crawling completed'%(page)) # Instantiate the current page lxml into a soup object soup = BeautifulSoup(lxml, "lxml") # Get all picture links urllist = soup.find_all(class_='ib') # Traverse through each image url and add for imgurl in urllist: imgsrc = imgurl.get('src') imgsrc_list.append(imgsrc) image_count += 1 print ('The first%d The page image crawl is completed and the following image is obtained:\n%s'%(page,imgsrc_list)) except: print ('The first',page,'Page error') time.sleep(0.001) # Crawl per page interval print ('In progress', step + 1, 'Pause once to prevent too many visits') time.sleep(1) try: # Open the text store file and create a new one if it does not exist fo_txt = open(os.getcwd()+"/%d"%user_id+".txt", "w") result_path = os.getcwd() + '/%d' % user_id+".txt" print('The path of content text storage in microblog is :',result_path) fo_txt.write(result) # Write the result to a file print('Climbing success!\n The user's microblog content:\n\n%s\n Text storage path is%s' % (result,result_path)) except: print ('Failure to save text content on microblog') if not imgsrc_list: print ('There are no pictures in the user's original microblog') else: # Picture Storage Folder Path picdir=os.getcwd()+'/weibo_image'+str(user_id) print(picdir) if os.path.exists(picdir) is False: os.mkdir(picdir) # If not, build a new one img_index = 1 # Traverse pictures for imgurl in imgsrc_list: # Picture Local Storage Path img_path = picdir + '/%s.jpg' % img_index print('Being preserved',img_path) # Download pictures to local locations urlretrieve(imgurl, img_path) img_index += 1 print('The user's microblog picture download completed! Share%d Picture, store folder %s'%(img_index,picdir))
Operating screenshots:
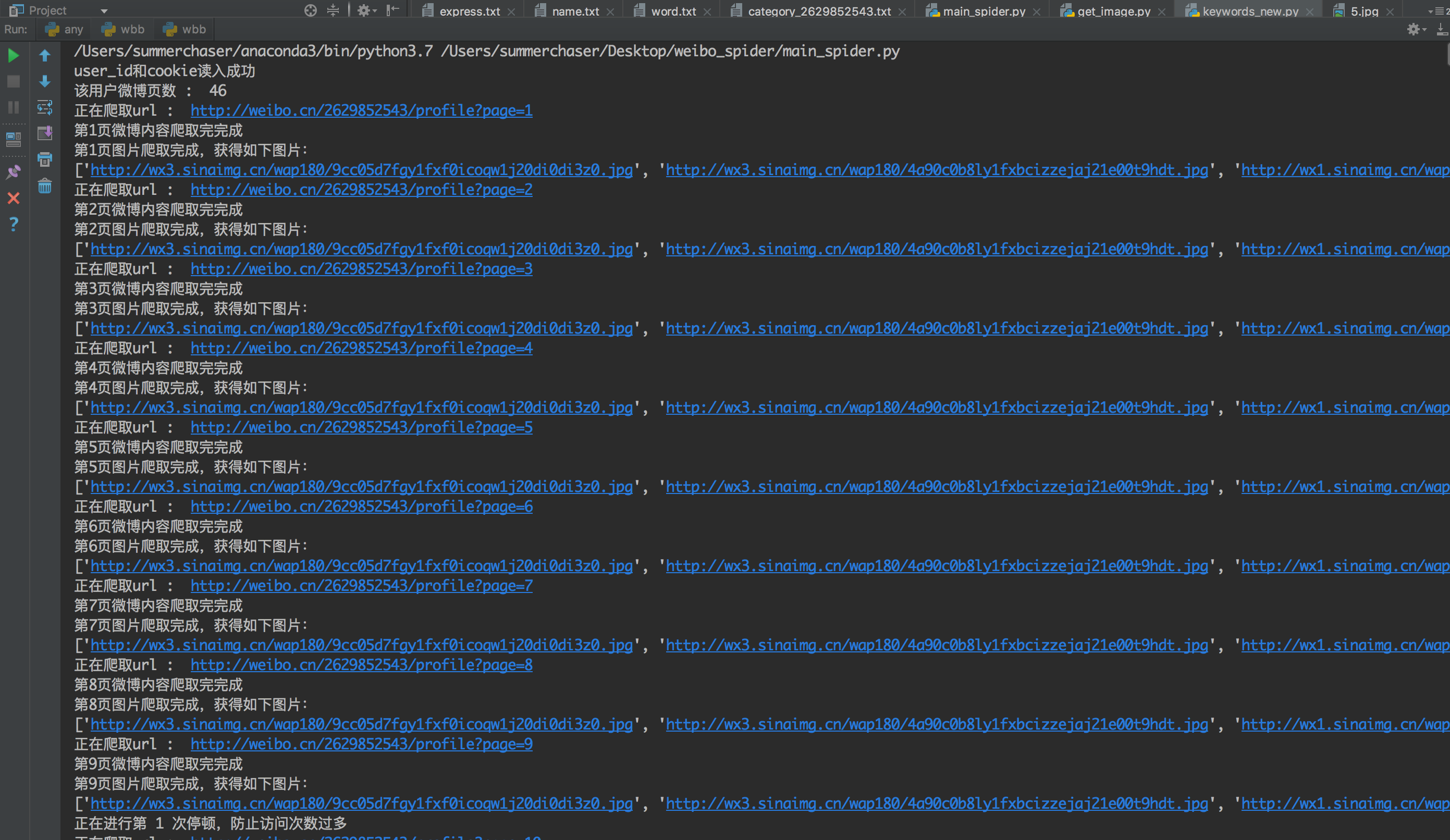
The crawled microblog content files will be put into the corresponding txt files of users in the project directory (automatic generation).
Place the image under the corresponding weibo_image file.