Crawler background
The original plan continued to write about the crawler of mobile APP, and found that the night God simulator was always stuck, lazy, and did not want to find the reason. Haha, so I went on to write the following blog, starting with 50 articles, I would like to write several python crawler operations, that is, using python 3 to achieve some small tools through the crawler.
Python 3 VIP Video Downloader
This kind of software or website is everywhere, that is, watching VIP videos of charging websites online. As long as you can play search engines or a programmer, you basically know that although it has been blocked all the time, somebody will drill holes where you can make money. Today, what we want to achieve is to download TS videos from Python through other people's API s and go to Baidu to find out what TS videos are.
Find the relevant interface
I random search, that is a lot of copyright issues, do not put the relevant address, of course, in the code will appear for a while.
I found this interface should be relatively stable at present, and it is still updated.
I took a look at the page logic that he implemented mainly through three API s as a whole.
First you go to Youku, Tencent and IQIYI to find a VIP video address. This is optional.
I found a biography of Ye Wen.
http://v.youku.com/v_show/id_XNDA0MDg2NzU0OA==.html?spm=a2h03.8164468.2069780.5
Several steps to write code
Test the playback address in the browser to get the line playback data
http://y.mt2t.com/lines?url=https://v.qq.com/x/cover/5a3aweewodeclku/b0024j13g3b.html

In the source code of the page, please note that the developer tool can be opened directly by pressing the shortcut F12, the right key has been locked.
In the source code, find the real call address
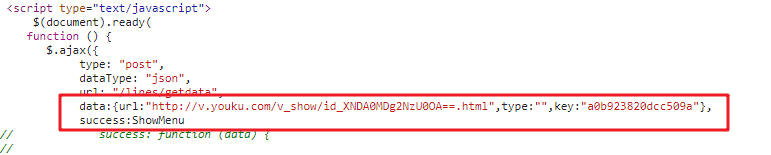
So, you need to match the key s first. It's very simple, just use regular expressions.
import requests
import re
class VIP(object):
def __init__(self):
self.api = "http://y.mt2t.com/lines?url="
self.url = "http://v.youku.com/v_show/id_XNDA0MDg2NzU0OA==.html?spm=a2h03.8164468.2069780.5"
def run(self):
res = requests.get(self.api+self.url)
html = res.text
key = re.search(r'key:"(.*?)"',html).group(1)
print(key)
if __name__ == '__main__':
vip = VIP()
vip.run()Once you get the key, you can get the playback address. After analysis, you can also know that the interface is
Request URL: http://y.mt2t.com/lines/getdata Request Method: POST
Then you just need to write it.
import requests
import re
import json
class VIP(object):
def __init__(self):
self.api = "http://y.mt2t.com/lines?url="
self.post_url = "http://y.mt2t.com/lines/getdata"
self.url = "http://v.youku.com/v_show/id_XNDA0MDg2NzU0OA==.html?spm=a2h03.8164468.2069780.5"
def run(self):
res = requests.get(self.api+self.url)
html = res.text
key = re.search(r'key:"(.*?)"',html).group(1)
return key
def get_playlist(self):
key = self.run()
data = {
"url":self.url,
"key":key
}
html = requests.post(self.post_url,data=data).text
dic = json.loads(html)
print(dic)
if __name__ == '__main__':
vip = VIP()
vip.get_playlist()The above code gives you the following data set

This data set needs to be parsed to get the playback address. Note that there is another interface that we need to get through.
Request URL: http://y2.mt2t.com:91/ifr/api Request Method: POST
The parameters are as follows
url: +bvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk+SpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6+LAY= type: m3u8 from: mt2t.com device: up: 0
All parameters of this API are decomposed from the data set just obtained.
Extract the URL in the result set above
http://y2.mt2t.com:91/ifr?url=%2bbvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk%2bSpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6%2bLAY%3d&type=m3u8
To decompose this URL, you need to know which symbols are specifically coded in general.
Both case and case are possible.
| Symbol | Special coding |
|---|---|
| + | %2d |
| / | %2f |
| % | %25 |
| = | %3d |
| ? | %3F |
| # | %23 |
| & | %26 |
So the code is as follows
def url_spilt(self):
url = "http://y2.mt2t.com:91/ifr?url=%2bbvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk%2bSpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6%2bLAY%3d&type=m3u8"
url = url.split("?url=")[1].split("&")[0].replace("%2b","+").replace("%3d","=").replace("%2f","/")
print(url)Next, it's easier to get type
Just decide whether the following type = is in the string and intercept it.
The code intercepted by url is as follows
def url_spilt(self,url):
#url = "http://y2.mt2t.com:91/ifr?url=%2bbvqT10xBsjrQlCXafOom96K2rGhgnQ1CJuc5clt8KDHnjH75Q6BhQ4Vnv7gUk%2bSpJYws4A93QjxcuTflk7RojJt0PiXpBkTAdXtRa6%2bLAY%3d&type=m3u8"
url_param = url.split("?url=")[1].split("&")[0].replace("%2b","+").replace("%3d","=").replace("%2f","/")
if "type=" in url:
type = url.split("type=")[1]
else:
type = ""
return url_param,typePerfecting the get_playlist function, the final code is as follows
def get_playlist(self):
key = self.run()
data = {
"url":self.url,
"key":key
}
html = requests.post(self.post_url,data=data).text
dic = json.loads(html)
for item in dic:
url_param, type = self.url_spilt(item["Url"])
res = requests.post(self.get_videourl,data={
"url":url_param,
"type":type,
"from": "mt2t.com",
"device":"",
"up":"0"
})
play = json.loads(res.text)
print(play)After running, I get the following tips, the most important of which is m3u8, which has been achieved and completed the task.
