Typically, programs are programmed in IDE, then packaged as jar packages, and submitted to the cluster. The most commonly used method is to create a Maven project to manage the dependencies of jar packages using Maven.
1. Generating jar packages for WordCount
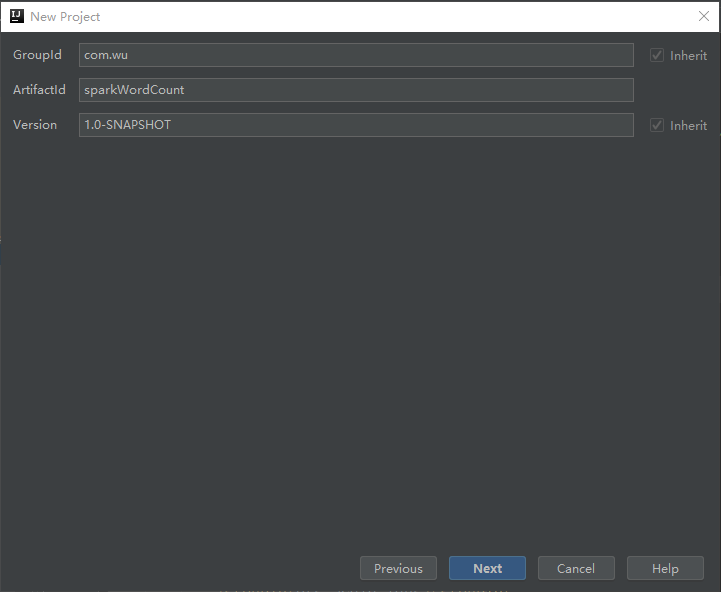
1. Open IDEA, File New Project Maven Next Fill in Groupld and Artifact Next Finish
2. Configure Maven's pom.xml (after configuring pom.xml, click Enable Auto-Import):
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bie</groupId>
<artifactId>sparkWordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.10.6</scala.version>
<scala.compat.version>2.10</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.wu.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Note: The Hadoop version needs to be modified here
3: Modify src/main/java and src/test/java to src/main/scala and src/test/scala respectively, which are consistent with the configuration in pom.xml ();
Operation: java Refactor Rename
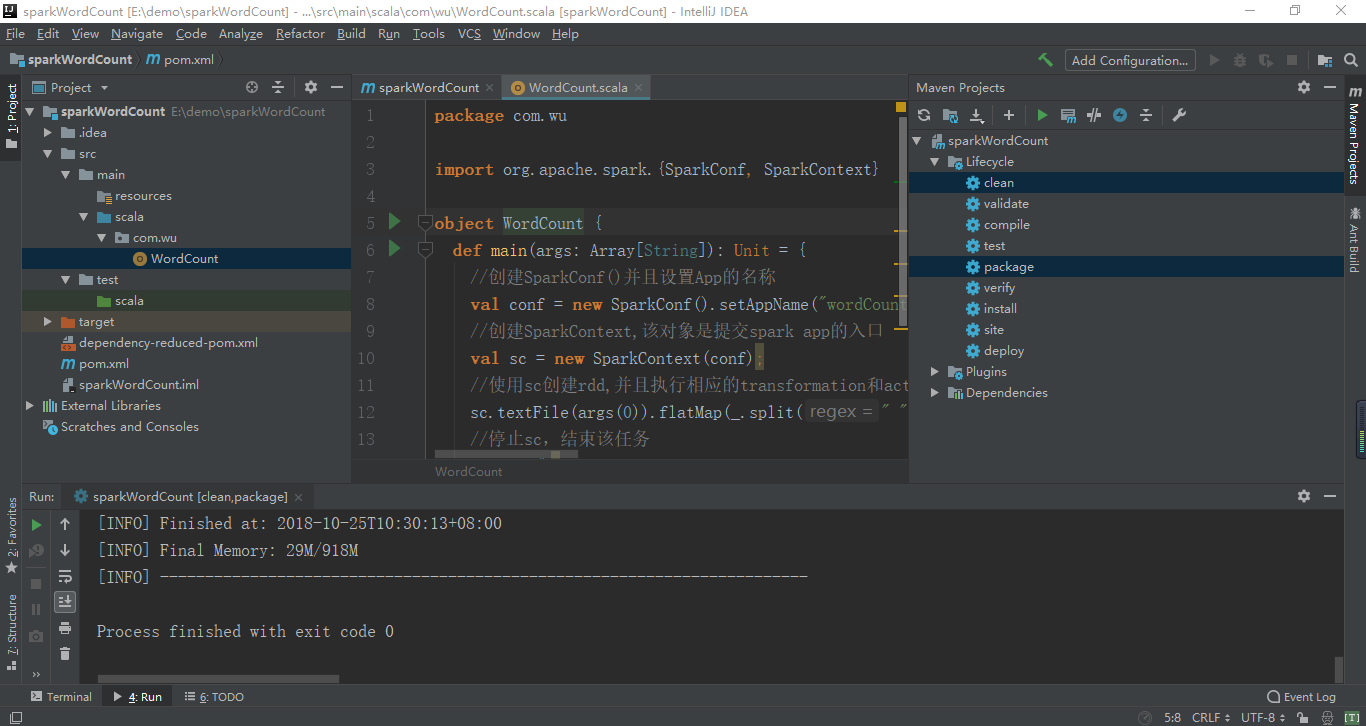
4: Create a new com.bie package and a new scala class with Object type. The spark Program is as follows:
package com.wu
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//Create SparkConf() and set the name of App
val conf = new SparkConf().setAppName("wordCount");
//Create SparkContext, which is the entry to submit spark app
val sc = new SparkContext(conf);
//Create rdd with sc and execute corresponding transformation s and action s
sc.textFile(args(0)).flatMap(_.split(" ")).map((_ ,1)).reduceByKey(_ + _,1).sortBy(_._2,false).saveAsTextFile(args(1));
//Stop sc and end the task
sc.stop();
}
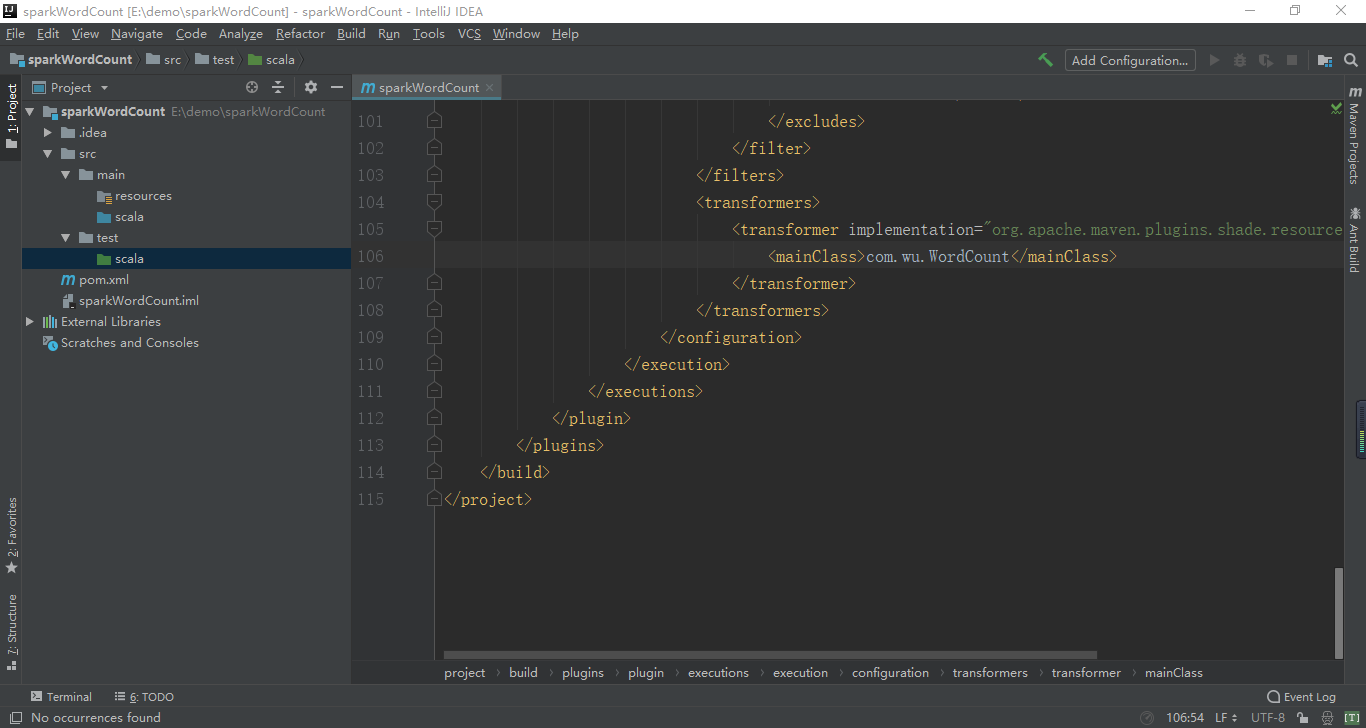
}5. Modify mainClass in pom.xml to correspond to its own classpath:
6. Use Maven Packaging: Click the Maven Project option on the right side of IDEA, click Lifecycle, select clean and package, and then click Run Maven Build:
Waiting for compilation to complete, select the jar package that compiled successfully, target/sparkWordCount-1.0-SNAPSHOT.jar
Two, operation
1. Open xshell, file new connection

Enter the username and password and establish the connection.
2. Use Xftp to create a new file transfer (Ctrl+Alt+F) and drag the newly generated jar package and WordCount to the / home/hdfs directory
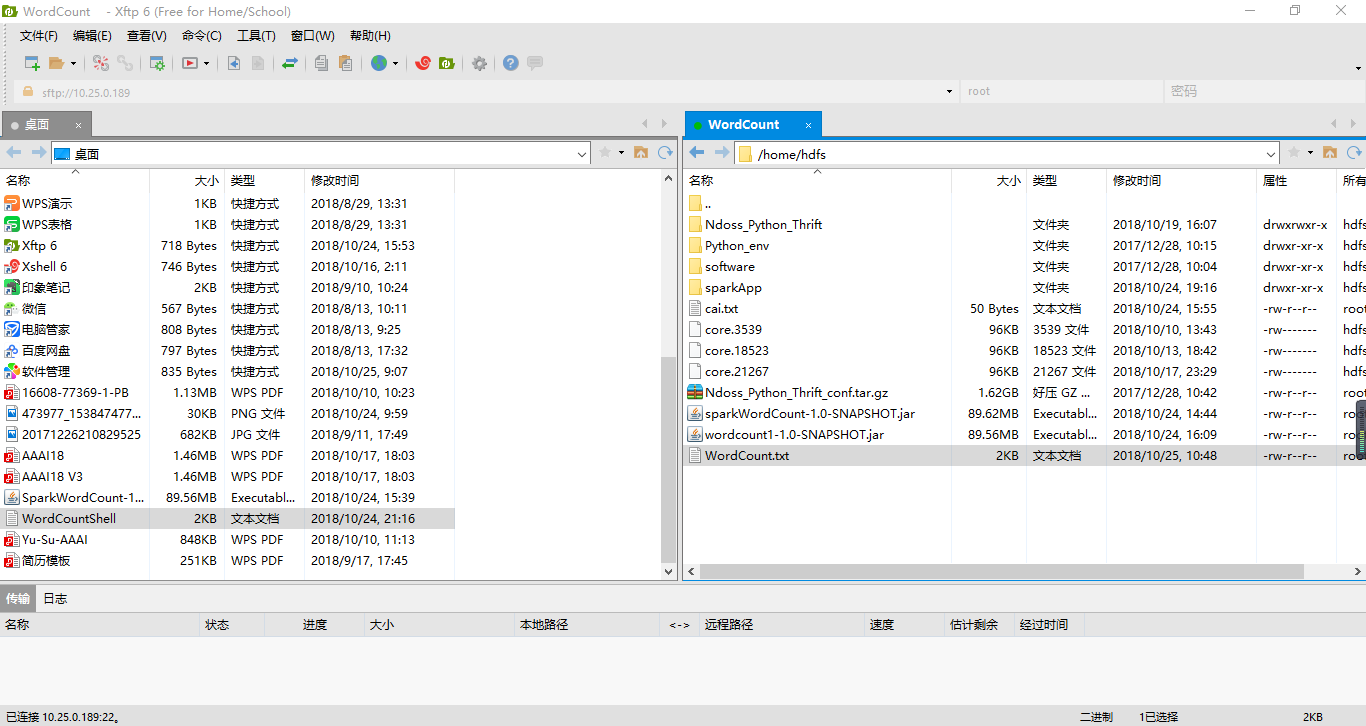
3. Upload WordCount.txt to hdfs system using X shell
Switch to hdfs user: [root@data6~]# Su hdfs
To the bin directory of spark: [hdfs@data6 root]$cd/home/hdfs/software/spark/bin
New input folder in hdfs system: Hadoop fs-mkdir/input
Check to see if the new is successful: [hdfs@data6 bin]$cd/home/hdfs/software/hadoop/bin] # Go to this directory
[hdfs@data6 bin]$ ./hadoop fs -ls /
Upload the txt file to the input folder: [hdfs@data6 root]$cd/home/hdfs/software/spark/bin* # Return to the directory
[hdfs@data6 bin]$ hadoop fs -put /home/hdfs/WordCount.txt /input
Check to see if the upload was successful: [hdfs@data6 bin]$cd/home/hdfs/software/hadoop/bin] # Go to this directory
[hdfs@data6 bin]$ ./hadoop fs -ls /input
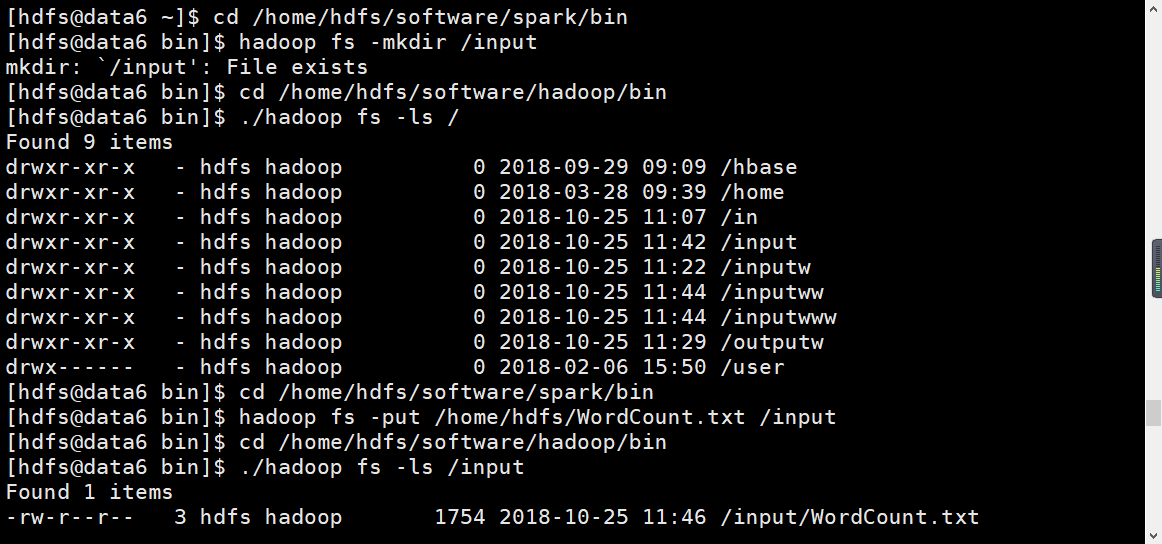
Return to hdfs user root directory: cd ~
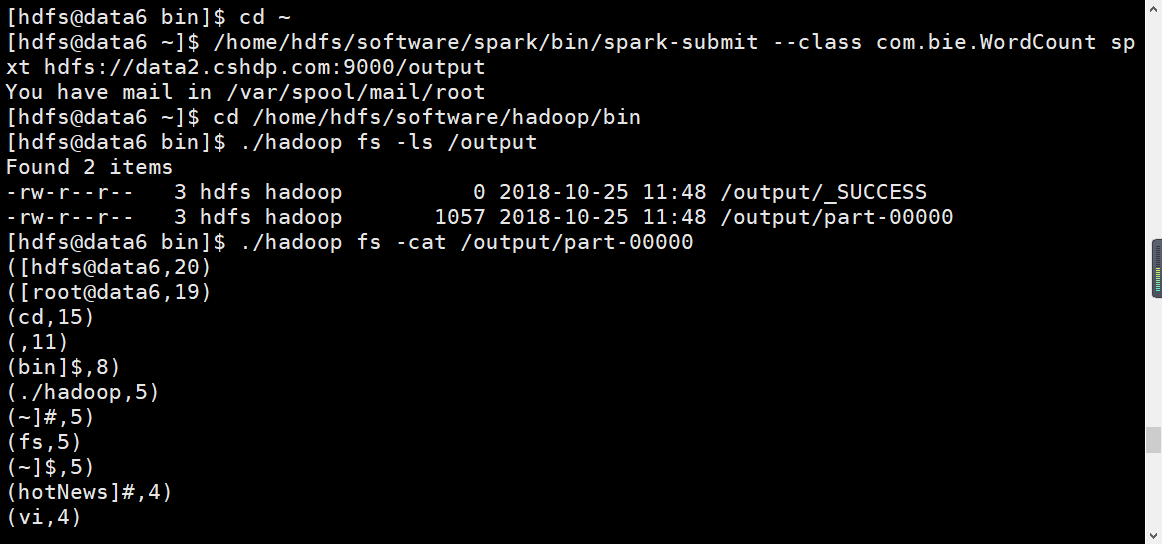
Submit Spark applications with the spark-submit command: [hdfs@data6~]$/home/hdfs/software/spark/bin/spark-submit--class com.bie.WordCount sparkWordCount-1.0-SNAPSHOT.jar hdfs://data2.cshdp.com:9000/input/dnt.txt hdfs://data2.cshp.com:9000/output:
View the results: [hdfs@data6 bin]$cd/home/hdfs/software/hadoop/bin] # Go to this directory
[hdfs@data6 bin]$ ./hadoop fs -ls /output
[hdfs@data6 bin]$. / Hadoop fs-cat/output/part-00000 View file content