Preface
Spark is a very popular big data processing engine. Data scientists use Spark and the related ecological big data suite to complete a large number of rich scene data analysis and mining. Spark has gradually become the industry standard in the field of data processing. However, Spark itself is designed to use static resource management. Although Spark also supports dynamic resource managers like Yarn, these resource managers are not designed for dynamic cloud infrastructure and lack solutions in speed, cost, efficiency and other fields. With the rapid development of Kubernetes, data scientists began to consider whether Spark could be combined with Kubernetes'elasticity and cloud-oriented primitiveness. In Park 2.3, the Resource Manager adds native Kubernetes support, and in this series we will show you how to use Spark for data analysis in clusters in a more Kubernetes way. This series does not require developers to have rich experience in using Spark, and will be interspersed with explanations of the Spark features used in the gradual deepening of the series.
Build Playground
Many developers are discouraged by the complexity of the installation process when they come into contact with Hadoop. In order to reduce the learning threshold, this series will simplify the installation process by using spark-on-k8s-operator as Playground. Spark-on-k8s-operator, as its name implies, is designed to simplify the operation of Spark. If a developer does not know much about the operator, he or she can search for it and understand what the operator can do to help you quickly grasp the key points of the spark-on-k8s-operator.
Before explaining the internal principle, we first build up the environment and run through the whole running environment through a simple demo.
1. Install spark-on-k8s-operator
The official documentation is installed through Helm Chart. Because many developers'environments cannot connect to google's repo, we install it here through standard yaml.
## Download repo git clone git@github.com:AliyunContainerService/spark-on-k8s-operator.git ## Install crd kubectl apply -f manifest/spark-operator-crds.yaml ## Service Account and Authorization Policy for Installing operator kubectl apply -f manifest/spark-operator-rbac.yaml ## Service Account and Authorization Policy for Installing spark Tasks kubectl apply -f manifest/spark-rbac.yaml ## Install spark-on-k8s-operator kubectl apply -f manifest/spark-operator.yaml
Verify installation results
Under the stateless application in the spark-operator namespace, you can see a running spark operator. At this time, the component has been installed successfully. Next, we run a demo application to verify whether the component works properly.
2. Demo validation
When learning Spark, the first task we ran was the example of the PI operation described in the official documentation. Today we're going to run it again in Kubernetes, another way.
## Next spark-pi task kubectl apply -f examples/spark-pi.yaml
Once the task is successfully posted, the status of the task can be observed from the command line.
## Query task kubectl describe sparkapplication spark-pi ## Task results Name: spark-pi Namespace: default Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"sparkoperator.k8s.io/v1alpha1","kind":"SparkApplication","metadata":{"annotations":{},"name":"spark-pi","namespace":"defaul... API Version: sparkoperator.k8s.io/v1alpha1 Kind: SparkApplication Metadata: Creation Timestamp: 2019-01-20T10:47:08Z Generation: 1 Resource Version: 4923532 Self Link: /apis/sparkoperator.k8s.io/v1alpha1/namespaces/default/sparkapplications/spark-pi UID: bbe7445c-1ca0-11e9-9ad4-062fd7c19a7b Spec: Deps: Driver: Core Limit: 200m Cores: 0.1 Labels: Version: 2.4.0 Memory: 512m Service Account: spark Volume Mounts: Mount Path: /tmp Name: test-volume Executor: Cores: 1 Instances: 1 Labels: Version: 2.4.0 Memory: 512m Volume Mounts: Mount Path: /tmp Name: test-volume Image: gcr.io/spark-operator/spark:v2.4.0 Image Pull Policy: Always Main Application File: local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar Main Class: org.apache.spark.examples.SparkPi Mode: cluster Restart Policy: Type: Never Type: Scala Volumes: Host Path: Path: /tmp Type: Directory Name: test-volume Status: Application State: Error Message: State: COMPLETED Driver Info: Pod Name: spark-pi-driver Web UI Port: 31182 Web UI Service Name: spark-pi-ui-svc Execution Attempts: 1 Executor State: Spark - Pi - 1547981232122 - Exec - 1: COMPLETED Last Submission Attempt Time: 2019-01-20T10:47:14Z Spark Application Id: spark-application-1547981285779 Submission Attempts: 1 Termination Time: 2019-01-20T10:48:56Z Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SparkApplicationAdded 55m spark-operator SparkApplication spark-pi was added, Enqueuing it for submission Normal SparkApplicationSubmitted 55m spark-operator SparkApplication spark-pi was submitted successfully Normal SparkDriverPending 55m (x2 over 55m) spark-operator Driver spark-pi-driver is pending Normal SparkExecutorPending 54m (x3 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is pending Normal SparkExecutorRunning 53m (x4 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is running Normal SparkDriverRunning 53m (x12 over 55m) spark-operator Driver spark-pi-driver is running Normal SparkExecutorCompleted 53m (x2 over 53m) spark-operator Executor spark-pi-1547981232122-exec-1 completed
At this time, we found that the task has been successfully executed. Looking at the log of this Pod, we can calculate the final result is Pi is roughly 3.1470557352786765. So far, on Kubernetes, we have run through the first Job. Next, let's go into details about what we have done in this wave of operations.
Analysis of Spark Operator's Infrastructure
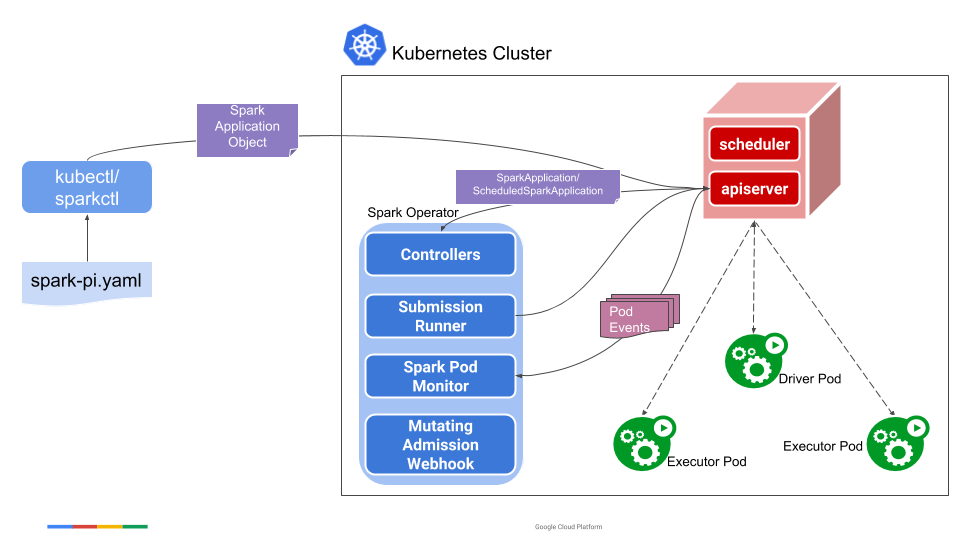
This diagram is a flow chart of Spark Operator. In the first step of the above operation, the blue Spark Operator at the center of the diagram is actually installed into the cluster. Spark Operator itself is a CRD Controller and a Mutating Admission Web hook Controller. When we issue the spark-pi template, it will be converted into a CRD object named Spark Application, and then Spark Operator will listen to Apiserver, parse the Spark Application object, turn it into a spark-submit command and submit it it. Driver Pod is a mirror encapsulating Spark Jar in a simple way. If it is a local task, it is executed directly in Driver Pod; if it is a cluster task, it is executed by regenerating Exector Pod from Driver Pod. When the task is over, you can view the run log through Driver Pod. In addition, Spark Operator dynamically attach es a Spark UI to Driver Pod during task execution. Developers who want to view task status can view task status through this UI page.
Last
In this paper, we discuss the original design intention of Spark Operator, how to quickly build a Playground of Spark Operator and the basic architecture and process of Spark Operator. In the next article, we will go deep into the interior of Spark Operator and explain its internal implementation principles and how to integrate more seamlessly with Spark.