Catalog
0. Write in front
1. Analysis Page
2. Get the page source code
3. Analytical data
4. Data Storage and Export
4.1 Data Storage
4.2 Data Export
5.pandas Implements Export
6. Object-Oriented Encapsulation
0. Write in front
Target page
http://i.dxy.cn/profile/yilizhongzi
objective
Click the information on the user's home page of the Clove Garden, which is shown in the following fields:

Crawl field graph
That is to extract these data from the user's home page, then we start to fight!
1. Analysis Page
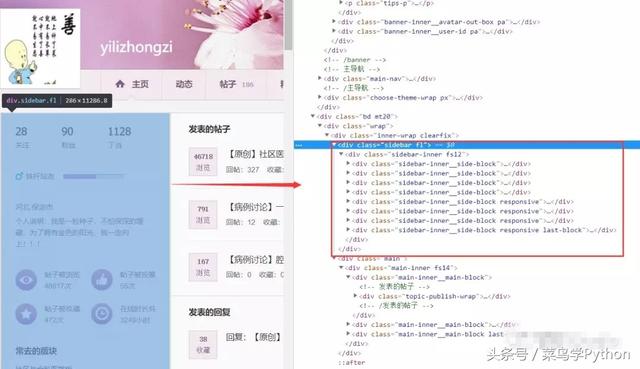
Analysis Page Diagram
The information we need to crawl is the sidebar information in the above figure. Its corresponding source code is shown in the red box in the figure.
thinking
Step 1: Get the page source code
Step 2: Parse the corresponding data through xpath and store it in dictionary format
Step 3: Store in MongoDB database and export csv files using visualization tools
Step 4: Store it in excel (or csv file)
2. Get the page source code
def get_html(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
req = requests.get(self.url, headers=headers).text
# print(req)
return req3. Analytical data
xpath analytical method
Take the following practical examples:
Google Browser right-click check, page analysis source code, find the following div, and then find that class= "follow-fans clearfix" contains these three concerns, fans, Tingdang related information.
Then the corresponding data can be obtained by xpath parsing. Specific xpath grammar, please refer to the online information, here do not explain in detail. Add comments only to the corresponding statement. Look at the notes carefully!!!
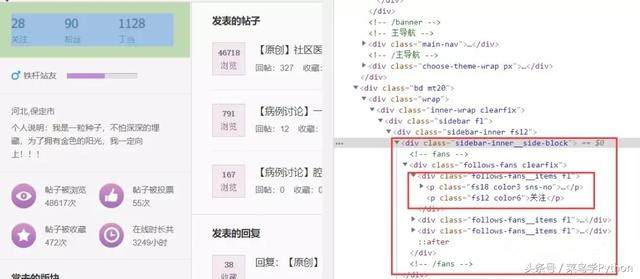
Element extraction map
'''
The text() attribute of all the P Tags below div satisfying class value, because there is a tag under the first p tag mentioned above. All that is taken here is the attention/fans/ding-dang strings, each corresponding value 28/90/1128, which is parsed by further positioning to a tag. See the second line of code.
'''
force_fan_dd_key = selector.xpath('//div[@class="follows-fans clearfix"]//p/text()')
force_fan_dd_value = selector.xpath('//div[@class="follows-fans clearfix"]//p/a/text()')Here's how to encapsulate access to user information
import requests
from lxml import etree
def get_UserInfo(self):
raw_html = self.get_html()
selector = etree.HTML(raw_html)
key_list = []
value_list = []
force_fan_dd_key = selector.xpath('//div[@class="follows-fans clearfix"]//p/text()')
force_fan_dd_value = selector.xpath('//div[@class="follows-fans clearfix"]//p/a/text()')
for each in force_fan_dd_key:
key_list.append(each)
for each in force_fan_dd_value:
value_list.append(each)
UserInfo_dict = dict(zip(key_list, value_list)) #Merge two list s into dict
# print(UserInfo_dict) #{Focus':'28','Fans':'90','Dingdang':'1128'}
user_home = selector.xpath('//p[@class="details-wrap__items"]/text()')[0]
user_home = user_home.replace(',', '') #Remove commas, otherwise use MongoDB visualization tool to export csv file error!
# print(user_home)
UserInfo_dict['address'] = user_home
user_profile = selector.xpath('//p[@class="details-wrap__items details-wrap__last-item"]/text()')[0]
UserInfo_dict['Motto'] = user_profile
# print(UserInfo_dict)
#Posts are browsed
article_browser = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-topic fl"]/p/text()')
UserInfo_dict[article_browser[0]] = article_browser[1]
#Posts voted
article_vote = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-vote fl"]/p/text()')
UserInfo_dict[article_vote[0]] = article_vote[1]
#Posts are collected
article_collect = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-fav fl"]/p/text()')
UserInfo_dict[article_collect[0]] = article_collect[1]
#Online duration
onlie_time = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-time fl"]/p/text()')
UserInfo_dict[onlie_time[0]] = onlie_time[1]
# print(UserInfo_dict)
return UserInfo_dict4. Data Storage and Export
4.1 Data Storage
import pymongo MONGO_URI = 'localhost' MONGO_DB = 'test' #Defining databases MONGO_COLLECTION = 'dxy' #Define database tables def __init__(self, user_id, mongo_uri, mongo_db): self.url = base_url + user_id #This line of code has nothing to do with data storage self.client = pymongo.MongoClient(mongo_uri) self.db = self.client[mongo_db] def Save_MongoDB(self, userinfo): self.db[MONGO_COLLECTION].insert(userinfo) self.client.close()
MongoDB Visualization Tool: MongoDB Compass Community

MongoDB Visualization Tool Diagram
After installation, every time you open it, you will be prompted to connect to the database. Here is no change of any information, just point CONNECT directly.
Note the difference: Collection is the table of the database! The following figure is the dxy table in the test database.

MongoDB Stores Result Diagrams
4.2 Data Export
Select Collect - > Export Collection in the upper left corner, then pop up the box of the following figure, select the export format and storage file path, save!
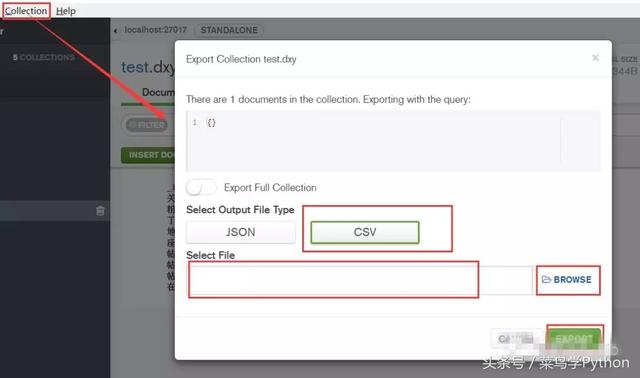
Derived results

MongoDB export result graph
5.pandas Implements Export
import pandas as pd
def Sava_Excel(self, userinfo):
key_list = []
value_list = []
for key, value in userinfo.items():
key_list.append(key)
value_list.append(value)
key_list.insert(0, 'User name') #Increase user list
value_list.insert(0, user) #Increase the username
#Export using pandas
data = pd.DataFrame(data=[value_list], columns=key_list)
print(data)
'''
//Represents naming a csv file with a user name, removing the index column serialized by DataFame (which means index=False), and encoding it in utf-8.
//Prevent Chinese scrambling.
//Note: Before exporting CSV files using to_csv method, it is necessary to serialize pandas'DataFrame first.
'''
data.to_csv('./' + user + '.csv', encoding='utf-8', index=False)6. Object-Oriented Encapsulation
Finally, the above code is encapsulated with the object-oriented idea.