Java parsing OFFICE(word,excel,powerpoint) and PDF implementation scheme and bit-by-bit sharing in development
Here, I share my experience and feelings before writing this article. All my feelings are condensed into one word: pit. If there are two words, it is "huge pit"=> because this demand is not the same at the beginning, and listen to me ramble along:
At the beginning, the client talked with us about uploading office and PDF, parsing such files into HTML format, calling built-in server on the APP side and playing them directly with html.
Experience one month, two months, three months ~ uuuuuuuuuuuuu
At the stage of requirement development, it is found that this is a pit... According to the meaning of requirement rules, the whole is done as a function, the technical difficulty will be calculated, and according to the estimated working hours, it is difficult to make the required appearance of requirement rules (too many defects! )
Then one week, one week, another week.
When the requirements are confirmed, the customer says, "We don't ask you to parse these documents. We just ask you to upload them as a source file. Click on the APP side and you can choose to call a third-party application to open it. And that's what we need from the beginning."
After hearing this, I burst into tears. If the business confirms it at the beginning, why waste so much time and energy to go around the boss... uuuuuuuuuuuuuuuuu * /
Needs go round and round again. As a person who has experienced them, I now sum up the endless pits in this need:
A > There are many demos in the open source community, which have many drawbacks, such as artistic words, pictures, formulas, color styles, video and audio that cannot be parsed in office.
B > Objects that can be parsed do not work very well, such as word and ppt's own typesetting disorder, the custom format in excel cells has become a number ~and so on.
C > Open source community data is not complete, resulting in different document types need to be parsed in different ways, such as word parsing with docx4j, excel parsing with poi brings huge amount of code.
D > Because the parsing effect of the code itself is not very good, the modified scheme needs to process the source file into other forms before uploading, such as pdf needs to be cut into pictures, ppt needs to be converted into video or pictures, so that the way to realize the requirement becomes semi-automatic.
E>word parsing with docx4j is a big problem. The parsing efficiency of documents with more than 5MB or complex contents is too time-consuming and low. The second problem is that Exel with large amount of poi parsing data (e.g. > 1000 lines) is prone to memory overflow and difficult to control.
F > The working hours are too short, only 15 days. Overtime (), contractor, salary increase!!! E = angry e = angry e = angry e = angry e = angry e = angry e = angry e = o'_') _
The above Tucao is over, the final result will be displayed.
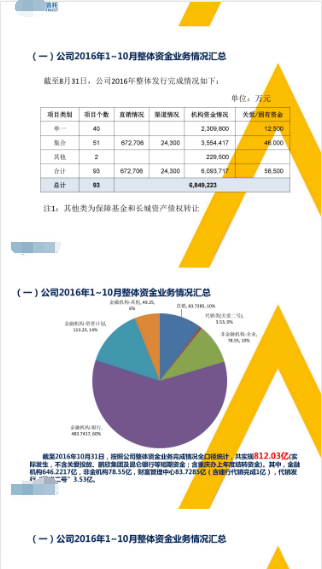

From left to right, the effect of parsing html by pdf, ppt, word and excel is in turn. Since some parts of Figures 1 and 2 in the development protocol are smeared, and the above is only shown by browser simulating mobile phone, the effect is rough. I'm sorry here to say that the effect of parsing html by pdf, ppt, word and excel is very rough.
Here is my final idea of implementation:
A > Word documents are divided into two formats (03 edition) doc and (07 edition) docx. Because doc belongs to the format that will be eliminated and is implemented in one step to facilitate the use of docx4j, doc format documents are not considered.
B > Like Word, excel does not consider the conversion of the old format. The solution is to use a third-party Demo to implement it. The specific technology involved is poi.hssf.
C > PowerPoint (ppt) Because there are many built-in objects, in order to ensure the user's experience, my plan is to export ppt directly to mp4 or image upload (zip package) and then wrap it into html with code.
D > For pdf, there is also no good Demo to achieve html, so like ppt, it is packaged and uploaded in the form of software into pictures, and then packaged into HTML with code.
First, show the code of word parsing:
(Code snippet 1)
1 public static void Word2Html() throws FileNotFoundException, Docx4JException{
2 //Need to log4j Internal configuration docx4j Level
3 WordprocessingMLPackage wmp = WordprocessingMLPackage.load(new File("C:\\Users\\funnyZpC\\Desktop\\Test\\word.docx"));
4 Docx4J.toHTML(wmp, "C:\\Users\\funnyZpC\\Desktop\\result\\wordIMG", "wordIMG", new FileOutputStream(new File("C:\\Users\\funnyZpC\\Desktop\\result\\word.html")));
5 }
(Code snippet 2)
1 public ProcessFileInfo processDOCX(File file,String uploadPath)throws Exception{
2 String fileName=file.getName().substring(0,file.getName().lastIndexOf("."));//Get the file name
3 WordprocessingMLPackage wmp = WordprocessingMLPackage.load(file);//Loading source files
4 String basePath=String.format("%s%s%s", uploadPath,File.separator,fileName);//Base address
5 FileUtils.forceMkdir(new File(basePath));//create folder
6 String zipFilePath=String.format("%s%s%s.%s", uploadPath,File.separator,fileName,"ZIP");//The path to the final generated file
7 Docx4J.toHTML(wmp, String.format("%s%s%s", basePath,File.separator,fileName),fileName,new FileOutputStream(new File(String.format("%s%s%s", basePath,File.separator,"index.html"))));//analysis
8 scormService.zip(basePath, zipFilePath);//Compressed package
9 FileUtils.forceDelete(new File(basePath));//Delete temporary folders
10 file.delete();//Parse completed, delete the original docx file
11 return new ProcessFileInfo(true,new File(zipFilePath).getName(),zipFilePath);//Return information about the target file
12 }
The code needed to parse the word(docx) document is so simple that only two lines of code are needed (code fragments 1,3,4,2 lines). More than two lines of code (code fragments 2) are actually developed. It is recommended to compare the fragments. At the same time, because the project may be deployed in linux system, File.separator is recommended to replace the "/" or "\" path separator; at the same time, four parameters of toHtml method need to be explained. Number = = >
Docx4j.toHtml (Wordprocessing MLPackage instantiated object loading source docx file, base directory storing parsing results (html and pictures), folder name storing pictures (under base directory), output main HTML output stream object);
The following is a list of output results:
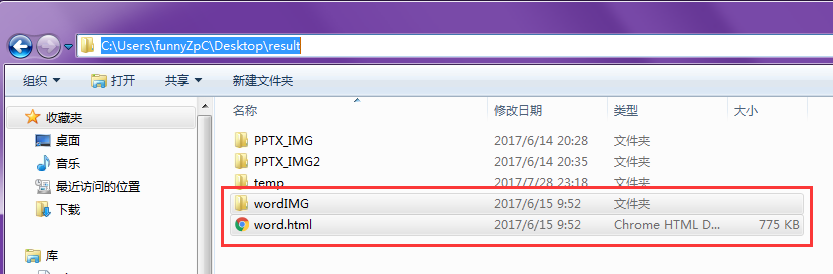
Because docx4j has more log s, the output file will be prompted by default Demo test as follows:

To hide this message, set the debug level of docx4j. The solution is to add docx4j message level ERROR to the log4j.properties of the actual project, such as:

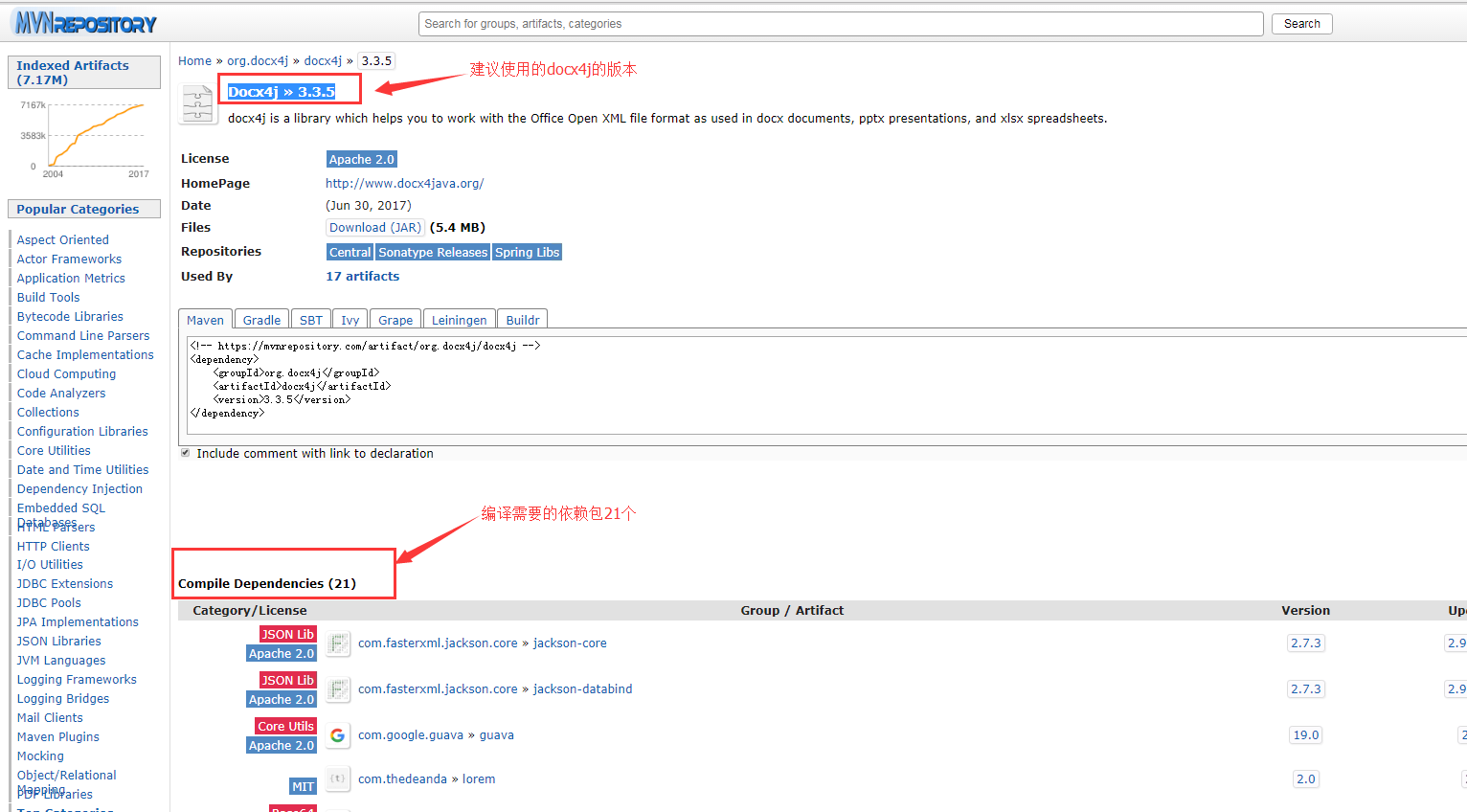
If you use Maven to manage projects, add docx4j dependency directly into pom.xml, and if you need to configure docx4j and its dependency packages manually, you must pay attention to the correspondence between the dependency packages and the current version of docx4j (recommend 3.3.5 docx4j, the parsing effect will be better! Otherwise, there are all kinds of faults. Here are some illustrations of maven warehouse. If you need to configure dependencies manually, you must Click in Look at:
The following code is part of Excel's code snippet for parsing word (incomplete code, please email me if necessary):
(Code snippet 1)
View Code
1 /** 2 * 3 * @param file Source file: c://xx//xx.xlsx 4 * @param uploadPath Base directory address 5 * @return 6 * @throws Exception 7 */ 8 public ProcessFileInfo processXLSX(File file,String uploadPath)throws Exception { 9 List<String> sheets=Excel2HtmlUtils.readExcelToHtml(file.getPath()); 10 FileUtils.forceMkdir(new File(uploadPath));//create folder 11 String code=file.getName().substring(0,file.getName().lastIndexOf("."));//File name 12 String basePath=String.format("%s%s%s", uploadPath,File.separator,code); 13 FileUtils.forceMkdir(new File(basePath)); 14 File htmlFile = new File(String.format("%s%s%s", basePath,File.separator,"index.html")); 15 Writer fw=null; 16 PrintWriter bw=null; 17 //structure html file 18 try{ 19 fw= new BufferedWriter( new OutputStreamWriter(new FileOutputStream(htmlFile.getPath()),"UTF-8")); 20 bw=new PrintWriter(fw); 21 //Add headers and scalable styles 22 String head="<!DOCTYPE html><html><head><meta charset=\"UTF-8\"></head><body style=\"transform: scale(0.7,0.7);-webkit-transform: scale(0.7,0.7);\">"; 23 StringBuilder body=new StringBuilder(); 24 for (String e : sheets) { 25 body.append(e); 26 } 27 String foot="</body></html>"; 28 bw.write(String.format("%s%s%s", head,body.toString(),foot)); 29 }catch(Exception e){ 30 throw new Exception("");//Throw wrong 31 }finally{ 32 if (bw != null) { 33 bw.close(); 34 } 35 if(fw!=null){ 36 fw.close(); 37 } 38 } 39 String htmlZipFile=String.format("%s%s%s.%s",uploadPath,File.separator,file.getName().substring(0,file.getName().lastIndexOf(".")),"ZIP"); 40 //Compressed file 41 scormService.zip(basePath, htmlZipFile); 42 file.delete();//Delete Uploaded xlsx file 43 FileUtils.forceDelete(new File(basePath)); 44 return new ProcessFileInfo(true,new File(htmlZipFile).getName(),htmlZipFile); 45 }