1. 36 Kr data - written in front
Today, grabbing a news media, 36kr article content, is also to prepare for the subsequent data analysis.
36kr allows some people to see the future first, and what you are going to do today is really to grasp its past.
Website https://36kr.com/
2. 36 Kr data - Data Analysis
36kr page is a waterfall flow effect, when you constantly drop down the page, the data from the background is added, based on this, we can basically judge that it is ajax asynchronous data, just open the developer tools, you can quickly locate the desired data, let's try!
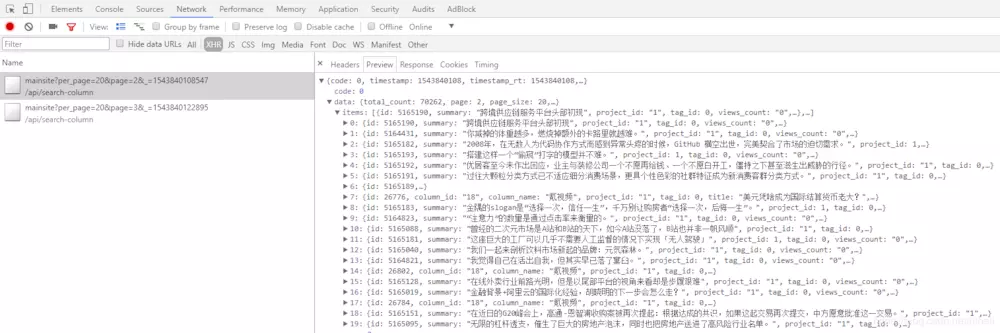
The capture links are as follows
https://36kr.com/api/search-column/mainsite?per_page=20&page=1&_=1543840108547 https://36kr.com/api/search-column/mainsite?per_page=20&page=2&_=1543840108547 https://36kr.com/api/search-column/mainsite?per_page=20&page=3&_=1543840108547 https://36kr.com/api/search-column/mainsite?per_page=20&page=4&_=1543840108547
After many attempts, we found that per_page can be extended to 300, but when the data is greater than 100, the returned data is not very ideal, so we plan to set it as 100, page is the page number, which can be repeated.
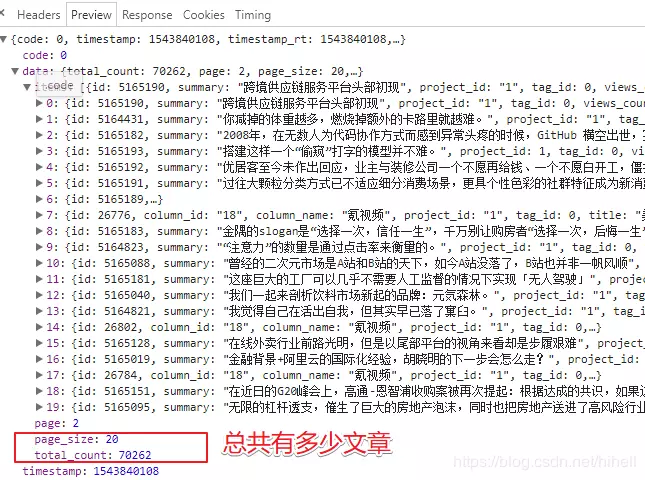
The above parameter also has a more important value, called total_count, for the total number of articles. With this parameter, we can quickly stitch out the desired page number.
3. 36 Kr data - creating scrapy project
scrapy startproject kr36
4. 36 Kr data - creating crawler entry pages
scrapy genspider Kr36 "www.gaokaopai.com" Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
5. 36 Kr data - writing url generator
The start_urls of the page is the first page of data, and then the parse function is called. In the content of the function, we get the parameter total_count.
Here, you need to note that the return data of yield is Request(), for a detailed description of him, see
https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/request-response.html
All parameter lists and parameter names are well-named and basically represent all the meanings. More importantly, url and callback
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
class Kr36Spider(scrapy.Spider):
name = 'Kr36'
allowed_domains = ['36kr.com']
start_urls = ['https://36kr.com/api/search-column/mainsite?per_page=100&page=1&_=']
def parse(self, response):
data = json.loads(response.body_as_unicode())
totle = int(data["data"]["total_count"])
#totle = 201
for page in range(2,int(totle/100)+2):
print("Crawling{}page".format(page),end="")
yield Request("https://36kr.com/api/search-column/mainsite?per_page=100&page={}&_=".format(str(page)), callback=self.parse_item)
6. 36 Kr data - parsing data
In the process of parsing data, it is found that sometimes there are missing data, so it is necessary to judge whether app_views_count, mobile_views_count, views_count, favorite_num appear in the dictionary.
Notice the Kr36Item class in the following code, which needs to be created in advance
Kr36Item
class Kr36Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
app_views_count = scrapy.Field() # APP View Quantity
mobile_views_count = scrapy.Field() # Number of mobile viewers
views_count = scrapy.Field() # PC View Quantity
column_name = scrapy.Field() # category
favourite_num = scrapy.Field() # Collection Quantity
title = scrapy.Field() # Title
published_at = scrapy.Field() # Release time
is_free = scrapy.Field() # Free or not
username = scrapy.Field()
def parse_item(self,response):
data = json.loads(response.body_as_unicode())
item = Kr36Item()
for one_item in data["data"]["items"]:
print(one_item)
item["app_views_count"] = one_item["app_views_count"] if "app_views_count" in one_item else 0# APP View Quantity
item["mobile_views_count"] = one_item["mobile_views_count"] if "mobile_views_count" in one_item else 0 # Number of mobile viewers
item["views_count"] = one_item["views_count"] if "views_count" in one_item else 0 # PC View Quantity
item["column_name"] = one_item["column_name"] # category
item["favourite_num"] = one_item["favourite_num"] if "favourite_num" in one_item else 0 # Collection Quantity
item["title"] = one_item["title"] # Title
item["published_at"] = one_item["published_at"] # Release time
item["is_free"] = one_item["is_free"] if "is_free" in one_item else 0# Free or not
item["username"] = json.loads(one_item["user_info"])["name"]
yield item
Finally, open pipelines in settings.py to write data persistence code
ITEM_PIPELINES = {
'kr36.pipelines.Kr36Pipeline': 300,
}
import os
import csv
class Kr36Pipeline(object):
def __init__(self):
store_file = os.path.dirname(__file__)+'/spiders/36kr.csv'
self.file = open(store_file,"a+",newline="",encoding="utf_8_sig")
self.writer = csv.writer(self.file)
def process_item(self, item, spider):
try:
self.writer.writerow((
item["title"],
item["app_views_count"],
item["mobile_views_count"],
item["views_count"],
item["column_name"],
item["favourite_num"],
item["published_at"],
item["is_free"],
item["username"]
))
print("Data Storage Completed")
except Exception as e:
print(e.args)
def close_spider(self,spider):
self.file.close()
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
7. 36 krypton (36kr) data - Data Acquisition
Running the above code has not done too much processing, nor has it adjusted the concurrency speed, nor has it done anti-crawling measures. Running for a while, we got about 69936 pieces of data, which is more than 300 pieces worse than the forecast. It's not a big problem. The reason is not carefully investigated.