2021SC@SDUSC
1, HBase overview
What is HBase
HBase is a database system built on HDFS, which provides high reliability, high performance, column storage, scalability and real-time reading and writing. It is mainly used to store unstructured and semi-structured loose data. HBase uses hadoop HDFS as its file storage system, Hadoop MapReduce to process massive data in HBase, and Zookeeper as its distributed collaborative service. HBase is between nosql and RDBMS. It can only retrieve data through the row key and the range of the primary key, and only supports single line transactions (complex operations such as multi table join can be realized through hive support).
Like hadoop, HBase mainly relies on horizontal expansion to increase computing and storage capacity by increasing cheap commercial servers.
HBase is implemented in java language and internally implements some compression algorithms, memory operations and Bloom filters mentioned in BigTable paper. These capabilities make HBase widely used in massive data storage and high-performance read-write scenarios. For example, Facebook has always selected HBase as the storage layer technology of the message platform since November 2010.
HBase module
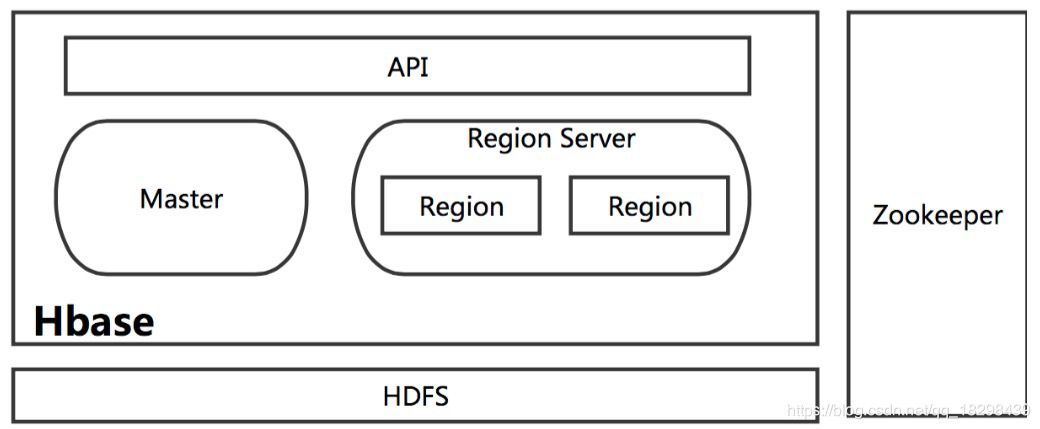
Role of related modules in HBase
- Master
HBase Master is used to coordinate multiple regional servers, detect the status of each regional server, and balance the load between regional servers. It has the functions of allocating hregon to hregon server, load balancing hregon server, discovering and redistributing failed hregon server, garbage file recycling on HDFS, and processing Schema update requests. HBase allows multiple Master nodes to coexist, but this requires the help of Zookeeper. When the working Master node goes down, other masters will take over the HBase cluster. - Region Server
For a Region server, it includes multiple regions. RegionServer is only used to manage tables and read and write operations. It can maintain the hregs assigned by HMaster, process IO requests for these hregs, and be responsible for splitting hregs that become too large during operation. - Zookeeper
For HBase, the role of Zookeeper is crucial. Firstly, Zookeeper is the HA solution of HBase Master, and Zookeeper is responsible for the registration of Region Server.
logical model
The data is stored in the form of a table. The table is composed of rows and columns. Each column is composed of an input column family. The storage unit determined by the rows and columns becomes an element. Each element saves multiple versions of the same data and is marked by a timestamp.
characteristic
1. Semi structured data:
hbase is not designed with strict morphological data, and data records may contain inconsistent columns, uncertain sizes, etc
2. Scalability:
(1) In the semi-structured logic model, the data composition is loosely coupled, which is conducive to physical loose storage;
(2) The physical model of hbase is suitable for physical loose storage, which also affects the logical model;
(3) This physical model design forces hbase to abandon some characteristics of relational database;
(4) In particular, hbase does not care about constraints in real time and does not support multiline things.
3. Mapping set of ordered mapping:
(1) Logically organize the data into a mapping set of nested mappings;
(2) In each mapping set, the data is sorted according to the key Dictionary of the mapping set.
2, HBase installation and configuration
Installing HBase under centos
-
Prepare JDK environment
Related tutorials centos installation JDK-tar.gz file. -
Download HBase
Download address HBase-2.12-bin.tar.gz file. -
Upload the file to centos host through ftp tool.
-
Enter the installation directory
cd /opt/
-
Unzip the installation files to the current directory
tar -zxvf /var/ftp/pub/hbase-2.1.2-bin.tar.gz
-
Add JAVA_HOME environment variable
Modify $HBASE_HOME/conf/hbase-env.sh file, add JAVA_HOME configuration -
start and stop service
cd hbase-2.1.2/bin/ ./start-hbase.sh //Start service ./stop-hbase.sh //Out of Service
-
Access on Browser http://192.168.153.131:16010 , view installation information.
Picture: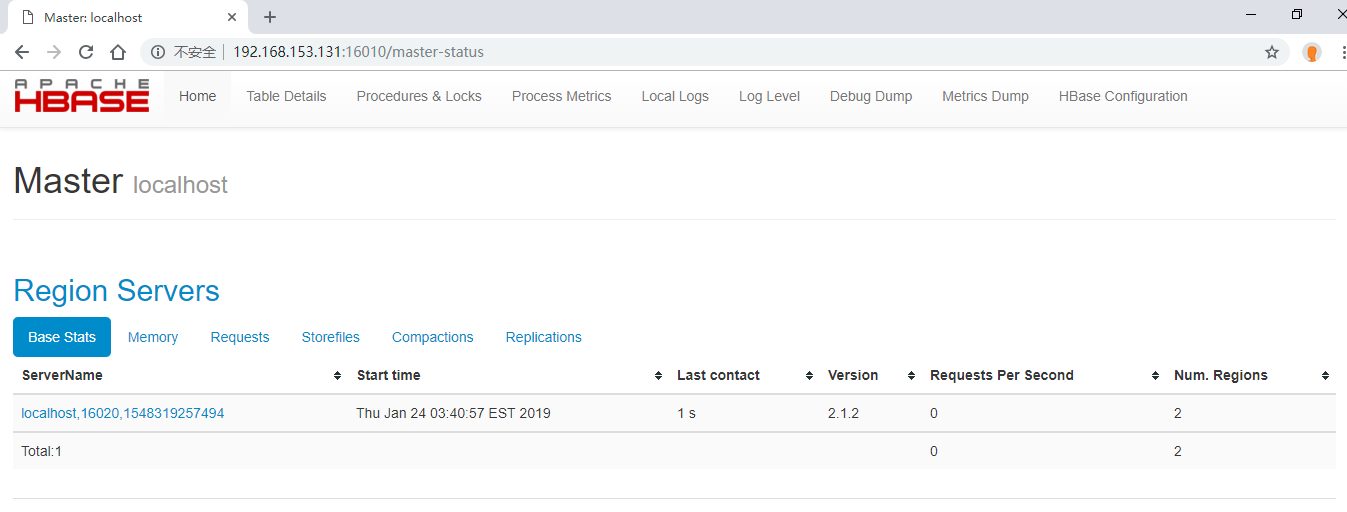
Zookeeper installation and configuration
-
Download from Zookeeper's official website Zoomeeper website link.
-
Transfer it to the hadoop installation directory / opt through ftp tool, use tar command to decompress the compressed package, and execute the command:
tar -zxvf apache-zookeeper-3.5.5-bin.tar.gz
-
Enter the configuration file directory of zookeeper and view the files in this directory
cd apache-zookeeper-3.5.5-bin/conf/ ll
-
There is a sample configuration file zoo in this directory_ Sample.cfg, copy it to zoo.cfg, and then edit the configuration file zoo.cfg using vim
cp zoo_sample.cfg zoo.cfg vim zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=D:\\zookeeper-3.5.4-beta\\data dataLogDir=D:\\zookeeper-3.5.4-beta\\log # the port at which the clients will connect admin.serverPort=8082 clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
Modified content:
Added: admin.serverPort=8082 #Otherwise, the port will be occupied, because the default is port 8080 used with Apache.Tomcat
Modified: dataDir=D:\\zookeeper-3.5.4-beta\\data #Directory where data is saved
dataLogDir=D:\\zookeeper-3.5.4-beta\\log #Directory where logs are saved
After these are configured, start the Zookeeper. After startup, check whether the Zookeeper is already in service. You can check whether there is a configured clientPort port number listening to the service through the netstat- ano command.
HBase Shell authentication environment
-
Enter the shell command line. Execute in the bin directory under the installation directory:. / hbase shell
./hbase shell
-
Create table
create 'persn','code','name','info'

-
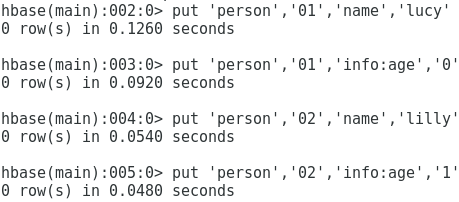
Add record
put 'person', '01', 'name', 'lucy' put 'person', '01', 'info:age', '0' put 'person', '02', 'name', 'lily' put 'person', '02', 'info:age', '1'
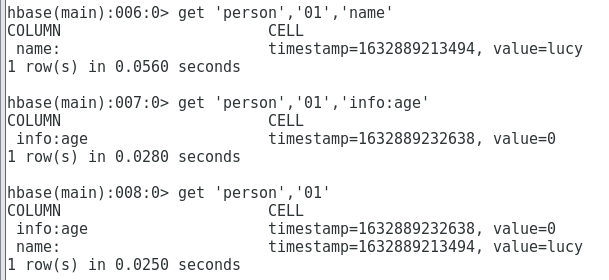
- View row records
get 'person', '01', 'name' get 'person', '01', 'info:age' get 'person', '01'
- View all data
scan 'person' scan 'person', {COLUMN=>'name'}
3, Task division
I am responsible for the region part of Hbase, including region positioning, region allocation, and the online and offline of region server. It will be dynamically adjusted according to the progress in the future.