2021SC@SDUSC
1, Brief description
Snapshot is a function supported by many storage systems and database systems. A snapshot is the image of a whole file system or a directory at a certain time.
2, Basic principle
The simplest and crudest way to realize data file mirroring is to lock the copy (the reason for locking is that the data obtained from the mirror must be completely consistent at a certain time). During the copy period, no update or deletion of the original data in any form is allowed, only read-only operation is provided, and the lock is released after the copy is completed. This method involves the actual copy of data. When the amount of data is large, it will inevitably take a lot of time. A long locked copy will inevitably lead to the client's inability to update and delete for a long time, which can not be tolerated on the production line.
The snapshot mechanism does not copy data, which can be understood as a pointer to the original data. It is easy to understand under the LSM type system structure of HBase. We know that once the HBase data file falls to the disk, it is no longer allowed to update, delete and other in-situ modification operations. If you want to update and delete, you can add and write a new file (there is no update interface in HBase, and the delete command is also add write). In this mechanism, to realize the snapshot of a table, you only need to create a new reference (pointer) for all files of the current table, and re create a new file for other newly written data.
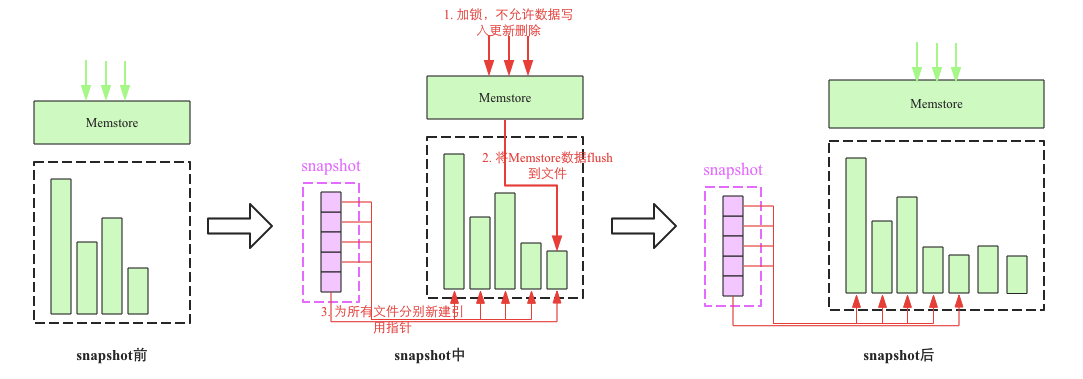
The snapshot process mainly involves three steps:
- Add a global lock. At this time, no data is allowed to be written, updated and deleted
- flush the cached data in the memory to a file (optional)
- Create new reference pointers for all HFile files. These pointer metadata are snapshot s
3, Realize
The process of snapshot is similar to two-stage submission. The general process is that after receiving the snapshot command, HMaster acts as the coordinator, and then takes out the region of the Photo table and the information of the corresponding region server from the meta region. These region servers act as participant s in the two-stage submission, The prepare phase is equivalent to taking a snapshot of the region of the local Photo table of the region server and storing it in the temporary directory of HDFS. The commit phase is actually HMaster changing the temporary directory to the correct directory. During this period, the data sharing between HMaster and region server is completed through ZK.
snapshot command:
hbase> snapshot 'sync_stage:Photo', 'PhotoSnapshot'
For sync_ The Photo table in the namespace of stage takes a snapshot (the table has only one column family, which is called PHOTO), and the snapshot name is photoshot
public void takeSnapshot(SnapshotDescription snapshot) throws IOException {
snapshot = snapshot.toBuilder().setVersion(SnapshotDescriptionUtils.SNAPSHOT_LAYOUT_VERSION)
.build();
// if the table is enabled, then have the RS run actually the snapshot work
TableName snapshotTable = TableName.valueOf(snapshot.getTable());
AssignmentManager assignmentMgr = master.getAssignmentManager();
if (assignmentMgr.getZKTable().isEnabledTable(snapshotTable)) {
snapshotEnabledTable(snapshot);
}
else if (assignmentMgr.getZKTable().isDisabledTable(snapshotTable)) {
snapshotDisabledTable(snapshot);
} else {
throw new SnapshotCreationException("Table is not entirely open or closed", tpoe, snapshot);
}
}
Clear previously completed backup and recovery tasks cleanupSentinels(); And set the version of the snapshot
(assignmentMgr.getZKTable().isEnabledTable(snapshotTable)) select the type of snapshot according to the status of the table.
Enabled tables:
private synchronized void snapshotEnabledTable(SnapshotDescription snapshot)
throws HBaseSnapshotException {
// snapshot preparation
prepareToTakeSnapshot(snapshot);
// new a handler
EnabledTableSnapshotHandler handler =
new EnabledTableSnapshotHandler(snapshot, master, this);
//Backup via handler thread
snapshotTable(snapshot, handler);
}
Prepare and back up through the handler thread
handler.prepare(); this.executorService.submit(handler); this.snapshotHandlers.put(TableName.valueOf(snapshot.getTable()), handler);
EnabledTableSnapshotHandler inherits from TakeSnapshotHandler. The task entry function is in the process() method, prepare method and process method of TakeSnapshotHandler. The difference is that the snapshotRegions method is rewritten.
Check whether the prepare method or the definition file of the checklist is in
SnapshotDescriptionUtils.writeSnapshotInfo(snapshot, workingDir, this.fs);
new TableInfoCopyTask(monitor, snapshot, fs, rootDir).call();
monitor.rethrowException();
List> regionsAndLocations =
MetaReader.getTableRegionsAndLocations(this.server.getCatalogTracker(),
snapshotTable, false);
snapshotRegions(regionsAndLocations);
Set serverNames = new HashSet();
for (Pair p : regionsAndLocations) {
if (p != null && p.getFirst() != null && p.getSecond() != null) {
HRegionInfo hri = p.getFirst();
if (hri.isOffline() && (hri.isSplit() || hri.isSplitParent())) continue;
serverNames.add(p.getSecond().toString());
}
}
status.setStatus("Verifying snapshot: " + snapshot.getName());
verifier.verifySnapshot(this.workingDir, serverNames);
completeSnapshot(this.snapshotDir, this.workingDir, this.fs);
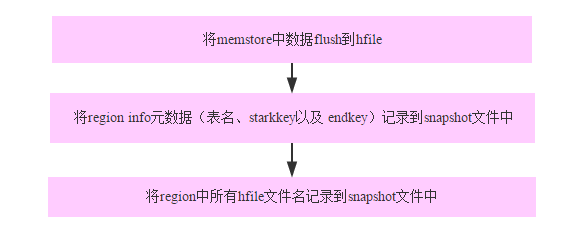
Write a. snapshotinfo file to the working directory, and write a copy of the table definition information to the working directory, that is, the. tabledesc file. Next, find the Region Server and machine related to the table, start the backup, and verify the results of the snapshot. Confirm that there is no problem, rename the temporary directory to the official directory.
Procedure proc = coordinator.startProcedure(this.monitor, this.snapshot.getName(),
this.snapshot.toByteArray(), Lists.newArrayList(regionServers));
try {
Path snapshotDir = SnapshotDescriptionUtils.getWorkingSnapshotDir(snapshot, rootDir);
for (Pair region : regions) {
HRegionInfo regionInfo = region.getFirst();
if (regionInfo.isOffline() && (regionInfo.isSplit() || regionInfo.isSplitParent())) {
if (!fs.exists(new Path(snapshotDir, regionInfo.getEncodedName()))) {
LOG.info("Take disabled snapshot of offline region=" + regionInfo);
snapshotDisabledRegion(regionInfo);
}
}
}
This is in the EnabledTableSnapshotHandler method. Path snapshotDir = SnapshotDescriptionUtils.getWorkingSnapshotDir(snapshot, rootDir); Wait for the completion of proc.waitForCompleted() `, and back up the split region
Procedure proc = createProcedure(fed, procName, procArgs,expectedMembers);
if (!this.submitProcedure(proc)) {
LOG.error("Failed to submit procedure '" + procName + "'");
return null;
}
Enter the startProcedure of the Procedure coordinator, create the Procedure first, and then submit it
final public Void call() {
try {
sendGlobalBarrierStart();
waitForLatch(acquiredBarrierLatch, monitor, wakeFrequency, "acquired");
sendGlobalBarrierReached();
waitForLatch(releasedBarrierLatch, monitor, wakeFrequency, "released");
} finally {
sendGlobalBarrierComplete();
completedLatch.countDown();
}}
call () is to create an instance node under the acquired node. waitForLatch(acquiredBarrierLatch, monitor, wakeFrequency, "acquired"); Wait for all rs replies, sendglobalbarrier reached(); Create an instance node under the reached node, waitForLatch(releasedBarrierLatch, monitor, wakeFrequency, "released"); Waiting for all rs replies
final public void sendGlobalBarrierAcquire(Procedure proc, byte[] info, List nodeNames)
throws IOException, IllegalArgumentException {
String procName = proc.getName();
String abortNode = zkProc.getAbortZNode(procName);
try {
if (ZKUtil.watchAndCheckExists(zkProc.getWatcher(), abortNode)) {
abort(abortNode);
}
} catch (KeeperException e) {throw new IOException("Failed while watching abort node:" + abortNode, e);
}
String acquire = zkProc.getAcquiredBarrierNode(procName);try {
byte[] data = ProtobufUtil.prependPBMagic(info);
ZKUtil.createWithParents(zkProc.getWatcher(), acquire, data);
for (String node : nodeNames) {
String znode = ZKUtil.joinZNode(acquire, node);if (ZKUtil.watchAndCheckExists(zkProc.getWatcher(), znode)) {
coordinator.memberAcquiredBarrier(procName, node);
}
}
} catch (KeeperException e) {
throw new IOException("Failed while creating acquire node:" + acquire, e);
}
}
1. First, check the abortNode (each procName has a corresponding node under zk, such as snapshot, and then there are three nodes under procName: acquired, reached and abort. Check whether there is a current instance under the abort node.)
2. Create a node for the instance at the acquired node. After creation, monitor the nodes of each Region Server under the instance node. If it is found that there are already, update the acquiringMembers list and inBarrierMembers in the Procedure, delete the node from the acquiringMembers, and then add it to the inBarrierMembers list.
3. At this step, the work of the server stops. After all RS receive the instruction, create the node under the acquired node.
4. After receiving all RS replies, it will start to create an instance node in the reached node, and then continue to wait.
5. After RS completes the task, create the corresponding node under the reached instance node, and then reply.
6. After confirming that all RS have completed their work, clean up the corresponding proName node in zk.
Note: in this process, if there is a task error, the node of this instance will be established under the abort node. Once the sub process above RS finds that there is an instance of this node in abort, it will cancel the process.
public ZKProcedureMemberRpcs(final ZooKeeperWatcher watcher, final String procType)
throws KeeperException {
this.zkController = new ZKProcedureUtil(watcher, procType) {
@Override
public void nodeCreated(String path) {
if (!isInProcedurePath(path)) {
return;
}
String parent = ZKUtil.getParent(path);
// if its the end barrier, the procedure can be completed
if (isReachedNode(parent)) {
receivedReachedGlobalBarrier(path);
return;
} else if (isAbortNode(parent)) {
abort(path);
return;
} else if (isAcquiredNode(parent)) {
startNewSubprocedure(path);
} else {
LOG.debug("Ignoring created notification for node:" + path);
}
}
};
}
In the Region Server, the ProcedureMemberRpcs in the RegionServerSnapshotManager class is responsible for monitoring the node changes under the snapshot. When it is found that there are instances under acquired, start a new task.
public Subprocedure createSubprocedure(String opName, byte[] data) {
return builder.buildSubprocedure(opName, data);
}
When the detection node is added, the above method of ProcedureMember will be called to create a subprocess. The builder here is a snapshotsubprocessbuilder. Its buildSubprocedure() will create a subprocess of flushsnapshotsubprocess type. Flushsnapshotsubprocess has a member variable named regions, which will be initialized here, Check whether there are regions in the snapshot table from the online regions list of the region server. If so, initialize regions, otherwise regions are empty. Similarly, this subprocess will be submitted to the internal thread pool for processing. Flushsnapshot subprocess inherits from subprocess. It is a callable and the entry function is call.
final public Void call() {
try {
waitForReachedGlobalBarrier();
//...
} catch (Exception e) {
} finally {
releasedLocalBarrier.countDown();
}
}
acquireBarrier(); Create the rs node rpcs.sendMemberAcquired(this) under the acquired instance node;, Wait for the establishment of the reached instance node
Next, insideBarrier() rpcs.sendMemberCompleted(this);
It can be seen that the region server can only go down to the actual snapshot operation after the corresponding reached node is established, and the HMaster can only establish the region server after seeing that all relevant region servers have acquire d tasks, which achieves the purpose of synchronization.
for (HRegion region : regions) {
taskManager.submitTask(new RegionSnapshotTask(region));
}
The implementation of insideBarrier is in the class flushsnapshot subprocess, which calls flushSnapshot(), which opens a thread for each region to submit.
public void addRegionToSnapshot(SnapshotDescription desc,
ForeignExceptionSnare exnSnare) throws IOException {
Path rootDir = FSUtils.getRootDir(this.rsServices.getConfiguration());
Path snapshotDir = SnapshotDescriptionUtils.getWorkingSnapshotDir(desc, rootDir);
HRegionFileSystem snapshotRegionFs = HRegionFileSystem.createRegionOnFileSystem(conf,
this.fs.getFileSystem(), snapshotDir, getRegionInfo());
for (Store store : stores.values()) {
Path dstStoreDir = snapshotRegionFs.getStoreDir(store.getFamily().getNameAsString());
List storeFiles = new ArrayList(store.getStorefiles());
for (int i = 0; i < sz; i++) {
StoreFile storeFile = storeFiles.get(i);
Path file = storeFile.getPath();
Path referenceFile = new Path(dstStoreDir, file.getName());
boolean success = true;
if (storeFile.isReference()) {
storeFile.getFileInfo().getReference().write(fs.getFileSystem(), referenceFile);
} else {
success = fs.getFileSystem().createNewFile(referenceFile);
}
if (!success) {
throw new IOException("Failed to create reference file:" + referenceFile);
}
}
}
}
- Create the region directory in the working directory and write the information of the region
- Create reference for hfile
2.1. Create a reference directory for stores by column family. Each store belongs to a different column family
2.2. Traverse hfile and create reference int sz = storeFiles.size();
Write the contents of the old reference file into the new reference file, and getFileSystem() creates an empty reference file
Create a reference file for hfile in the working directory under. HBase snapshot /. Tmps / snapshotname / region / familyname /. When creating a reference file, you should first judge whether the so-called hfile is a real hfile or whether it itself is a reference file.
If it is already a reference file, write the contents of the old reference file into the new reference file.
If it is a normal hfile, just create an empty reference file. Later, we can find its corresponding file under the snapshot through its name.
At this point, the work of each RS has been completed.
Disabled tables:
The difference between backing up disabled tables is the snapshotRegions method, but in addition to doing some preparatory work, the method is snapshotDisabledRegion, which is similar to the above.
4, Function
1. Full / incremental backup: any database needs a backup function to achieve high data reliability. Snapshot can easily realize the online backup function of tables, and has little impact on online business requests. With backup data, users can quickly roll back to the specified snapshot point in case of exception. Incremental backup uses binlog for periodic incremental backup on the basis of full backup.
2. Data migration: you can use the ExportSnapshot function to export snapshots to another cluster to realize data migration