2021SC@SDUSC hbase source code analysis (x) HFile analysis (2)
2021SC@SDUSC 2021SC@SDUSC
2021SC@SDUSC 2021SC@SDUSC
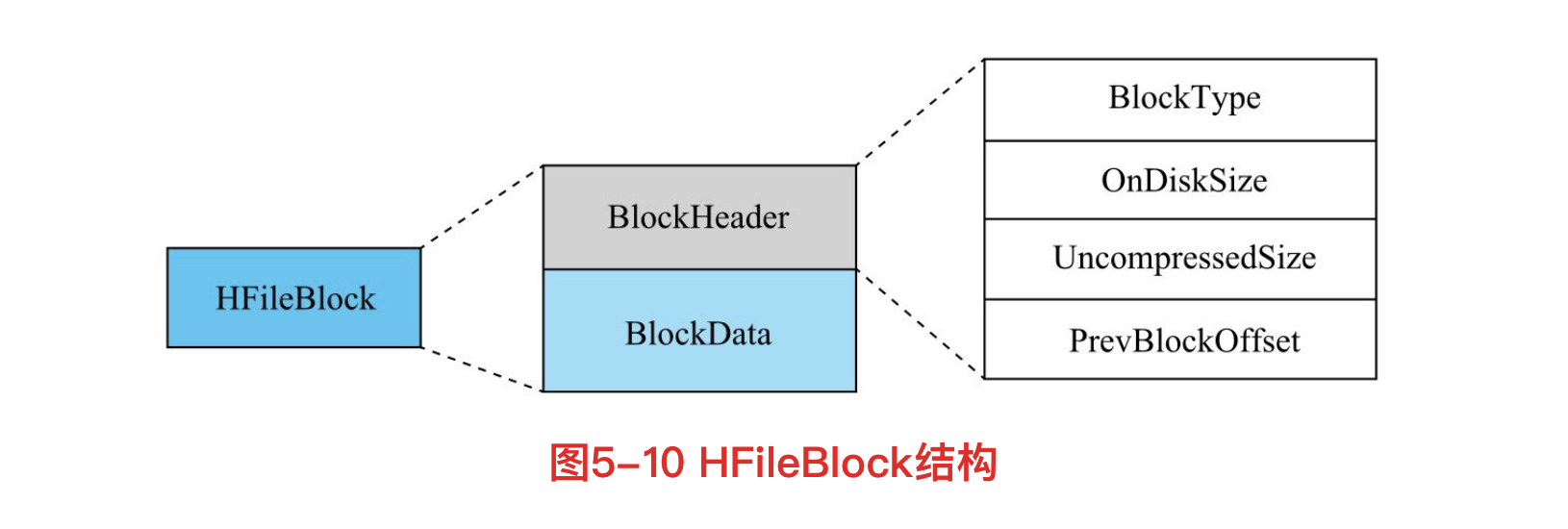
HFileBlock
HFileBlock mainly includes two parts: BlockHeader and BlockData.
BlockHeader mainly stores Block related metadata, and BlockData is used to store specific data.
The core field in Block metadata is the BlockType field, which indicates the type of the Block. HBase defines eight blocktypes. The blocks corresponding to each BlockType store different contents, including user data, index data and metadata. For any type of HFileBlock, it has the same BlockHeader structure, but the BlockData structure is different.
HFileBlock structure
The HFileBlock structure is shown in the following figure:
Core BlockType

HFileBlock source code
HFileBlock.Writer
static class Writer implements ShipperListener {
//It is used to identify the current Writer state and ensure the correctness of Writer state during other method calls
private enum State {
INIT,
WRITING,
BLOCK_READY
};
private State state = State.INIT;
private final HFileDataBlockEncoder dataBlockEncoder;
private HFileBlockEncodingContext dataBlockEncodingCtx;
private HFileBlockDefaultEncodingContext defaultBlockEncodingCtx;
private ByteArrayOutputStream baosInMemory;
private BlockType blockType;
private DataOutputStream userDataStream;
private ByteArrayOutputStream onDiskBlockBytesWithHeader;
private byte[] onDiskChecksum = HConstants.EMPTY_BYTE_ARRAY;
private long startOffset;
}
HFileBlock.Writer uses the following:
(1) To build an HFileBlock.Writer instance, you need to provide what compression algorithm to use, what data encoding format to use, whether to include MemstoreTS, HBase small version number, checksum type, and how many bytes of data to generate a checksum;
(2) Obtain an output stream that can be used to write data through the startWriting method;
(3) Call the writeHeaderAndData method cyclically as needed to write out the block data to the output stream, and then get a byte array containing the written block data through the getHeaderAndData method;
(4) Loop (2) and (3) write out more block data.
startWriting method
DataOutputStream startWriting(BlockType newBlockType)
throws IOException {
if (state == State.BLOCK_READY && startOffset != -1) {
//According to the data block type, record the starting offset of the previous data block in HFile. This operation will only be performed when the current data block is written (state is BLOCK_READY)
prevOffsetByType[blockType.getId()] = startOffset;
}
startOffset = -1;
blockType = newBlockType;
baosInMemory.reset();
baosInMemory.write(HConstants.HFILEBLOCK_DUMMY_HEADER);
state = State.WRITING;
// We will compress it later in finishBlock()
userDataStream = new ByteBufferWriterDataOutputStream(baosInMemory);
if (newBlockType == BlockType.DATA) {
this.dataBlockEncoder.startBlockEncoding(dataBlockEncodingCtx, userDataStream);
}
return userDataStream;
}
This method is used to prepare to write block data, and the data of the previous block will be discarded.
Write KeyValue procedure
// Write length of key and value and then actual key and value bytes.
// Additionally, we may also write down the memstoreTS.
{
DataOutputStream out = fsBlockWriter.getUserDataStream();
out.writeInt(klength);
totalKeyLength += klength;
out.writeInt(vlength);
totalValueLength += vlength;
out.write(key, koffset, klength);
out.write(value, voffset, vlength);
if (this.includeMemstoreTS) {
WritableUtils.writeVLong(out, memstoreTS);
}
}
The above code is actually completed by HFileWriterV2.append
writeHeaderAndData method
void writeHeaderAndData(FSDataOutputStream out) throws IOException {
long offset = out.getPos();
if (startOffset != UNSET && offset != startOffset) {
throw new IOException("A " + blockType + " block written to a "
+ "stream twice, first at offset " + startOffset + ", then at "
+ offset);
}
startOffset = offset;
finishBlockAndWriteHeaderAndData(out);
}
The main function is to record the starting offset of the current block so that it can be used when operating the next data block of the same type. Other operations are transferred to the overloaded method writeHeaderAndData(FSDataOutputStream). The overall responsibility is to write the accumulated block data to the specified output stream, HDFS.
finishBlock method
private void finishBlock() throws IOException {
if (blockType == BlockType.DATA) {
this.dataBlockEncoder.endBlockEncoding(dataBlockEncodingCtx, userDataStream,
baosInMemory.getBuffer(), blockType);
blockType = dataBlockEncodingCtx.getBlockType();
}
//Brush out output stream data
userDataStream.flush();
//Saves the start offset of the previous block of the same type as the current block
prevOffset = prevOffsetByType[blockType.getId()];
//Update Writer status to BLOCK_READY, note that the data has not been encoded or compressed when this operation is performed.
state = State.BLOCK_READY;
Bytes compressAndEncryptDat;
if (blockType == BlockType.DATA || blockType == BlockType.ENCODED_DATA) {
compressAndEncryptDat = dataBlockEncodingCtx.
compressAndEncrypt(baosInMemory.getBuffer(), 0, baosInMemory.size());
} else {
compressAndEncryptDat = defaultBlockEncodingCtx.
compressAndEncrypt(baosInMemory.getBuffer(), 0, baosInMemory.size());
}
if (compressAndEncryptDat == null) {
compressAndEncryptDat = new Bytes(baosInMemory.getBuffer(), 0, baosInMemory.size());
}
if (onDiskBlockBytesWithHeader == null) {
onDiskBlockBytesWithHeader = new ByteArrayOutputStream(compressAndEncryptDat.getLength());
}
onDiskBlockBytesWithHeader.reset();
onDiskBlockBytesWithHeader.write(compressAndEncryptDat.get(),
compressAndEncryptDat.getOffset(), compressAndEncryptDat.getLength());
// Calculate how many bytes we need for checksum on the tail of the block.
int numBytes = (int) ChecksumUtil.numBytes(
onDiskBlockBytesWithHeader.size(),
fileContext.getBytesPerChecksum());
// Put the header for the on disk bytes; header currently is unfilled-out
putHeader(onDiskBlockBytesWithHeader,
onDiskBlockBytesWithHeader.size() + numBytes,
baosInMemory.size(), onDiskBlockBytesWithHeader.size());
if (onDiskChecksum.length != numBytes) {
onDiskChecksum = new byte[numBytes];
}
ChecksumUtil.generateChecksums(
onDiskBlockBytesWithHeader.getBuffer(), 0,onDiskBlockBytesWithHeader.size(),
onDiskChecksum, 0, fileContext.getChecksumType(), fileContext.getBytesPerChecksum());
}
This is the code. If compression is not used, onDiskBytesWithHeader contains header data + data, and onDiskChecksum is the corresponding checksum data; If compression is used, onDiskBytesWithHeader contains header data + compressed data + checksum data, and onDiskChecksum is EMPTY_BYTE_ARRAY. Step 3 write headeranddata to write out the block data (onDiskBytesWithHeader, onDiskChecksum) accordingly.