2021SC@SDUSC
1, Brief description
Coding + compression can double the disk space of data and save considerable storage costs. At the same time, shrinking can usually improve the system throughput, so that the system can do more work
In terms of space saving processing at the storage level, HBase provides two schemes:
1. Key based coding. It is used to simply process the repeated part of the key to save space.
2. Compression based on database (data block). Compress the data block to save hard disk.
Reference link
2, key code
This is mainly for scenarios where the key is very long and there are a large number of partial repetitions. If most of the keys are different, the coding has little advantage:
prefix
Omit the same part of the key as the previous record, and then add a column to record the omitted length
raw data: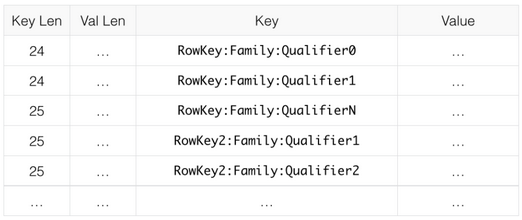
Encoded data:
You can see that the prefix len column is added to record the number of bits repeated from the first bit, but the record in the key column is simplified

diff
Diff is a schema based on prefix, which directly omits the same part as the previous record; Diff differs from prefix in that it thinks that each record has a unique primary key. Therefore, diff adds two columns, one is timestamp and the other is type; The advantage of this processing is that after the primary key is divided, it can have better efficiency after compression; The default diff is disabled because the performance of diff is poor in scan.

3, DataBlock decompression
As a schema free database, hbase is equivalent to the traditional relational database. It is more flexible. Users do not need to design the table structure, but can also write data from different schemas in the same table. However, due to the lack of data structure support, hbase needs many additional data structures to label the length information, and can not adopt different compression methods for different data types. To solve this problem, hbase proposes a coding function to reduce the storage overhead. Because coding has less cpu overhead and better effect, the coding function is usually enabled in the cache.
Old DIFF Encoding
hbase has long supported data block encoding, which is to compress data by reducing duplicate parts in hbase keyvalue.
After DIFF encoding, the seek of a file includes the following two steps:
1. Find the corresponding datablock through the index key
2. Start from the first complete kV, search in sequence, and continue to decode the next kV until the target kV is found.
DIFF encoding works well for small kv scenes, reducing the amount of data by 2-5 times.
New Indexable Delta Encoding
From a performance perspective, hbase usually needs to load Meta information into the block cache. If the block size is small and there is more Meta information, the Meta cannot be fully loaded into the Cache, resulting in performance degradation. If the block size is large, the performance of DIFF Encoding sequential query will become the performance bottleneck of random read. In view of this situation, we have developed Indexable Delta Encoding, which can also be queried quickly through the index inside the block, and the search performance has been greatly improved.
After finding the corresponding data block through BlockIndex, we find the offset of each complete kV from the end of the data block, use binary search to quickly locate the complete kV that meets the query conditions, and then decode each Diff kv in order until we find the target kV position.
Through Indexable Delta Encoding, the random seek performance of HFile is doubled compared with that before use. Taking 64K block as an example, in the random Get scenario of full cache hit, compared with Diff encoding rt, it is reduced by 50%, but the storage overhead is only increased by 3-5%. At present, Indexable Delta Encoding has been applied in many online scenarios and has withstood the test of double 11, with an overall average reading rt reduction of 10% - 15%.
Trie word lookup tree
HBase takes out a separate project to realize the data results of Trie, which can not only achieve the effect of compression coding, but also facilitate query.
There are three types of data structures in the tree: branch, leaf and nub
1. branch node: the resulting word does not appear, but the word of a single t does not appear in the branches of to and tea.
2. leaf node: there are no child nodes below
3. nub node: balance between the two
* Example inputs (numInputs=7): * 0: AAA * 1: AAA * 2: AAB * 3: AAB * 4: AAB * 5: AABQQ * 6: AABQQ * * Resulting TokenizerNodes: * AA <- branch, numOccurrences=0, tokenStartOffset=0, token.length=2 * A <- leaf, numOccurrences=2, tokenStartOffset=2, token.length=1 * B <- nub, numOccurrences=3, tokenStartOffset=2, token.length=1 * QQ <- leaf, numOccurrences=2, tokenStartOffset=3, token.length=2
Two classes Tokenizer and tokenizenode are used to describe the data structure
The starting point is PrefixTreeCodec. This class inherits from the DataBlockEncoder interface. DataBlockEncoder is specifically responsible for encoding and compression. There are three important methods in it, encodeKeyValues (encoding), decodeKeyValues (de encoding) and createSeeker (creating scanner).
private void internalEncodeKeyValues(DataOutputStream encodedOutputStream,
ByteBuffer rawKeyValues, boolean includesMvccVersion) throws IOException {
rawKeyValues.rewind();
PrefixTreeEncoder builder = EncoderFactory.checkOut(encodedOutputStream, includesMvccVersion);
try{
KeyValue kv;
while ((kv = KeyValueUtil.nextShallowCopy(rawKeyValues, includesMvccVersion)) != null) {
builder.write(kv);
}
builder.flush();
}finally{
EncoderFactory.checkIn(builder);
}
}
The encodeKeyValues method in PrefixTreeCodec is the entry, and internalEncodeKeyValues is the actual encoding place. From rawKeyValues, read kv continuously, encoding with PrefixTreeEncoder.write method, and finally calling flush for output.
rowTokenizer.addSorted(CellUtil.fillRowRange(cell, rowRange)); addFamilyPart(cell); addQualifierPart(cell); addAfterRowFamilyQualifier(cell);
This is in the PrefixTreeEncoder.write method. Here, skip to the Tokenizer.addSorted method
public void addSorted(final ByteRange bytes) {
++numArraysAdded;
if (bytes.getLength() > maxElementLength) {
maxElementLength = bytes.getLength();
}
if (root == null) {
root = addNode(null, 1, 0, bytes, 0);
} else {
root.addSorted(bytes);
}
}
If the root node is empty, a new root node will be created. After having the root node, the node will be added to the child queue of the root node.
public void addSorted(final ByteRange bytes) {// recursively build the tree
if (matchesToken(bytes) && CollectionUtils.notEmpty(children)) {
TokenizerNode lastChild = CollectionUtils.getLast(children);
if (lastChild.partiallyMatchesToken(bytes)) {
lastChild.addSorted(bytes);
return;
}
}
int numIdenticalTokenBytes = numIdenticalBytes(bytes);// should be <= token.length
int tailOffset = tokenStartOffset + numIdenticalTokenBytes;
int tailLength = bytes.getLength() - tailOffset;
if (numIdenticalTokenBytes == token.getLength()) {
if (tailLength == 0) {// identical to this node (case 1)
incrementNumOccurrences(1);
} else {
int childNodeDepth = nodeDepth + 1;
int childTokenStartOffset = tokenStartOffset + numIdenticalTokenBytes;
TokenizerNode newChildNode = builder.addNode(this, childNodeDepth, childTokenStartOffset, bytes, tailOffset);
addChild(newChildNode);
}
} else { split(numIdenticalTokenBytes, bytes);
}
}
1. First add an AAA, which is the root node, the parent is null, the depth is 1, and the starting position in the original word is 0.
2. Add an AAA, which is exactly the same as the previous AAA. It takes incrementNumOccurrences(1) and the number of occurrences (numOccurrences) becomes 2.
3. Add AAB. Compared with AAA, the matching length is 2 and the tail length is 1. Then it follows the path of split(numIdenticalTokenBytes, bytes)
protected void split(int numTokenBytesToRetain, final ByteRange bytes) {
int childNodeDepth = nodeDepth;
int childTokenStartOffset = tokenStartOffset + numTokenBytesToRetain;
TokenizerNode firstChild = builder.addNode(this, childNodeDepth, childTokenStartOffset,
token, numTokenBytesToRetain);
firstChild.setNumOccurrences(numOccurrences);// do before clearing this node's numOccurrences
token.setLength(numTokenBytesToRetain);//shorten current token from BAA to B
numOccurrences = 0;//current node is now a branch
moveChildrenToDifferentParent(firstChild);//point the new leaf (AA) to the new branch (B)
addChild(firstChild);//add the new leaf (AA) to the branch's (B's) children
TokenizerNode secondChild = builder.addNode(this, childNodeDepth, childTokenStartOffset,
bytes, tokenStartOffset + numTokenBytesToRetain);
addChild(secondChild);//add the new leaf (00) to the branch's (B's) children
firstChild.incrementNodeDepthRecursively();
secondChild.incrementNodeDepthRecursively();
}
Effect of split completion:
- The tokenStartOffset of the child node is equal to the tokenStartOffset of the parent node plus the matching length, where 0 + 2 = 2
2) Create A left child with A token and the same depth as the parent node. The number of occurrences is the same as that of the father
3) The token length of the parent node becomes the matching length 2 (AA), and the occurrence times is set to 0
4) Point the child nodes of the original node to the left child
5) Point the parent node of the left child to the current node
6) Create a right child with a token of B and a depth consistent with the parent node
7) Point the parent node of the right child to the current node
8) Increase the depth of the left and right children recursively.
4. Add AAB, which exactly matches AA, and the last child node AAB also matches. Call addSorted(bytes) of AAB node. Because it is an exact match, the number of occurrences of B is increased by 1 as in step 2
5. Add AABQQ, which exactly matches AA, and the last child node AAB also matches. Call the addSorted(bytes) of the AAB node to become the child of AAB
if (matchesToken(bytes) && CollectionUtils.notEmpty(children)) {
TokenizerNode lastChild = CollectionUtils.getLast(children);
if (lastChild.partiallyMatchesToken(bytes)) {
lastChild.addSorted(bytes);
return;
}
}
Enter recursion and match the prefix of the last node
6. Add AABQQ to increase the number of QQ occurrences
Next, continue to operate during flush to build index information for the tree and query aspects.