6, Text classification

source
Datewhle29 issue__ NLP transformer:
- Erenup (more notes), Peking University, principal
- Zhang Fan, Datawhale, Tianjin University, Chapter 4
- Zhang Xian, Harbin Institute of technology, Chapter 2
- Li luoqiu, Zhejiang University, Chapter 3
- CAI Jie, Peking University, Chapter 4
- hlzhang, McGill University, Chapter 4
- Taiyunpeng Chapter 2
- Zhang Hongxu Chapter 2
Learning materials address:
https://datawhalechina.github.io/learn-nlp-with-transformers/#/
github address:
https://github.com/datawhalechina/learn-nlp-with-transformers
1.1 partial classification tasks

-
The GLUE list contains 9 sentence level classification tasks, which are:
- CoLA (Corpus of Linguistic Acceptability) identifies whether a sentence is grammatically correct
- Mnli (multi gene natural language influence) gives a hypothesis and judges the relationship between another sentence and the hypothesis: entries, contracts or unrelated.
- MRPC (Microsoft Research Paraphrase Corpus) judges whether two sentences are paraphrases to each other
- Qnli (question answering natural language inference) determines whether the second sentence contains the answer to the first question.
- QQP (Quora Question Pairs2) determines whether two questions have the same semantics.
- RTE (recognizing textual entry) determines whether a sentence has an entail relationship with a hypothesis.
- Sst-2 (Stanford sentient treebank) judges the positive and negative emotion of a sentence
- STS-B (Semantic Textual Similarity Benchmark) judges the similarity of two sentences (score is 1-5).
- Wnli (Winograd natural language influence) judges whether a sentence with an anonymous pronoun and a sentence with the pronoun replaced contain
GLUE_TASKS = ["cola", "mnli", "mnli-mm", "mrpc", "qnli", "qqp", "rte", "sst2", "stsb", "wnli"]
1.2 loading data
- Data loading and evaluation loading only need to use load_dataset and load_metric is enough.
from datasets import load_dataset, load_metric
- Except mnli mm, other tasks can be loaded directly by task name. Data is automatically cached after loading.
actual_task = "mnli" if task == "mnli-mm" else task
dataset = load_dataset("glue", actual_task)
metric = load_metric('glue', actual_task)

- Evaluation metric is an example of datasets.Metric:
metric
Metric(name: "glue", features: {'predictions': Value(dtype='int64', id=None), 'references': Value(dtype='int64', id=None)}, usage: """
Compute GLUE evaluation metric associated to each GLUE dataset.
Args:
predictions: list of predictions to score.
Each translation should be tokenized into a list of tokens.
references: list of lists of references for each translation.
Each reference should be tokenized into a list of tokens.
Returns: depending on the GLUE subset, one or several of:
"accuracy": Accuracy
"f1": F1 score
"pearson": Pearson Correlation
"spearmanr": Spearman Correlation
"matthews_correlation": Matthew Correlation
Examples:
>>> glue_metric = datasets.load_metric('glue', 'sst2') # 'sst2' or any of ["mnli", "mnli_mismatched", "mnli_matched", "qnli", "rte", "wnli", "hans"]
>>> references = [0, 1]
>>> predictions = [0, 1]
>>> results = glue_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 1.0}
>>> glue_metric = datasets.load_metric('glue', 'mrpc') # 'mrpc' or 'qqp'
>>> references = [0, 1]
>>> predictions = [0, 1]
>>> results = glue_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'accuracy': 1.0, 'f1': 1.0}
>>> glue_metric = datasets.load_metric('glue', 'stsb')
>>> references = [0., 1., 2., 3., 4., 5.]
>>> predictions = [0., 1., 2., 3., 4., 5.]
>>> results = glue_metric.compute(predictions=predictions, references=references)
>>> print({"pearson": round(results["pearson"], 2), "spearmanr": round(results["spearmanr"], 2)})
{'pearson': 1.0, 'spearmanr': 1.0}
>>> glue_metric = datasets.load_metric('glue', 'cola')
>>> references = [0, 1]
>>> predictions = [0, 1]
>>> results = glue_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'matthews_correlation': 1.0}
""", stored examples: 0)
- Directly call the compute method of metric and pass in labels and predictions to get the value of metric:
- Metric's compute is done by using the datasets.Metric.compute() method. Forecasts and recommendations: you can add forecasts and recommendations (if you use datasets.Metric.add() or datasets.Metric, they will be added to the end of the cache. Add_batch() before) specific parameters, which can be required, or you can modify the behavior of some indicators (print indicator input description to view the use of print (metric) or print (metric.inputs_description) Details of).
import numpy as np fake_preds = np.random.randint(0, 2, size=(64,)) fake_labels = np.random.randint(0, 2, size=(64,)) metric.compute(predictions=fake_preds, references=fake_labels)

The corresponding metric of each text classification task is different, as follows:
for CoLA: Matthews Correlation Coefficient
for MNLI (matched or mismatched): Accuracy
for MRPC: Accuracy and F1 score
for QNLI: Accuracy
for QQP: Accuracy and F1 score
for RTE: Accuracy
for SST-2: Accuracy
for STS-B: Pearson Correlation Coefficient and Spearman's_Rank_Correlation_Coefficient
for WNLI: Accuracy
So be sure to align metric with the task
1.3 data preprocessing
-
The preprocessing tool is tokenizer. Tokenizer first tokenizes the input, then converts the tokens into the corresponding token ID in the pre model, and then into the input format required by the model.
-
For the purpose of data preprocessing, we use autotokenizer. From_ The pretrained method instantiates our tokenizer to ensure that:
- We get a tokenizer corresponding to the pre training model one by one.
- When using the tokenizer corresponding to the specified model checkpoint, we also downloaded the thesaurus vocabulary required by the model, which is exactly tokens vocabulary.
The downloaded tokens volatile will be cached so that they will not be downloaded again when they are used again.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True) #use_fast=True requires tokenizer to be of type transformers.PreTrainedTokenizerFast

-
Because some special features of fast tokenizer (such as multi-threaded fast tokenizer) need to be used in preprocessing, use_fast=True requires tokenizer to be of type transformers.PreTrainedTokenizerFast. If the corresponding model does not have a fast tokenizer, remove this option.
-
Tokenizer can preprocess either a single text or a pair of text. The data obtained by tokenizer after preprocessing meets the input format of pre training model
tokenizer("Hello, this one sentence!", "And this sentence goes with it.")
{'input_ids': [101, 7592, 1010, 2023, 2028, 6251, 999, 102, 1998, 2023, 6251, 3632, 2007, 2009, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
- In order to preprocess our data, we need to know different data and corresponding data formats, so we define the following dict.
task_to_keys = {
"cola": ("sentence", None),
"mnli": ("premise", "hypothesis"),
"mnli-mm": ("premise", "hypothesis"),
"mrpc": ("sentence1", "sentence2"),
"qnli": ("question", "sentence"),
"qqp": ("question1", "question2"),
"rte": ("sentence1", "sentence2"),
"sst2": ("sentence", None),
"stsb": ("sentence1", "sentence2"),
"wnli": ("sentence1", "sentence2"),
}
#Data format check
sentence1_key, sentence2_key = task_to_keys[task]
if sentence2_key is None:
print(f"Sentence: {dataset['train'][0][sentence1_key]}")
else:
print(f"Sentence 1: {dataset['train'][0][sentence1_key]}")
print(f"Sentence 2: {dataset['train'][0][sentence2_key]}")
Sentence: Our friends won't buy this analysis, let alone the next one we propose.
#Put the preprocessed code into a function:
def preprocess_function(examples):
if sentence2_key is None:
return tokenizer(examples[sentence1_key], truncation=True)
return tokenizer(examples[sentence1_key], examples[sentence2_key], truncation=True)
- The preprocessing function can process a single sample or multiple samples. If the input is multiple samples, a list is returned
preprocess_function(dataset['train'][:5])
{'input_ids': [[101, 2256, 2814, 2180, 1005, 1056, 4965, 2023, 4106, 1010, 2292, 2894, 1996, 2279, 2028, 2057, 16599, 1012, 102], [101, 2028, 2062, 18404, 2236, 3989, 1998, 1045, 1005, 1049, 3228, 2039, 1012, 102], [101, 2028, 2062, 18404, 2236, 3989, 2030, 1045, 1005, 1049, 3228, 2039, 1012, 102], [101, 1996, 2062, 2057, 2817, 16025, 1010, 1996, 13675, 16103, 2121, 2027, 2131, 1012, 102], [101, 2154, 2011, 2154, 1996, 8866, 2024, 2893, 14163, 8024, 3771, 1012, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
- Preprocess all samples in the dataset datasets by using the map function to prepare the preprocessing function_ train_ Features are applied to all samples.
encoded_dataset = dataset.map(preprocess_function, batched=True)

1.4 fine tuning the pre training model
- Use the AutoModelForSequenceClassification class. Similar to tokenizer, the from_trained method can also help us download and load models
STS-B is a regression problem, and MNLI is a 3 classification problem:
#The model is cached
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
num_labels = 3 if task.startswith("mnli") else 1 if task=="stsb" else 2
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
- In order to get a Trainer training tool, we also need three elements, the most important of which is the training setting / parameter TrainingArguments. This training setting contains all the attributes that can define the training process.
metric_name = "pearson" if task == "stsb" else "matthews_correlation" if task == "cola" else "accuracy"
args = TrainingArguments(
"test-glue",
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=5,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model=metric_name,
)
- Define a function to get the evaluation method according to the task name and pass it to Trainer:
def compute_metrics(eval_pred):
predictions, labels = eval_pred
if task != "stsb":
predictions = np.argmax(predictions, axis=1)
else:
predictions = predictions[:, 0]
return metric.compute(predictions=predictions, references=labels)
validation_key = "validation_mismatched" if task == "mnli-mm" else "validation_matched" if task == "mnli" else "validation"
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset[validation_key],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
- Start training:
trainer.train()

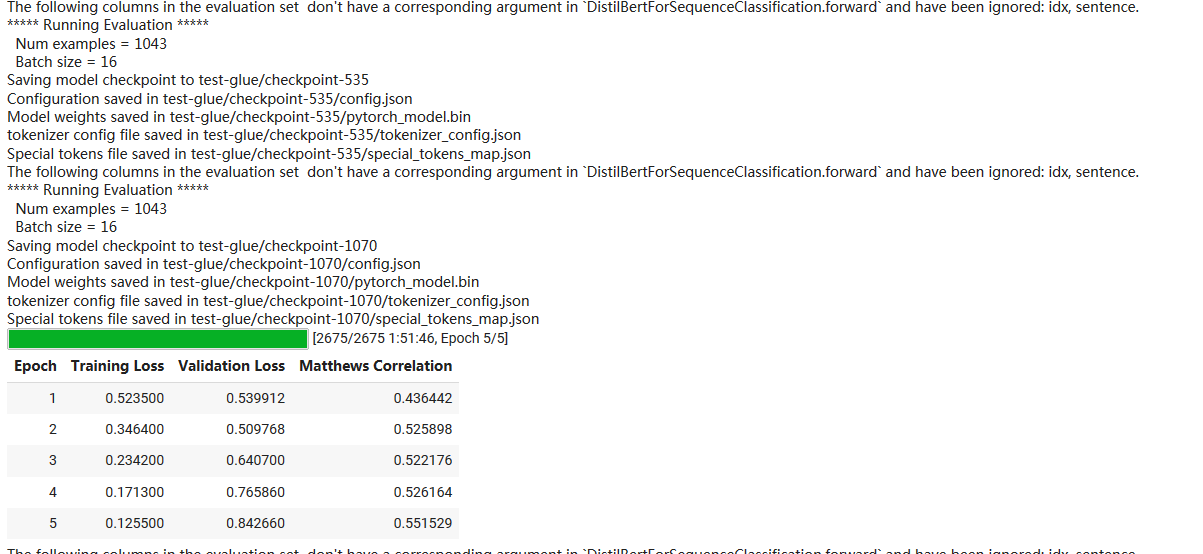
#assessment trainer.evaluate()

1.5 hyper parameter search
-
Trainer also supports hyper parameter search and uses optuna or Ray Tune code base.
-
During hyper parameter search, the Trainer will return multiple trained models, so a defined model needs to be passed in so that the Trainer can continuously reinitialize the passed in model:
-
Call the method hyperparameter_search. Note that this process may take a long time. We can use part of the data set for hyperparameter search first, and then conduct full training. For example, use 1 / 10 of the data for search:
best_run = trainer.hyperparameter_search(n_trials=10, direction="maximize")
hyperparameter_search will return parameters related to the best model:
best_run
- Set trainer as the best parameter found for training:
for n, v in best_run.hyperparameters.items():
setattr(trainer.args, n, v)
trainer.train()