Hash data structure is a very simple and practical data structure. The principle is to pass data through certain hash function rules and store them. Make the time complexity of lookup approximate to O (1). The running time of the program is greatly saved.
The principle of the hash table is shown in the figure.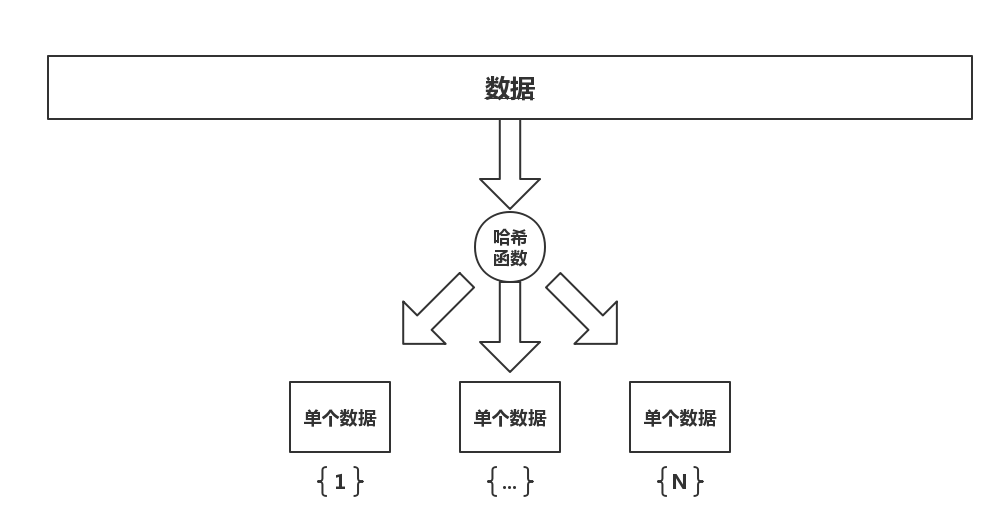
The original data can be stored directly through hash function, so that when searching, each data has its own specific search number, so when searching, it can be found directly through hash function step by step (without considering conflict). So the time complexity is close to O (1).
But the biggest problem of hash function is that there will be conflicts in solving the problem. For example, where 16 and 32 have residuals of 0-7, then 16 goes in first and the residuals of 0, then 32 goes in again is the residuals or 0. How to solve this problem? Two methods are introduced here.
(Open Address) Linear Detection Method
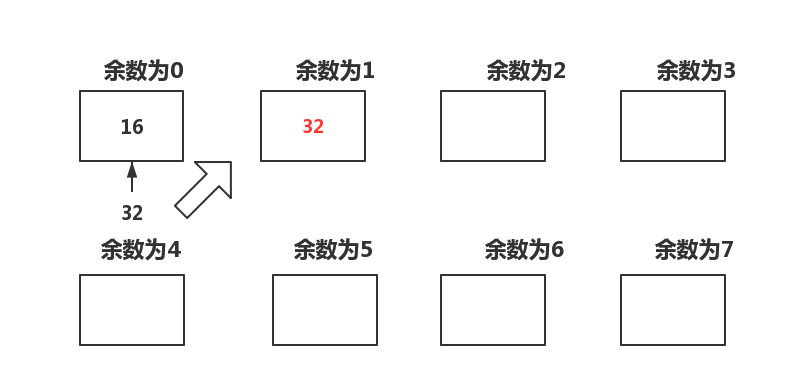
32 should have been placed in the remainder of 0, but where the remainder of 0 already has a number, it should be placed in the remainder of 1. Assuming that 64 is placed next time, 64 will be placed in the remainder of 2, so that 64 can be found three times by the master. The complexity is still much faster than the O (n) of a single linked list. This is represented by code.
header file
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include <stdio.h>
typedef int Key;
typedef enum//A state machine that records the status of data stored in a location
{
EMPTY,//Empty
EXIST,//Data bound
DELETED//Deleted
}State;
typedef struct Element//state
{
Key key;
State state;
}Element;
typedef int(*HashFuncType)(Key key, int capacity);
typedef struct HashTable
{
Element * table;
int size;
int capacity;//capacity
HashFuncType HashFunc;
}HashTable;
int HashSearch(HashTable *pHT, Key key);
void HashDestroy(HashTable *pHT);
void HashInit(HashTable *pHT, int capaicity, HashFuncType HashFunc);
int mod(Key key, int capacity);
void ExpandIfRequired(HashTable *pHT);
int HashInsert(HashTable *pHT, Key key);
int HashRemove(HashTable *pHT, Key key);
A concept of load factor is introduced in the expanding area. Load factor = the number of elements in hash table / the length of hash table. The size is generally defined between 0.7 and 0.8. Over 0.8 will affect the efficiency of hash table. However, increasing the value of load factor can reduce the memory space occupied by hash tables. Conversely, reducing the value of load factor can increase the search efficiency.
Function. c file
#define _CRT_SECURE_NO_WARNINGS 1
#include "Hash.h"
#include <stdio.h>
#include <assert.h>
void HashInit(HashTable *pHT, int capaicity, HashFuncType HashFunc)
{
pHT->table = (Element *)malloc(sizeof(Element)* capaicity);
assert(pHT->table);
pHT->size = 0;
pHT->capacity = capaicity;
pHT->HashFunc = HashFunc;
for (int i = 0; i < capaicity; i++)
{
pHT->table[i].state = EMPTY;
}
}
void HashDestroy(HashTable *pHT)
{
free(pHT->table);
}
int HashSearch(HashTable *pHT, Key key)
{
int index = pHT->HashFunc(key, pHT->capacity);
while (pHT->table[index].state != EMPTY)
{
if (pHT->table[index].key == key&&pHT->table[index].state == EXIST)
{
return index;
}//If the hash table is full, this is a dead loop, but the hash table will not be full.
index = (index + 1) % pHT->capacity;//Easy to return to the first
}
return -1;
}
int mod(Key key, int capacity)
{
return key % capacity;
}
void ExpandIfRequired(HashTable *pHT)
{
int i = 0;
if (pHT->size * 10 / pHT->capacity < 7)//Referring to load factor to ensure that the conflict rate is as low as possible
{
return;
}
/*int newCapacity = pHT->capacity * 2;
Element * newTable = (Element *)malloc(sizeof(Element)* newCapacity);
assert(newTable);
for (i = 0; i < newCapacity; i++)
{
newTable[i].state = EMPTY;
}
free(pHT->table);
pHT->table = newTable;
pHT->capacity = newCapacity;*///Data migration is too cumbersome
HashTable newHT;
HashInit(&newHT, pHT->capacity * 2, pHT->HashFunc);
for (i = 0; i < pHT->capacity; i++)
{
if (pHT->table[i].state == EXIST)
{
HashInsert(&newHT, pHT->table[i].key);
}
}
free(pHT->table);
pHT->table = newHT.table;
pHT->capacity = newHT.capacity;
}
int HashInsert(HashTable *pHT, Key key)
{
ExpandIfRequired(pHT);//Capacity expansion
int index = pHT->HashFunc(key, pHT->capacity);
while (1)
{
if (pHT->table[index].key == key && pHT->table[index].state == EXIST)
{
return -1;
}
if (pHT->table[index].state != EXIST)
{
pHT->table[index].key = key;
pHT->table[index].state = EXIST;
pHT->size++;
return 0;
}
index = (index + 1) % pHT->capacity;
}
}
int HashRemove(HashTable *pHT, Key key)
{
int index = pHT->HashFunc(key, pHT->capacity);
while (pHT->table[index].state != EMPTY)
{
if (pHT->table[index].key == key && pHT->table[index].state == EXIST)
{
pHT->table[index].state = DELETED;
return 0;
}
index = (index + 1) % pHT->capacity;
}
return -1;
}
hash bucket
Hash bucket is a combination of array and linked list to solve the conflict problem of hash function. In principle, as the saying goes, the address of a linked list is stored in the array, 16, put in, 32 in, the remainder is 0, from 16, continue to look until 32 is found. Draw a picture.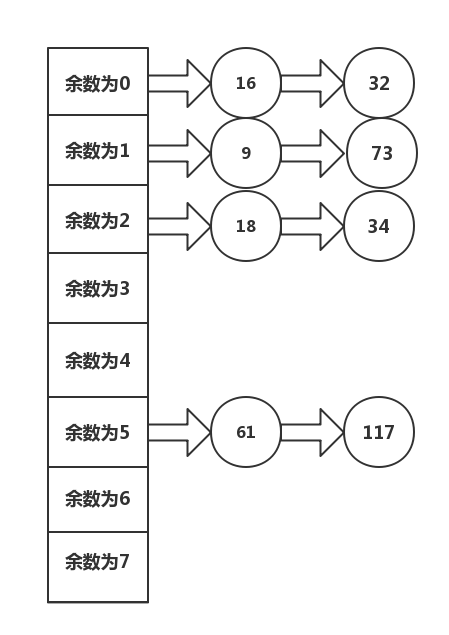
First is the header file.
#define _CRT_SECURE_NO_WARNINGS 1
typedef int Key;
typedef struct Node
{
Key key;
struct Node * Next;
}Node;
typedef struct HashBucket
{
int size;
int capacity;
Node ** array;
}HashBucket;
void HashBucketInit(HashBucket *pHB, int capacity);
void HashBucketDestroy(HashBucket *pHB);
void ListDestroy(Node *first);
Node * HashBucketSearch(HashBucket *pHB, Key key);
void ExpandIfRequired1(HashBucket *pHB);
int HashBucketInsert(HashBucket *pHB, Key key);
int HashBucketRemove(HashBucket *pHB, Key key);
Then the. c file
#define _CRT_SECURE_NO_WARNINGS 1
#include "HashBucket.h"
#include <stdio.h>
#include <stdlib.h>
void HashBucketInit(HashBucket *pHB, int capacity)
{
pHB->array = (Node **)malloc(sizeof(Node *)*capacity);
for (int i = 0; i < capacity; i++) {
pHB->array[i] = NULL; // Empty linked list
}
pHB->capacity = capacity;
pHB->size = 0;
}
void ListDestroy(Node *first)
{
Node *next;
Node *cur;
for (cur = first; cur != NULL; cur = next)
{
next = cur->Next;
free(cur);
}
}
void HashBucketDestroy(HashBucket *pHB)
{
int i = 0;
for (i = 0; i < pHB->capacity; i++)
{
ListDestroy(pHB->array[i]);
}
free(pHB->array);
}
Node * HashBucketSearch(HashBucket *pHB, Key key)
{
int index = key % pHB->capacity;
Node *cur = pHB->array[index];
while(cur != NULL)
{
if (cur->key ==key)
{
return cur;
}
cur = cur->Next;
}
return NULL;
}
void ExpandIfRequired1(HashBucket *pHB)
{
int i = 0;
Node *node;
if (pHB->size < pHB->capacity)
{
return;
}
HashBucket NB;
HashBucketInit(&NB, pHB->capacity * 2);
for (i = 0; i < pHB->capacity; i++)
{
for (node = pHB->array[i]; node != NULL; node = node->Next)
{
HashBucketInsert(&NB, node->key);
}
}
HashBucketDestroy(pHB);
pHB->array = NB.array;
pHB->capacity = NB.capacity;
}
int HashBucketInsert(HashBucket *pHB, Key key)
{
ExpandIfRequired1(pHB);
if (HashBucketSearch(pHB, key) != NULL)
{
return -1;
}
int index = key % pHB->capacity;
Node *first = pHB->array[index];
Node *node = (Node *)malloc(sizeof(Node));
node->key = key;
node->Next = NULL;
first = node->Next;
pHB->array[index] = node;
pHB->size++;
return 0;
}
int HashBucketRemove(HashBucket *pHB, Key key)
{
int index = key % pHB->capacity;
Node *prev = NULL;
Node *cur = pHB->array[index];
while (cur != NULL)
{
if (cur->key == key)
{
if (prev == NULL)
{
pHB->array[index] = cur->Next;
}
else
{
prev->Next = cur->Next;
}
free(cur);
}
prev = cur;
cur = cur->Next;
}
return -1;
}
Hash function for string processing.
The first step is to convert the byte stream into a number
The second step is to hold the number and then use the divisive residue method.
unsigned int RKDR(const char *str)
{
unsigned int seed = 131;//It's a clever way to ensure the sequence of strings.
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return hash & 0x7FFFFFFF;
}
This is my understanding of Hash function. I hope you guys will correct me.