Application scenarios
When we have more than 5 million tables or more, we will consider the use of sub-database sub-tables; when our system is still not satisfied with a cache server, we will use multiple cache servers, then how do we access the back table or cache server, we certainly will not use it. Loop or random, we will use the same hash algorithm to locate the specific location when accessing.
Simple hashing algorithm
We can model a field, such as id, and then scatter the data into different databases or tables.
For example, early planning, we can meet a business data 5 libraries, according to id modelling as follows
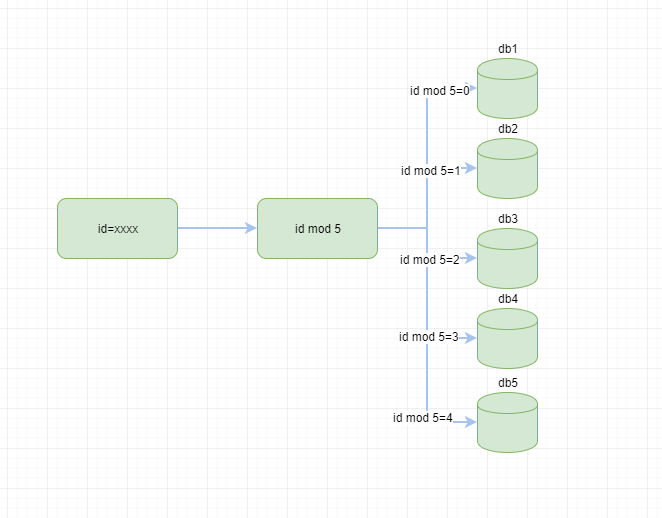
We can easily route to the corresponding library by hash modularization, but the simple hash algorithm mentioned above still has some shortcomings. If five libraries can not meet the needs of business, we need nine libraries, then the original modularization formula mod 5 will become mod 9, and most of the data will be redistributed, involving The workload of data transfer is also huge. Is there a once-for-all solution? The answer is a consistent hash algorithm.
consistent hashing algorithm
Overview of Algorithms
Consistent Hashing, proposed by MIT's karge and his collaborators in academic papers published in 1997, was the earliest in the papers.< Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web > It was proposed. Simply put, consistent hashing organizes the whole hash space into a virtual ring, such as assuming that the value space of a hash function H is 0 - 2 ^ 32 - 1 (that is, the hash value is a 32-bit unsigned shaping). The whole hash space ring is as follows:
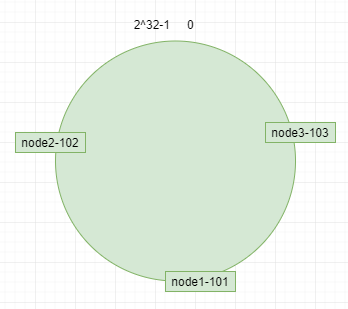
The server (ip or host name) itself hashes to confirm the location of each machine on the hash ring, such as ip: 192.168.4.101, 192.168.4.102, 192.168.4.103 corresponding to node 1-101, node 2-102, node 3-103, as shown in the figure.
The data key uses the same function to calculate the hash value h, and determines the location of the data on the ring according to H. From then on, the location "walks" clockwise along the ring. The nearest server is the server to which it should be located. For example, we use "10", "11", "12", "13", "14" four data objects corresponding to key10,key11, key12, key13, key14. After hashing calculation, the location in the ring space is as follows:
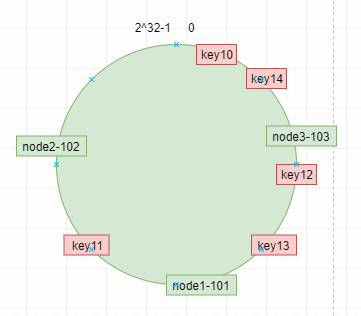
According to the consistency hashing algorithm, data key10, key14 will be located on node 3-103, key12, key13 on node 1-10, and key11 on node 2-102.
Extensibility
Node addition
If we add a new node node node 4-104 corresponding ip: 192.168.4.104, we get the hash value through the corresponding hash algorithm and map it to the ring, as shown below.
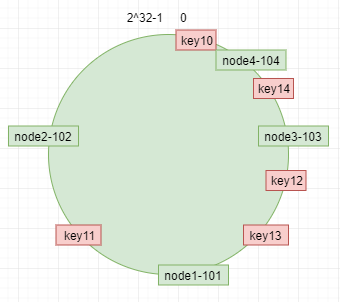
By the rule of clockwise migration, key10 is migrated to node 4-104, and other data remains in its original storage location.
Node deletion
If a node node3-103 is deleted, key10 and key14 will be migrated to node 1-10 clockwise without any changes to other objects. As follows:
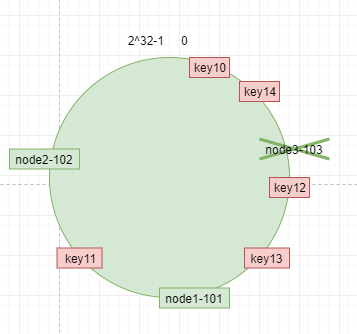
If there are too few service nodes, there will be uneven data distribution. For example, in extreme cases, all data will fall on node 1-101. How to solve the problem of data skew, we need to introduce virtual nodes.
Virtual Node
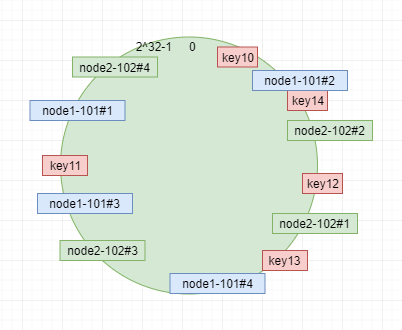
If there are fewer nodes, the data stored by each node will be uneven in the ring formed from 0 to 2 ^ 32-1. Consistency hashing algorithm proposes a solution for virtual nodes. That is to say, when a virtual node is a replica of the actual node (physical machine) in the hash ring, one actual node corresponds to more than N virtual nodes, and the corresponding number becomes the number of replicates. The virtual nodes are arranged in hash ring with hash values.
For example, we delete a point, leaving only the graphs of node 1 and node 2 nodes; we add four virtual nodes, two nodes correspond to eight nodes, and finally the mapping relationship is shown in the figure.

Core code
public class KetamaNodeLocator
{
private SortedList<long, string> ketamaNodes = new SortedList<long, string>();
private HashAlgorithm hashAlg;
private int numReps = 160;
public KetamaNodeLocator(List<string> nodes, int nodeCopies)
{
ketamaNodes = new SortedList<long, string>();
numReps = nodeCopies;
//For all nodes, generate nCopiesFive virtual nodes
foreach (string node in nodes)
{
//Each of the four virtual nodes is a group
for (int i = 0; i < numReps / 4; i++)
{
//getKeyForNodeMethod Gets the unique name for this set of virtual nodes
byte[] digest = HashAlgorithm.computeMd5(node + i);
/** Md5Is a 16An array of byte lengths, which will be 16The array of bytes is set in groups of four bytes, corresponding to one virtual node, which is why the virtual nodes are divided into four groups.*/
for (int h = 0; h < 4; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes[m] = node;
}
}
}
}
public string GetPrimary(string k)
{
byte[] digest = HashAlgorithm.computeMd5(k);
string rv = GetNodeForKey(HashAlgorithm.hash(digest, 0));
return rv;
}
string GetNodeForKey(long hash)
{
string rv;
long key = hash;
//If this node is found, the node is taken directly and returned.
if (!ketamaNodes.ContainsKey(key))
{
//Get bigger than the present keyThat one Map,Then take the first one out of it. key,It's the one that's bigger and nearest to it. key Detailed explanation: http://www.javaeye.com/topic/684087
var tailMap = from coll in ketamaNodes
where coll.Key > hash
select new { coll.Key };
if (tailMap == null || tailMap.Count() == 0)
key = ketamaNodes.FirstOrDefault().Key;
else
key = tailMap.FirstOrDefault().Key;
}
rv = ketamaNodes[key];
return rv;
}
}
public class HashAlgorithm
{
public static long hash(byte[] digest, int nTime)
{
long rv = ((long)(digest[3 + nTime * 4] & 0xFF) << 24)
| ((long)(digest[2 + nTime * 4] & 0xFF) << 16)
| ((long)(digest[1 + nTime * 4] & 0xFF) << 8)
| ((long)digest[0 + nTime * 4] & 0xFF);
return rv & 0xffffffffL; /* Truncate to 32-bits */
}
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(string k)
{
MD5 md5 = new MD5CryptoServiceProvider();
byte[] keyBytes = md5.ComputeHash(Encoding.UTF8.GetBytes(k));
md5.Clear();
//md5.update(keyBytes);
//return md5.digest();
return keyBytes;
}
Finally, the implementation code is affixed, which can run and run, and deepen understanding. I hope it will be helpful to you. Code words are not easy to ask for more support.