Recently, I have been writing a personal music online playing platform with django. In terms of web page data protection, I have taken many anti crawler measures, so in this article, I analyze the anti crawler and its corresponding cracking skills from the source code and practical operation.
First of all, we declare that there is no difference between crawler and anti crawler, although there is always a way to break through your security protection. The reptile is like a nail, and the back climbing is an iron window. Nails are persistent and can always break the window. But windows can't be made with all their strength just for one point. Since then, repair and mend, generally both sides don't work endlessly. Now I'll write it separately. In this way, people with different hobbies can get what they need.
Anti crawler:
1. I set login authentication and decorator in Django views, get the request header through META.get, and limit the request header and access interval.
lxcsdn = ["https://blog.csdn.net/weixin_43582101/column/info/33034",
"https://blog.csdn.net/weixin_43582101/article/details/86563910",
"https://blog.csdn.net/weixin_43582101/article/details/86567367",
]
'''Set request header and access interval'''
ips = [None] #The empty list of ip addresses accessed by the client for the last time is also a list. The None type has only one value of None
## ips=[None] to prevent list index out of range.
last = 0 #Last access time of storage customer service terminal
def isCraw(func):
def wrapper(*args,**kwargs):
global ips,last #Declare global variables
#request.META is a dictionary that contains all Header information of this HTTP request
agent = args[0].META.get('HTTP_USER_AGENT') #Get request header information
if 'Mozilla' not in agent and 'Safari' not in agent and 'Chrome'not in agent:
return HttpResponse(random.choice(lxcsdn))
else:
ip = args[0].META.get('REMOTE_ADDR') #Client IP address
# What is remote_addr:
# remote_addr is specified by the server according to the ip of the requested TCP packet. Suppose there is no agent between the client and the server,
# Then the web server (Nginx, Apache, etc.) will set the IP of the client to IPremote_addr;
# If there is a proxy forwarding HTTP request, the web server will set the IP of the last proxy server to remote_addr
now = time.time()
if ip==ips[0] and now-last<2: #To prevent accidental injury
return HttpResponse("Are you curious about what happened? If you read this sentence carefully, you will know what happened. so the page is not found , But is you didn't find it ! " )
last = now
ips.pop()
ips.append(ip)
return func(*args,**kwargs)
return wrapper! Remember it's a decorator. Met.get can get the information of the request header. If there is no request header user agent, you can only request a link to my csdn blog. The ip time from the last visit to this visit is recorded at the bottom. If the frequency is less than 2 seconds, it will jump to the error page.
2. Set the cookie and session after successful login, and hide the cookie through url encoding Cookies and session s are necessary for websites, but some crawlers will directly visit your home page without logging in through cookie s to extract data. Because the url encoding method does not support Chinese, we can set cookie s for Chinese and foreign languages. Roughly as follows:
response.set_cookie(getPassword(urlquote("Hello")),getPassword(urlquote("Justice, rule of law and democracy")))
response.set_cookie((urlquote("아니카시유")),(urlquote("아니카시유아니카시유")))The contents displayed on the console are:

This can play a certain degree of anti reptile effect. Of course, you can also use the encrypted data to make it more difficult for the crawler to crack.
3. The login page is automatically refreshed and timed for 30 seconds. In order to prevent the invasion of selenium and non interface browsers, we can only sacrifice a little user experience as much as possible. We control the browser refresh time to about 30 seconds, and the slow non interface browsers will be very uncomfortable. Here I use JS to achieve.
function myrefresh() {
window.location.reload();
}
setTimeout('myrefresh()', 30000);4. It's not enough to set 30 seconds above, so I set the verification code in the login interface, which can also isolate most crawler beginners.
First, I wrote a method to move the mouse into the display picture. Because the user experience and the login of selenium should be considered. Therefore, the label I set is to move the mouse into the outside div to display the pictures inside. Therefore, selenium cannot obtain the properties of the pictures inside.


Click to refresh the verification code: why write this? If the other party triggers the image by clicking, the triggered image may be different from that at the beginning. I haven't tried this. It should be like this.
function refresh(ths)
{ths.src = ths.src + '?'}This is particularly simple to write. You only need to add a url + to the original click method? You can repeat the request. (if the two request URLs are the same, the picture cannot be refreshed)
The following is the code generated by the verification code: (this code is written in the view for the convenience of explanation. If you don't understand it, please leave a message)
def auth_code(request):
size = (143,40)
width,height = size
font_list = list("abcdefghklmpqrstuvwxyz*#%0123456789")
c_chars = " ".join(random.sample(font_list,5))
request.session['auth'] = c_chars.replace(' ','')
img = Image.new("RGB",size,(30,31,42))
draw = ImageDraw.Draw(img)
# for i in range(random.randint(1,7)):
# draw.line(
# [
# (random.randint(0, 150), random.randint(0, 150)),
# (random.randint(0, 150), random.randint(0, 150))
# ],
# fill=(0, 0, 0)
# )
# for j in range(1000):
# draw.point(
# ( random.randint(0, 150),
# random.randint(0, 150)
# ),
# fill = (0, 0, 0)
# )
font = ImageFont.truetype("simsun.ttc", 23)
draw.text((5,4),c_chars,font=font,fill="white")
params = [1 - float(random.randint(1, 2)) / 100,
0,
0,
0,
1 - float(random.randint(1, 10)) / 100,
float(random.randint(1, 2)) / 500,
0.001,
float(random.randint(1, 2)) / 500
]
img = img.transform(size, Image.PERSPECTIVE, params)
img = img.filter(ImageFilter.EDGE_ENHANCE_MORE)
img.save(buf,'png')
return HttpResponse(buf.getvalue(),)5. Because only in this way, I feel that the strength is not enough. The patient selenuim can still be cracked quickly. So I limit PhantomJS and selenium from attributes. This restriction is written in js. ... I just suddenly found that I confused the JS of this page with compression encryption, but I can use it directly.
window.onload=function(){
if (navigator.webdriver) {
eval(function(p,a,c,k,e,d){e=function(c){return(c35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;}('0 1=\'\';',2,2,'var|a'.split('|'),0,{}));
var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';eval(function(p,a,c,k,e,d){e=function(c){return(c35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;}('0 1=\'\';0 1=\'\';0 1=\'\';0 1=\'\';',2,2,'var|a'.split('|'),0,{}));
window.location.href="https://www.hexu0614.com/blog/blogs/12/"}
else if(/HeadlessChrome/.test(window.navigator.userAgent)) {
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
window.location.href="https://www.hexu0614.com/blog/blogs/6/";}
else if(navigator.plugins.length === 0 || !navigator.plugins.length) {
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
window.location.href="https://www.hexu0614.com/blog/blogs/33/";}
else if(navigator.languages === "") {
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
var a = '';var a = '';var a = '';var a = '';var a = '';var a = '';
window.location.href="https://www.hexu0614.com/blog/blogs/5/";}
// {# get picture judgment #}
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "/static/tboys/img/login_ico.png";
image.setAttribute("id", "auth_img");
body.appendChild(image);
image.onerror = function(){
if(image.width === 0 && image.height === 0) {
window.location.href="https://www.hexu0614.com";
}}
};First of all, the box above is that selenium cannot be another character set, which will affect its reading operation and have a restrictive effect. If you add enough, it may crash him. The first if function is to jump the page to another place if the access driver is webdriver. The latter two functions are to judge whether it is an interface free browser by judging the length and language of the access source. The last one is to judge whether it is a non interface browser by identifying the image. Because the width and height of the image obtained by the non interface browser when accessing the image are 0; The language of the browser without interface is empty by default, and the length is 0.5 by default
6. The form post request is set and encrypted and hidden through display:none+hidden This is a common form. I use a lot of display: none and tag hiding to interfere with the crawler's judgment and control of the page. So as to increase the difficulty of reptiles. And you can arrange the next honeypot for the reptile to enter the wrong path step by step without knowing

7. Save the music link data of the home page in. JS, and the JS file is compressed and encrypted. Suppose the other party cracked the verification and logged in to the home page. It is also difficult to find the data he needs. There is no url information in the page information.

My url is as follows:
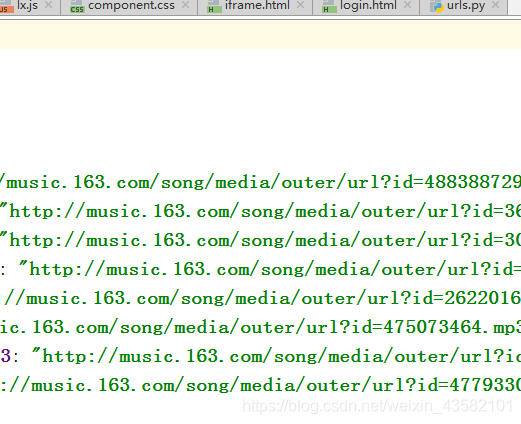
Since my data has not been updated, JS encryption is not used here. When you want to encrypt JS, you can go to the following figure
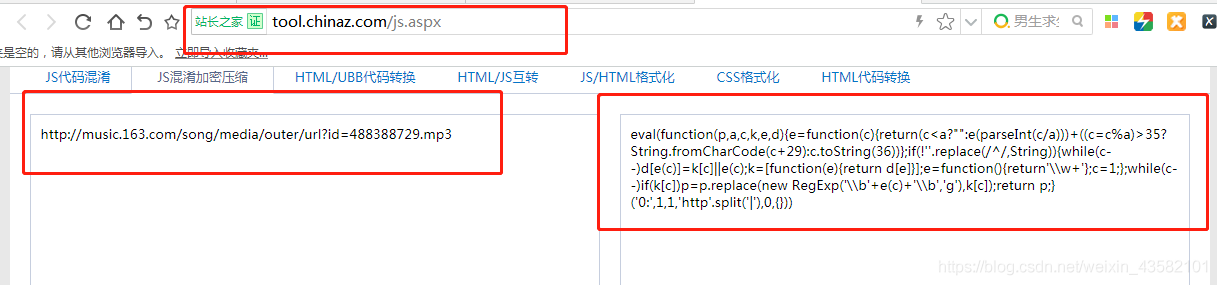
Or find a reliable one, because sometimes after encryption, the function will be encrypted. We should try and encrypt at the same time.
8. Set iframe. The iframe element creates an inline frame (that is, an inline frame) that contains another document The effect is this.
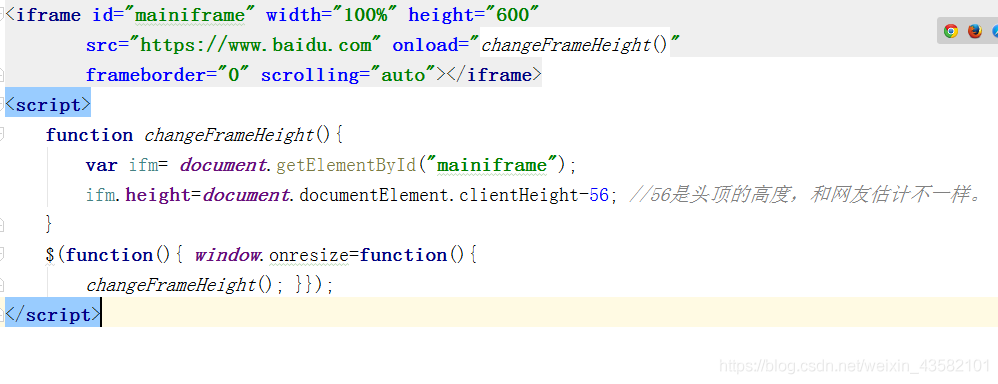
Page:
The console displays as follows:
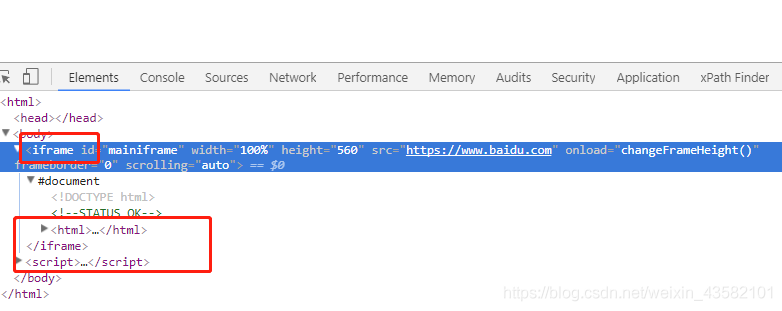
You can use multiple iframe s to interfere with the crawler's perspective and hide your url.

9. A css method that is more uncomfortable is to change the difference between page information and source information through character set mapping. Use the front-end font file (. ttf) to confuse text to prevent crawlers from crawling website data. I won't introduce this in detail. Give a few columns, you can search the Internet for specific operations.
- 1 FONT-FACE patchwork
- 2 BACKGROUND patchwork
- 3 character interleaved
- 4 pseudo element hidden
- 5 element positioning overlay
- 6 IFRAME asynchronous loading
- 7 character split
- 8 character set substitution


Does it look exciting. You can use the fontcreator tool to build your own fonts, and then import custom fonts on the html page.
There's something else I forgot about.. Not yet. Let's crack the anti climbing measures one by one.
Anti crawler:
1. Submit the corresponding data according to the formdata data in the form. 2. Careful, careful, careful 3. Decryption via urldncode 4. The verification code is processed through image recognition, coding platform, or software tools 5. JS data cleaning and data decryption. 6. Change the frequency and content of our requests according to the restrictions set by the website. 7. Use fontcreator to find out the encryption law of character set. 8. Use the headless browser to change his properties one by one Forget it. There are too many anti climbing strategies. Generally, it is everywhere on the Internet. Just wait until you get there.