In this chapter, we will take the picture crawler as an example to explain how to implement the picture crawler project through the Scrapy framework.
Review with urlib handwritten crawler:
Previously, in actual combat, urlib was used to handwrite the picture information of crawling JD mobile phone. Here I'll write a simple keyword climbing area Baidu image search for the first page of the image. 1. Install requests

2. Get Baidu image search url information



Through observation, we can find the URL of Baidu image search page If the keyword is LOL, word=LOL Copy it http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=LOL We need to make changes. Change index to flip
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+word+""
3. Code.
First import the module you want to use
import requests import os import re
Generate a directory.
word=input("Please enter the picture you want to download:")
if not os.path.exists(word):
os.mkdir(word)Reconstruct url
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+word+""
Obtain information for data download and saving
r=requests.get(url)
ret=r.content.decode()
result=re.findall('"objURL":"(.*?)",',ret)
for i in result:
end=re.search('(.jpg|.png|.gif|.jpeg)$',i)#Determine whether to end in this format
if end == None:
i=i+'.jpg'
try:
with open(word+'/%s'%i[-10:],'ab') as f:
img=requests.get(i,timeout=3)
f.write(img.content)
except Exception as e:
print(e)4. Run our crawler file
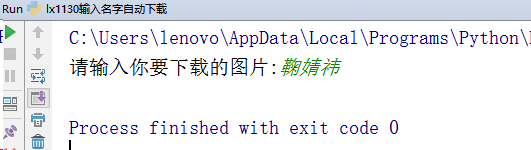
We can go to the current directory to view an additional directory named Ju Jingyi.
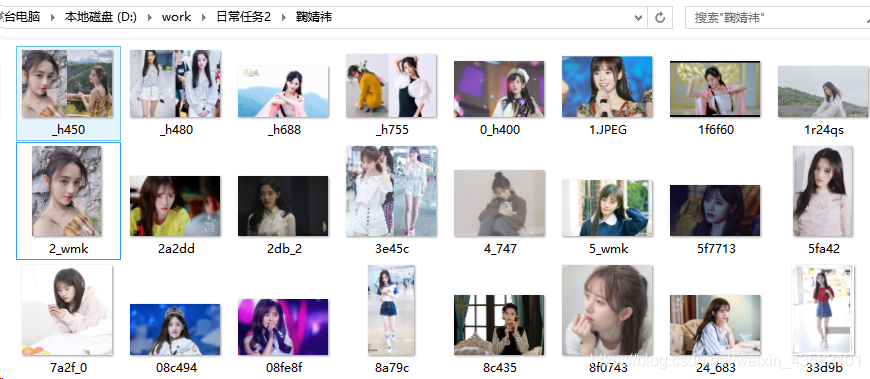
okay. Is it convenient and practical
The complete code is as follows:
import requests
import os
import re
word=input("Please enter the picture you want to download:")
if not os.path.exists(word):
os.mkdir(word)
url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+word+""
#http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=LOL
#Change index to flip
r=requests.get(url)
ret=r.content.decode()
result=re.findall('"objURL":"(.*?)",',ret)
for i in result:
end=re.search('(.jpg|.png|.gif|.jpeg)$',i)#Determine whether to end in this format
if end == None:
i=i+'.jpg'
try:
with open(word+'/%s'%i[-10:],'ab') as f:
img=requests.get(i,timeout=3)
f.write(img.content)
except Exception as e:
print(e)Analysis on functions and ideas of image crawler project:
Next, I'll explain how to implement the image crawler project through the Scrapy framework.
- Sometimes we need to analyze or refer to some pictures on the Internet. We can crawl these pictures to local storage, which will be more convenient to use.
- Suppose we need to do a picture design of a commodity and need to refer to some materials on the Internet. At this time, it will be troublesome to manually open the web page. We can use the crawler to save all the material pictures for local use.
The content of this chapter is the material to realize crawling thousand map network The functions to be realized include:
- 1. Get all the picture materials under the Taobao design column in qiantu.com
- 2. Save the original picture material to the corresponding local directory
In order to improve the efficiency of project development and avoid confusion in the process of project development, we need to clarify the implementation ideas and steps of the project before project development. The implementation idea and steps are as follows:
- 1. Analyze the web page to be crawled, find the law of the content to be obtained, and summarize the format of extracting the corresponding data. Summarize the methods of automatic crawler pages
- 2. Create a Scrapy crawler project
- 3. Prepare the corresponding documents of the project items.py,pipelines.py , settings.py
- 4. Create and write crawler files in the project to crawl all the original pictures (not thumbnails) of the current list page and automatically crawl each picture list page
Photo crawler project preparation practice
First, we need to analyze the crawled web pages. Open the first page to crawl: http://www.58pic.com/tb We will analyze how to extract the URL addresses of all materials in the page At this point, we use one of the pictures in the page as an example to summarize the relevant rules, such as "Taobao essence olive oil skin care promotion poster W". View its source code You can find the corresponding picture website: http://www.58pic.con/taobao/22927027.html The thumbnail address of the corresponding picture is: http://pip.qiantucdn.com/58pic/22/92/70/27p58PIC2hw.jpg!qtwebp226 We created a crawler project called qtpjt

Then it writes its corresponding crawler file Add items.py The key parts of the document are revised as follows:

import scrapy class QtpjtItem(scrapy.Item): #define the fields for your item here like: #name = scrapy.Field() picurl = scrapy.Field() #Create picurl to store picture URL picid = scrapy.Field() #Create picid to store the user name in the picture URL
After writing the items.py file, we need to write the pipelines.py file, and modify the pipelines.py file as follows:
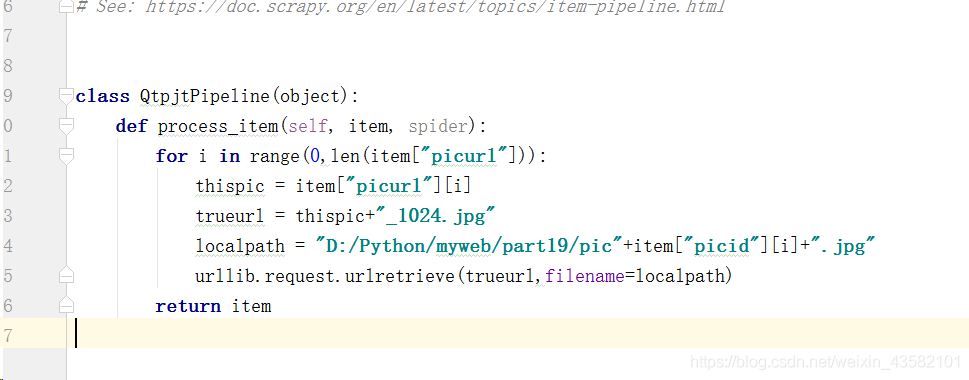
import urllib.request
class QtpjtPipeline(object):
def process_item(self, item, spider):
for i in range(0,len(item["picurl"])):
thispic = item["picurl"][i]
#According to the rules summarized above, the URL address of the original image is constructed
trueurl = thispic+"_1024.jpg"
#Construct the address where the picture is stored locally
localpath = "D:/Python/myweb/part19/pic"+item["picid"][i]+".jpg"
urllib.request.urlretrieve(trueurl,filename=localpath)
return itemThen modify the configuration file settings.py We modify the configuration file as follows:
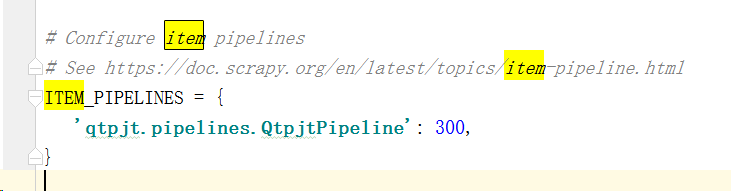
Next, we need to create a corresponding crawler in the crawler project, as shown below

At this point, a crawler named qtspd is created based on the basic template
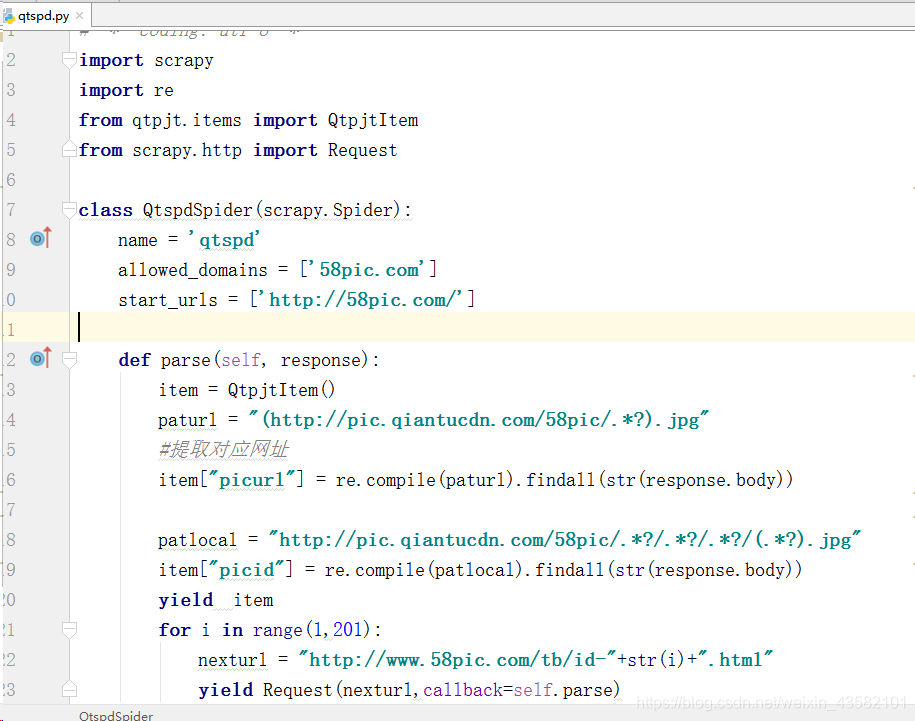
We need to write the crawler file qtspd.py
# -*- coding: utf-8 -*-
import scrapy
import re
from qtpjt.items import QtpjtItem
from scrapy.http import Request
class QtspdSpider(scrapy.Spider):
name = 'qtspd'
allowed_domains = ['58pic.com']
start_urls = ['http://58pic.com/']
def parse(self, response):
item = QtpjtItem()
paturl = "(http://pic.qiantucdn.com/58pic/.*?).jpg"
#Extract the corresponding web address
item["picurl"] = re.compile(paturl).findall(str(response.body))
patlocal = "http://pic.qiantucdn.com/58pic/.*?/.*?/.*?/(.*?).jpg"
item["picid"] = re.compile(patlocal).findall(str(response.body))
yield item
for i in range(1,201):
nexturl = "http://www.58pic.com/tb/id-"+str(i)+".html"
yield Request(nexturl,callback=self.parse)Commissioning and operation:
